
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- cnn
- opencv
- Python
- 논문
- 강화학습
- Convolution
- 옵티마이저
- object detection
- Segmentation
- transformer
- optimizer
- 파이토치
- Self-supervised
- 코딩테스트
- 논문구현
- 알고리즘
- 딥러닝
- 파이썬
- Semantic Segmentation
- 코드구현
- Ai
- Computer Vision
- programmers
- 인공지능
- 논문리뷰
- 논문 리뷰
- pytorch
- 머신러닝
- 프로그래머스
- ViT
- Today
- Total
Attention please
[논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Language Supervision(2021) 본문
[논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Language Supervision(2021)
Seongmin.C 2023. 8. 2. 04:12이번에 리뷰할 논문은 Learning Transferable Visual Models From Natural Language Supervision 입니다.
https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual co
arxiv.org
본 논문에서 제안하는 CLIP(Contrastive Language-Image Pre-training) 모델은 대표적인 Image captioning 모델 중 하나입니다. 또한 zero-shot learning 을 통해 아주 다양한 데이터셋에 대해 좋은 performance를 보여준 논문이기도 하죠.
Motivation
지금까지의 대부분의 NLP 분야의 경우 raw text에서 직접 학습하여 pre-training 하는 방식이 이어져왔습니다. 보통 text-to-text 로 표준화된 input-output interface의 개발로 특정 task를 위한 architecture가 형성되었기 때문에 downstream datasets에 대한 zero-shot learning을 가능하게 해주었습니다. 하지만 Computer Vision 분야에서는 아직도 ImageNet과 같은 대중적인 labeling dataset에서 모델을 pre-training 하는 것이 일반적입니다.
NLP의 경우 web 규모의 대규모 데이터셋을 사용해서 학습하는 것이 가능합니다. 따로 라벨링 작업이 크게 필요하지 않기 때문이죠. 그에 반해 Computer Vision의 경우 image에 대한 labeling 작업이 필수이기 때문에 시간 비용이 크다는 어려움이 있었습니다.
본 논문의 저자는 이런 NLP의 특징인 web text를 직접 활용하여 computer vision에서도 zero-shot learning과 같이 유사한 방식의 pre-train이 가능하지 않을까? 라고 질문을 던지게 됩니다. 이것이 바로 Image captioning 모델인 CLIP 이 탄생하게 된 중요한 동기가 되었습니다. 즉, image와 함께 제공되는 text 정보를 활용하여 image의 의미를 이해하려는 방향으로 시도를 하는 것이죠.
Large Datasets
위에서 언급했듯 zero shot learning을 하기 위해서는 많은 양의 데이터셋이 필요합니다. NLP의 경우 web의 text data들을 사용할 수 있기에 유리한 면이 있었지만 Computer Vision의 경우 labeling 된 image dataset을 사용해야하기 때문에 어려움이 존재했습니다. 보통 quality가 좋은 MS-COCO 나 YFCC100M 과 같은 데이터셋들은 기본적으로 양이 많지 않았습니다.
본 논문에서는 보다 충분한 양의 데이터셋을 수집하기 위해서 인터넷 상의 다양한 text, image 쌍의 데이터들을 수집했다고 언급합니다. 따로 해당 데이터의 출처를 말해주진 않았지만 web에서 수집한 데이터이니만큼 quality는 떨어질지언정 양은 충분할 것으로 보입니다.
CLIP: Contrastive Language-Image Pre-training
CLIP 모델은 기본적으로 contrast learning을 사용하여 학습이 진행됩니다. 만약 contrast learning에 대해 처음 접하신다면 다음 포스팅을 보고 기본적인 contrast learing의 개념을 이해하고 보시는 것을 추천드립니다.
- [논문 리뷰] simCLR : A Simple Framework for Contrastive Learning of Visual Representations(2020)
- [논문 리뷰] MoCo: Momentum Contrast for Unsupervised Visual Representation Learning(2020)
일반적으로 contrast learing의 경우 같은 image를 서로 다른 augmentation을 적용하여 positive pair를 형성한 후 positive pair와의 유사도를 증가시키는 방향으로 학습을 진행시키는 것을 의미합니다. 하지만 본 논문에서 다루는 CLIP의 경우 image가 들어왔을 때 text로 해당 image를 표현하는 것을 목표로 진행됩니다. 그렇기에 pair를 구성하는 것 역시 image와 해당 image를 설명하는 text 즉, caption이 되는 것이죠.

먼저 image와 text에 대해 병렬적으로 encoding을 수행합니다. text encoder의 경우 GPT 스타일의 Transformer를 사용했다고 합니다. image encoder의 경우 총 8가지 모델에 대해 실험을 진행합니다. 우선 ResNet 기반인 ResNet-50, ResNet-101, RN50x4, RN50x16, RN50x64 과 3개의 Vision transformer인 ViT-B/32, ViT-B/16, ViT-L/14 를 모두 비교하여 실험을 진행하였고 가장 최적의 성능이 나온 ViT-L/14를 채택하여 Image Encoder로 사용하게 됩니다.
각 Encoder들은 image와 text를 N차원의 vector로 변환합니다. 이렇게 되면 총 N개의 positive pair가 형성되고, N^2 - N 개의 negative pair가 형성되겠죠. pair를 형성한 후에는 각 pair끼리 cosine similarity를 구합니다. 그 후에는 positive pair간의 유사도가 커지는 방향으로 학습이 진행됩니다. 본 논문에서 사용한 loss function은 InfoNCE loss를 사용하였습니다. 이는 softmax 형태의 loss 함수이며, positive pair의 유사도가 커질수록 해당 loss 값은 작아지게 됩니다.
contrast learning을 하는 알고리즘에 대해서는 다음과 같이 pseudo code로 제공되었으니 참고해주시기 바랍니다.

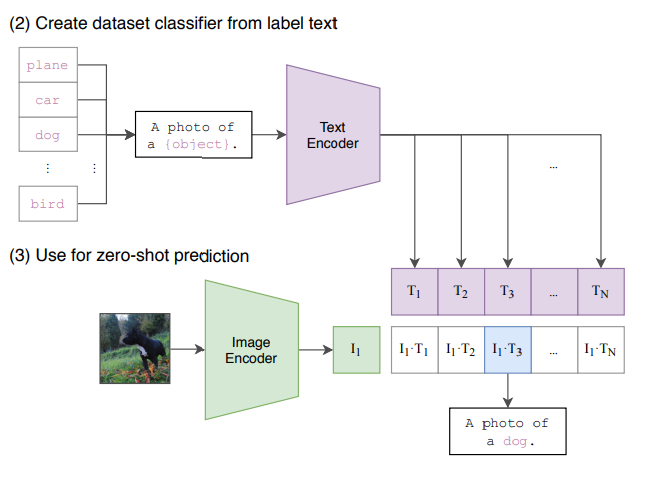
학습이 모두 끝났다면 위 그림과 같이 예측을 진행합니다. 기본적으로 CLIP은 decoder가 존재하지 않으며, text를 생성하는 모델이 아닙니다. 그렇기에 새로운 image 데이터가 들어왔을 때 학습된 Image Encoder에 입력하여 나온 vector를 단순히 text embedding 중에서 가장 유사한 것을 선택하여 출력하는 식으로 진행됩니다. 학습할 때 사용되었던 text datasets 내에서만 text를 출력할 수 있다는 것이죠. 물론 본 논문에서는 방대한 web-datasets을 사용했기 때문에 일반화하는데에 무리가 없었음을 보여줍니다.
Experiments

위 그림을 보면 CLIP 모델이 다른 모델들에 비해 효율이 좋은 것을 확인할 수 있습니다. CLIP은 기본적으로 zero-shot learning을 위해 제안된 모델이기에 효율성에 큰 비중을 차지합니다. 다른 downstream task에 적용되기 위해 일반화되기 위해 대규모 데이터셋으로 학습되어야합니다. 그렇기에 보다 더 효율이 좋은 CLIP 모델의 zero-shot accuracy 수치가 효율적으로 가장 좋은 모습을 보여줍니다.

CLIP은 ResNet-50과 비교했을 때 27개의 datasets 중에서 16개의 datasets 이 더 좋은 performance를 보여준다고 합니다. 이를 통해 zero-shot learning이 잘 수행되었음을 확인할 수 있습니다.



