
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Computer Vision
- 코딩테스트
- 논문리뷰
- 딥러닝
- 파이토치
- cnn
- 논문구현
- 알고리즘
- 옵티마이저
- pytorch
- 프로그래머스
- optimizer
- Semantic Segmentation
- transformer
- programmers
- Paper Review
- object detection
- Self-supervised
- Ai
- 인공지능
- Segmentation
- Convolution
- 논문 리뷰
- 논문
- ViT
- Python
- 머신러닝
- 코드구현
- opencv
- 파이썬
- Today
- Total
목록머신러닝 (50)
Attention please
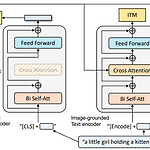 [논문 리뷰] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(2022)
[논문 리뷰] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(2022)
이번에 리뷰할 논문은 BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 입니다. https://paperswithcode.com/paper/blip-bootstrapping-language-image-pre Papers with Code - BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation #3 best model for Open Vocabulary Attribute Detection on OVAD-Box benchmark (mean..
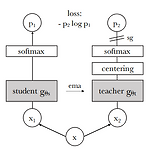 [논문 리뷰] DINO: Emerging Properties in Self-Supervised Vision Transformers(2021)
[논문 리뷰] DINO: Emerging Properties in Self-Supervised Vision Transformers(2021)
이번에 리뷰할 논문은 Emerging Properties in Self-Supervised Vision Transformers 입니다. https://paperswithcode.com/paper/emerging-properties-in-self-supervised-vision Papers with Code - Emerging Properties in Self-Supervised Vision Transformers #2 best model for Visual Place Recognition on Laurel Caverns (Recall@1 metric) paperswithcode.com Introduction ViT(Vision Transformer) 는 최근 CV(Computer Vision) 분야에서 ..
 [논문 리뷰] SimSiam: Exploring Simple Siamese Representation Learning(2021)
[논문 리뷰] SimSiam: Exploring Simple Siamese Representation Learning(2021)
이번에 리뷰할 논문은 Exploring Simple Siamese Representation Learning 입니다. https://paperswithcode.com/paper/exploring-simple-siamese-representation Papers with Code - Exploring Simple Siamese Representation Learning #81 best model for Self-Supervised Image Classification on ImageNet (Top 1 Accuracy metric) paperswithcode.com Intoduction siamese network는 2개 이상의 input에 적용되는 가중치 공유 신경망입니다. 해당 network는 각 ent..
 [논문 리뷰] BYOL: Bootstrap Your Own Latent A New Approach to Self-Supervised Learning(2020)
[논문 리뷰] BYOL: Bootstrap Your Own Latent A New Approach to Self-Supervised Learning(2020)
이번에 리뷰할 논문은 Bootstrap Your Own LatentA New Approach to Self-Supervised Learning 입니다. https://paperswithcode.com/paper/bootstrap-your-own-latent-a-new-approach-to Papers with Code - Bootstrap your own latent: A new approach to self-supervised Learning #2 best model for Self-Supervised Person Re-Identification on SYSU-30k ( Rank-1 metric) paperswithcode.com computer vision 에서 downstream task 에 대해 ..
 [논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Language Supervision(2021)
[논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Language Supervision(2021)
이번에 리뷰할 논문은 Learning Transferable Visual Models From Natural Language Supervision 입니다. https://arxiv.org/abs/2103.00020 Learning Transferable Visual Models From Natural Language Supervision State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional label..
 [논문 리뷰] MoCo: Momentum Contrast for Unsupervised Visual Representation Learning(2020)
[논문 리뷰] MoCo: Momentum Contrast for Unsupervised Visual Representation Learning(2020)
이번에 리뷰할 논문은 Momentum Contrast for Unsupervised Visual Representation Learning 입니다. https://paperswithcode.com/paper/momentum-contrast-for-unsupervised-visual Papers with Code - Momentum Contrast for Unsupervised Visual Representation Learning #11 best model for Contrastive Learning on imagenet-1k (ImageNet Top-1 Accuracy metric) paperswithcode.com 본 포스팅을 이해하기 위해서는 "contrast learning" 의 기본적인 이해가 ..