
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- cnn
- 머신러닝
- Computer Vision
- 파이썬
- transformer
- Self-supervised
- ViT
- 논문리뷰
- opencv
- 파이토치
- optimizer
- pytorch
- 코드구현
- programmers
- object detection
- Ai
- Paper Review
- 프로그래머스
- 인공지능
- Semantic Segmentation
- 옵티마이저
- 코딩테스트
- Convolution
- 논문 리뷰
- 논문
- Segmentation
- 논문구현
- Python
- 딥러닝
- 알고리즘
- Today
- Total
Attention please
[딥러닝] Batch Normalization (배치정규화) 본문
2022.10.01 - [딥러닝] - LeCun / Xavier / He 초기값 설정 - 표현력 제한, vanishing gradient문제 보완
LeCun / Xavier / He 초기값 설정 - 표현력 제한, vanishing gradient문제 보완
2022.09.30 - [딥러닝] - 옵티마이저(optimizer) - Adam 옵티마이저(optimizer) - Adam 2022.09.30 - [딥러닝] - 옵티마이저(optimizer) - RMSProp 옵티마이저(optimizer) - RMSProp 2022.09.30 - [딥러닝] - 옵티..
smcho1201.tistory.com
이전 글에서는 표현력 제한과 vanishing gradient문제를 보완하기 위해
초기값을 어떻게 설정해야 하는지에 대해 알아보았습니다.
이번 글에서는 딥러닝 모델에서 아주 빈번하게 쓰이는
Batch Normalization층에 대해 알아보겠습니다.
장점
우선 왜 Batch Normalization층을 사용해야 되는지
어떤 것들이 개선되는 지 알아보겠습니다.
1. 학습속도 개선
데이터를 한번 정규화 해줌으로써 학습속도가 개선되게 됩니다.
2. 초기값에 덜 의존
학습이 계속 진행되면서 Batch Normalization 층에서
데이터들의 평균과 표준편차를 더 효율적으로 재설정 해주기 때문입니다.
3. overfitting 억제
과적합(overfitting)을 억제하는 역할을 합니다.
원리
Batch Normalization 층이 해주는 것은
각 열의 평균을 0, 표준편차를 1로 만들어주는 것입니다.
어떤 식으로 계산이 되는지 밑에서 살펴보겠습니다.
데이터(1batch)
피처 개수가 D개이며, 1Batch에 N개의 데이터가 있다고 가정을 하면,
하나의 배치묶음은 NxD행렬이 됩니다.

평균(mean)
위 데이터 X 에 대해서 각 열에 대해 평균을 구하게 되면,
길이가 D인 벡터가 나옵니다.

평균(mean) = 0
그 후 원래 데이터인 X에서 위에서 각 열의 평균값들을 빼주면
데이터 X의 각 열의 평균이 0인 NxD행렬이 완성됩니다.

분산
데이터 X의 각 열에 대해 분산을 구하여,
길이가 D인 벡터를 만듭니다.
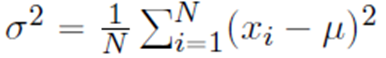
Normalization
위에서 평균을 0으로 만들어주었던 NxD행렬에서,
표준편차를 나누어 표준편차를 1로 만들어줍니다.

lambda, beta
람다와 베타는 하이퍼 파라미터가 아닌
기계가 학습을 함과 동시에 보다 최적화된 값으로 업데이트가 됩니다.
$$ x_{c} \gamma + \beta $$
Batch Normalization은 하나의 층이기 때문에
Affine층과 relu층 사이에 들어가 데이터를 계속 정규화 해줍니다.
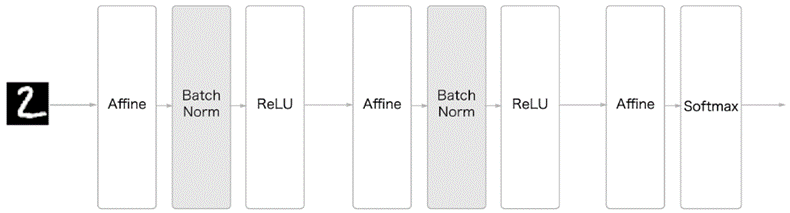
위 그림처럼 Batch Norm 층을 더해주는 것만으로도
좋은 학습 효과를 기대할 수 있습니다.
'딥러닝 > DNN' 카테고리의 다른 글
| [딥러닝] Regularization(Weight Decay, Dropout) - overfitting(과적합) 억제 (2) | 2022.10.30 |
|---|---|
| [딥러닝] LeCun / Xavier / He 초기값 설정 - 표현력 제한, vanishing gradient문제 보완 (4) | 2022.10.01 |
| [딥러닝] 옵티마이저(optimizer) - Adam (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - RMSProp (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - AdaGrad (0) | 2022.09.30 |



