
- 분류 전체보기 (128)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코드구현
- 머신러닝
- Semantic Segmentation
- 논문리뷰
- 프로그래머스
- 인공지능
- ViT
- Convolution
- object detection
- Segmentation
- pytorch
- 파이썬
- 논문 리뷰
- 코딩테스트
- cnn
- 파이토치
- opencv
- optimizer
- 논문구현
- Ai
- 옵티마이저
- Python
- transformer
- Computer Vision
- 알고리즘
- Self-supervised
- programmers
- 강화학습
- 딥러닝
- 논문
- Today
- Total
Attention please
[딥러닝] 옵티마이저(optimizer) - AdaGrad 본문
2022.09.30 - [딥러닝] - 옵티마이저(optimizer) - NAG
옵티마이저(optimizer) - NAG
2022.09.30 - [딥러닝] - 옵티마이저(optimizer) - Momentum 옵티마이저(optimizer) - Momentum 2022.09.29 - [딥러닝] - 옵티마이저(optimizer) - SGD 옵티마이저(optimizer) - SGD 옵티마이저란 model을 학습..
smcho1201.tistory.com
지금까지 알아보았던 Momentum과 NAG는 기존의 SGD에서
관성을 적용시키는 방식으로 접근을 한 기법이였습니다.
하지만 이번에 알아볼 AdaGrad기법은 관성으로 접근하는 것이 아닌
learning rate를 조절하는 것으로 접근하는 기법입니다.
AdaGrad
위 기법은 지금까지의 optimizer기법들과 다르게
일정한 learning rate를 사용하지 않습니다.
Adagrad기법은 변수, 스텝마다 learning rate에 변화를 줍니다.
시간이 지날수록 learning rate는 줄어들게 되는데
큰 변화를 겪은 변수의 learning rate는 대폭 작아지고,
작은 변화를 겪은 변수의 learning rate는 소폭으로 작아집니다.
큰 변화를 겪었다는 것은 최적에 가까워졌다는 뜻이 됩니다.
즉 어느정도 목적지에 가까워졌기에 보폭은 줄여나가는 것입니다.
반대로 작은 변화를 겪었다는 것은 아직 최적에 멀리 있다는 뜻이 되므로
아직 목적지가 멀리 있기에 보폭을 어느정도 큰 상태로 유지하는 것입니다.
수식
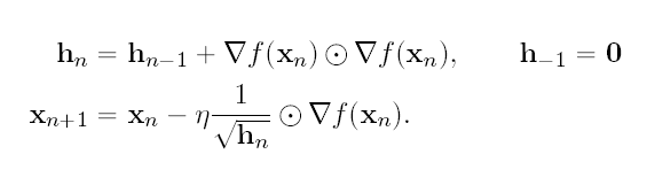
이 수식에서 ⊙은 Hadamard product라는 것인데

이런 식으로 내적을 하는 것이 아닌 같은 위치의 요소와 곱하기를 하는 것입니다.
그리하여 위 수식에서

은 한 걸음의 보폭과 비례합니다.
위 수식이 의미하는 바는 gradient 즉 보폭이 커지면 커질수록
learning rate는 보폭과 비례한 h(n)이 역수로 곱해져있기에 점점 작아진다.
코드구현
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
AdaGrad는 위와 같이 코드로 구현할 수 있다.
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
위 코드는 초기 위치 즉 처음 시작할 때 h값을
0으로 지정함을 의미한다.
밑의 코드는 위의 수식을 코드화 한 것인데
마지막에 1e-7은 np.sqrt(self.h[key])가 0이 되면 분모값이 0이 되기에
오류가 나는 것을 방지하기 위해 넣어준 코드입니다.
'딥러닝 > Neural Network' 카테고리의 다른 글
| [딥러닝] 옵티마이저(optimizer) - Adam (0) | 2022.09.30 |
|---|---|
| [딥러닝] 옵티마이저(optimizer) - RMSProp (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - NAG (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - Momentum (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - SGD (2) | 2022.09.29 |



