| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ViT
- 강화학습
- 코딩테스트
- 알고리즘
- Segmentation
- Self-supervised
- pytorch
- transformer
- object detection
- 파이썬
- 파이토치
- opencv
- optimizer
- cnn
- 논문
- 머신러닝
- 논문 리뷰
- 프로그래머스
- Ai
- 논문리뷰
- programmers
- Computer Vision
- Semantic Segmentation
- 인공지능
- 논문구현
- Python
- Convolution
- 딥러닝
- 옵티마이저
- 코드구현
- Today
- Total
Attention please
[논문 리뷰] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(2022) 본문
[논문 리뷰] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(2022)
Seongmin.C 2023. 8. 12. 05:24이번에 리뷰할 논문은 BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 입니다.
https://paperswithcode.com/paper/blip-bootstrapping-language-image-pre
Papers with Code - BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
#3 best model for Open Vocabulary Attribute Detection on OVAD-Box benchmark (mean average precision metric)
paperswithcode.com
Introduction
최근의 Vision-Language pre-training(VLP) 은 다양한 multimodal downstream 에서 성공적인 모습을 보여주었습니다. 하지만 지금까지의 모델들에게는 두가지의 주요한 한계점이 존재했습니다.
- 대부분의 방법론들은 encoder-based model 혹은 encoder-decoder model 을 채택하여 사용하는데 encoder-based model의 경우 text generation task로 직접 transfer 하는 것이 덜 직관적이며, encoder-decoder model의 경우 image-text retrieval task에 좋은 모습을 보여주지 못했습니다.
- 보통 SOTA 방법론들을 보면 web에서 수집한 image-text pairs 데이터셋으로 pre-train을 진행합니다. web에서 수집한 덕에 데이터셋이 확장되었지만, 본 논문에서는 noise가 많은 web text가 vision-language train에 최적이지 않다고 주장합니다.
또한 기존의 vision-language 의 understanding 과 generation 이 따로 수행되었지만, BLIP 은 이 둘을 통합하여 활용한다는 차이점이 존재합니다. 이런 BLIP은 기존의 방법들에 비해 더 넓은 범위의 downstream task에 잘 활용되는 모습을 보여주었죠. 본 논문은 model 과 data 관점의 두가지 contribution을 제시합니다.
Multimodal mixture of Encoder-Decoder(MED)
MED는 다음 총 3가지로 작동될 수 있습니다.
- unimodal encoder
- image-grounded text encoder
- image-grounded text decoder
다음 3가지의 vision-language objectives 와 함께 pre-train이 수행됩니다.
- image-text contrastive learning (ITC)
- image-text matching (ITM)
- image-conditioned language modeling (LM)
Captioning and Filtering (CapFilt)
저자들은 pre-train된 MED를 두 module로 fine-tuning을 진행합니다.
- captioner : 주어진 web image의 synthetic caption 을 생성합니다.
- filter : 원래의 web text와 synthetic text 모두에서 noise가 많은 caption을 제거합니다.
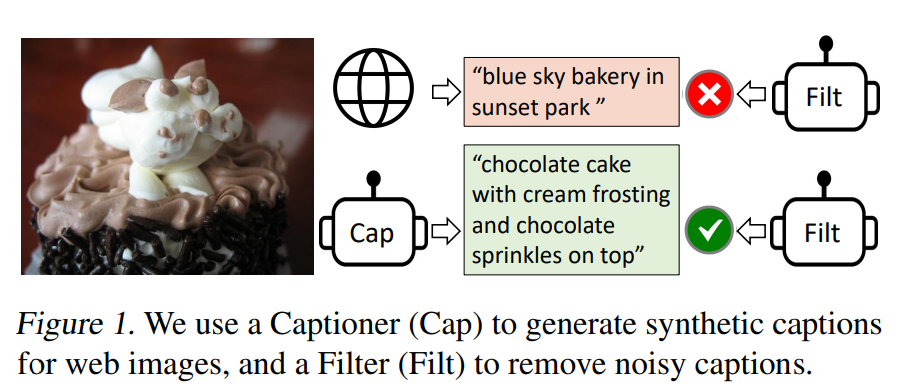
저자들은 광범위한 실험과 분석을 수행하였으며, 다음과 같은 주요 관찰을 보여줍니다.
- captioner 과 filter 를 함께 작동시키는 것은 caption을 bootstrapping 하여 다양한 downstream task에 상당한 성능 향상을 보여줍니다. 또한 다양한 caption은 더 큰 이점을 불러온다고 합니다.
- BLIP은 "image-text retrieval" , "image captioning" , "visual question answering" , "visual reasoning" , "visual dialog" 과 같은 광범위한 vision-language task에서 최첨단 성능을 달성합니다. 또한 text-video retrieval 및 video QA 와 같은 video-text task로 모델을 직접 transfer할 때, 최첨단 zero-show 성능을 달성한다고 합니다.
Method
1. Model Architecture
BLIP 의 전체적인 구조는 다음과 같습니다.
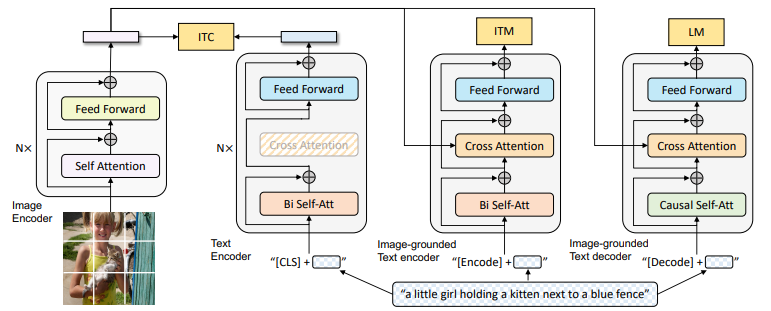
저자들은 image encoder로 visual transformer 를 사용합니다. 또한 [ CLS ] 토큰을 추가하여 global image feature를 표현합니다. ViT의 경우 visual feature extraction을 위해 pre-train된 객체 탐지기를 사용하는 것에 비해 계산 친화적이며, 더 최신 방법을 채택하였다는 의의가 있습니다.
또한 understanding 과 generation 을 모두 갖춘 통합 모델을 pre-train 하기 위해 저자들은 multimodal mixture of encoder-decoder (MED) 를 제안하였으며, 다음 3가지 기능 중 하나로 작동이 가능합니다.
- Unimodal encoder : image와 text를 따로 인코딩을 하며 위에 언급했듯이 image encoder는 ViT모델을 사용하고, text encoder로는 BERT 모델을 사용합니다. 이때 BERT 역시 문장 요약을 위해 input text의 시작부분에 [ CLS ] 토큰을 추가합니다.
- Image-grounded text encoder : self-attention (SA) layer 와 feed forward network (FFN) 사이에 cross-attention (CA) layer를 삽입하여 visual information을 주입합니다. 또한 [ Encode ] 토큰이 text에 추가되는데 해당 토큰의 출력 embedding은 image-text pair의 multimodal representation 으로 사용됩니다.
- Image-grounded text decoder : 위에서 소개한 Image-grounded text encoder의 경우 bidirectional self-attention layer를 사용하는데, Image-grounded text decoder의 경우 대신 causal self-attention layer 를 대체하여 사용합니다. 또한 이 역시 [ Decode ] 토큰을 사용하는데 이는 sequence의 시작 신호로 사용되며, end-of-sequence token (EOS) 는 sequence의 end 신호로 사용됩니다.
2. Pre-training Objectives
pre-training 을 하는 동안 다음 3개의 objectives를 최적화합니다.
- 2개의 understanding-based objectives
- 1개의 generation-based objectives
각 image-text pair 는 계산량이 많은 visual transformer를 통과하는 순방향 통과와 text transformer를 통한 3개의 순방향 통과만을 필요로 합니다.
Image-Text Contrastive Loss (ITC loss)
ITC loss 는 unimodal encoder를 활성화합니다. 이를 위해 이는 visual transformer 와 text transformer 의 feature space를 정렬하는 것을 목표로 합니다. 즉, image와 text의 representation이나 embedding이 공동의 feature space 내에서 의미론적으로 관련되도록 만든다는 것이죠. positive와 negative의 image-text pairs를 대조하여 유사한 representation을 같도록 장려됩니다. 이런 방식은 vision과 language understanding을 향상시키는데 효과적이라고 합니다.
저자들은 momentum encoder와 soft labels와 함께 ITC loss를 따른다고 언급합니다.
- momentum encoder : feature를 생성하기 위해 사용되며, 일반적으로 encoder 중 하나는 실시간으로 업데이트되고 나머지 하나는 업데이트가 더 느린 momentum encoder로 구성하여 collapse를 방지합니다.
- soft labels : negative pairs 내의 잠재적인 positive pairs가 존재할 수 있기에 이를 고려하기 위해 생성됩니다. 이를 통해 훈련 process를 더 flexible하게 만들 수 있습니다.
Image-Text Matching Loss (ITM loss)
ITM loss는 image를 기반으로 한 text encoder를 활성화합니다. 이는 vision과 language 사이의 세밀한 정렬을 포착하는 image-text multimodal representation 을 학습합니다.
ITM은 binary classification task 입니다. 이때 모델이 사용하는 ITM head는 linear layer로 image-text pair가 positive인지 negative 인지 주어진 multimodal feature에 대해 예측을 수행합니다.
Language Modeling Loss (LM loss)
LM loss 는 image를 기반으로 한 text decoder를 활성화합니다. 즉, 주어진 image에 대해 text 설명을 생성하는 것을 목표로 합니다. 모델이 자동 회귀 방식으로 text의 likelihood를 maximize 하도록 훈련시키는 cross-entropy loss를 최적화합니다. VLP task 에서 자주 사용되는 MLM loss와 달리 LM 은 model에 visual information을 일관된 caption으로 변환하는 일반화 능력을 부여해준다는 특징이 있습니다.
text encoder와 text decoder는 self-attention(SA) layer를 제외한 모든 parameter를 공유합니다. 아래 그림에서 색이 같은 모듈은 parameter를 공유한다는 것을 의미합니다.
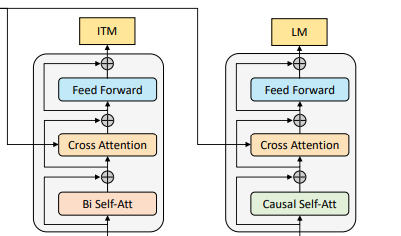
위 그림의 왼쪽이 encoder이고, 오른쪽이 decoder인데 encoder의 경우 bi-directional SA를 사용하기 때문에 현재 input token에 대한 representation을 구축하는데 초점이 맞춰져 있습니다. 반대로 decoder의 경우 causal self-attention을 사용하기 때문에 다음 token을 예측하는데 초점이 맞춰져 있죠. 이와 같이 encoding과 decoding task 간의 차이가 SA-layer에서 가장 잘 나타나는 것을 확인할 수 있습니다.
하지만 embedding layer, CA layer, FFN 기능들의 경우 encoding 과 decoding 이 유사하게 작동하기 때문에 layer를 공유하여 훈련 효율성을 높이면서, multi-task learning 의 이점을 가져갈 수 있습니다.
3. CapFilt
사람이 직접 주석을 단 image-text pairs 데이터셋은 고품질을 가지는 이점이 존재하나 그 수가 제한된다는 한계가 존재합니다. 이에 대해 최근 연구들은 web에서 자동으로 수집한 image-text pairs를 활용하는 식으로 진행하였죠. 하지만 web에서 수집한 text 데이터는 image의 내용을 정확하게 설명하지 않는 경우가 존재합니다. 즉, visual-language 정렬을 학습하는데 있어서 noise가 있는 신호이기 때문에 최적이 아닐 수 있다는 것이죠.
이에 대해 저자들은 Captioning and Filtering (CapFilt) 를 제안합니다. 이름 그대로 총 2개의 모듈로 구성됩니다.
- Captioner : web image에서 caption 생성
- filter : noise가 있는 image-text pairs 제거
CapFilt의 전체적인 과정은 다음과 같습니다.
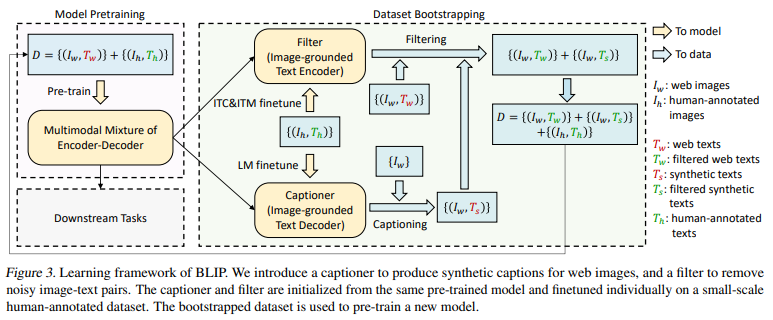
captioner 와 filter 둘다 같은 pre-train MED model 로부터 초기화됩니다. 그 후에 개별적으로 finetuning 되며 이는 경량화된 절차로 볼 수 있습니다. captioner 와 filter에 대해 좀 더 자세하게 설명하자면 다음과 같습니다.
- captioner : MED model의 image-grounded text decoder 입니다. pre-train된 후에 주어진 image의 text를 decoding 하기 위해 LM objective 와 함께 finetuning 됩니다.
- filter : MED model의 image-grounded text encoder 입니다. text와 image가 서로 match하는지 학습하기 위해 ITC 와 ITM objectives 와 함께 finetuning 됩니다.
filter는 original web text인 $ T_{w} $ 와 synthetic text인 $ T_{s} $ 둘 모두에서 noise가 있는 text를 제거합니다. 이때 text는 ITM head가 image와 match되지 않는다고 예측하면, noise가 있다고 고려됩니다. 이렇게 filtering된 image-text pairs와 사람이 주석을 단 pairs를 결합하여 새로운 데이터셋을 형성합니다. 그 후에 결합된 데이터셋을 사용하여 새로운 모델을 pre-train하는데 사용되죠.
간단하게 BLIP의 학습과정은 다음과 같습니다.
- noise가 있는 web data로 training
- 사람이 주석을 단 데이터셋으로 finetuning 하여 CapFilt 학습
- CapFilt 로 noise 제거
- noise가 제거된 web data로 다시 훈련
Experiments and Discussions
1. Pre-training Details
image transformer 는 ImageNet으로 pre-train된 ViT로부터 초기화됩니다. text transformer의 경우 BERT 로부터 초기화된다고 하죠. 본 논문에서는 ViT의 경우 ViT-B/16 과 ViT-L/16 에 대해 실험을 진행합니다. 세부적인 사항은 다음과 같습니다.
- epochs : 20
- batch size : 2880 (ViT-B) / 2400 (ViT-L)
- optimizer : AdamW (weight decay = 0.5)
- learning rate : 3e-4 (ViT-B) / 2e-4 (ViT-L)
- random crop : 224x224 (during pretraining) / 384x384 (during finetuning)
2. Effect of CapFilt
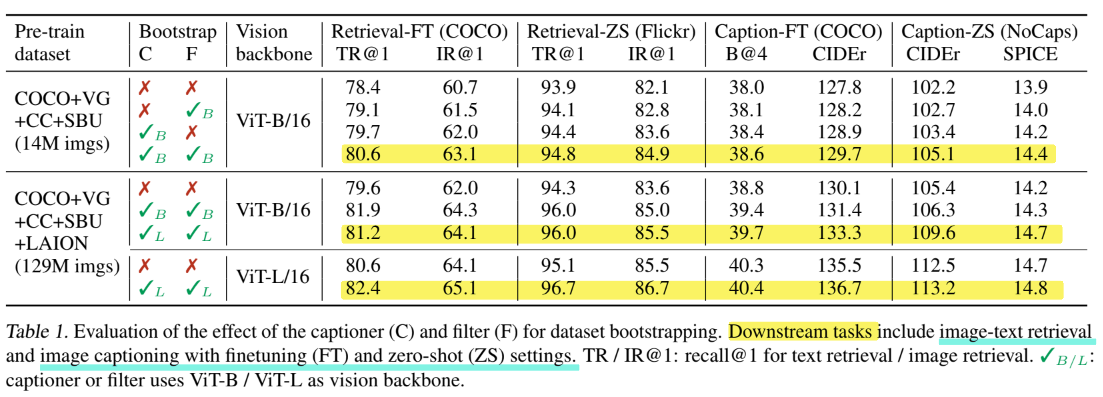
위 표를 보면 downstream 에서 CapFilt 를 사용했을 때와 안했을 때의 성능 차이를 보여줍니다. CapFilt를 사용했을때 즉, captioner 와 filter 를 모두 사용했을 때 가장 성능이 좋은 것을 확인할 수 있습니다.

위 그림을 보면 web text와 synthetic text 에 대해 filtering을 하는 모습을 보여줍니다. 초록색의 경우 filter를 통과한 것이고, 빨간색의 경우 filter를 통과하지 못하여 제거되는 text임을 의미합니다.
3. Diversity is Key for Synthetic Captions
CapFilt 에서는 nucleus sampling 을 사용합니다. 이는 text 생성 작업에서 사용되는 확률적 디코딩 방법 중 하나입니다. 모델의 출력에서 주어진 확률 임계값을 초과하는 단어나 토큰만을 선택하는 방식으로 작동되죠. 모델이 단어를 예측할 때 각 단어의 확률분포를 출력하며, nucleus sampling은 확률분포에서 누적 확률이 특정 임계값(ex. 0.9) 를 초과하는 단어만 고려하는 식으로 진행됩니다.
본 논문에서는 nucleus sampling을 beam search 와 비교하여 실험합니다.

비교 실험한 결과 necleus sampling 한 경우 높은 성능을 보여줍니다. 이에 대해 저자들은 beam sampling에 비해 noise 비율이 큰 nucleus sampling이 더 다양하고 놀라운 caption을 생성한다고 말합니다. 아무래도 noise가 일부 섞여있다보니 생성되는 caption이 보다 flexible 하기에 다음과 같은 결과가 나왔다고 생각해볼 수 있을 것 같습니다.
4. Parameter Sharing and Decoupling
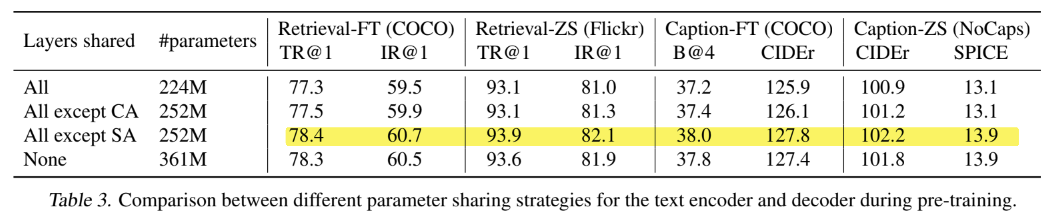
위 표를 보면 parameter 공유를 모든 layer에서 하는 것, CA만 제외, SA만 제외, 미공유 총 4가지의 경우를 비교실험하였고, SA를 제외한 모든 layer에서 parameter를 공유했을 때 가장 좋은 성능을 보여주었습니다. 위 실험의 경우 pre-train에 대한 결과이며, 다음은 fine-tuning 에서의 실험 결과를 보여줍니다.

위 결과를 보면 parameter를 공유했을 때 오히려 성능이 떨어지는 모습을 확인할 수 있습니다. pre-train의 결과와는 상반되는 결과이지요. 저자들은 이에 대한 이유로 confirmation bias 때문이라고 합니다. parameter 공유로 인해 captioner 가 생성한 noise caption은 filter에 걸러질 가능성이 줄어들게 된다는 것이죠. 실제로 위 표를 보면 parameter를 공유했을 때에서 공유하지 않았을 때로 넘어갈 때 noise 비율이 8% 에서 25% 로 증가하는 것을 확인할 수 있습니다.
추가로 BLIP 은 다양한 downstream task에 transfer 될 수 있다고 위에서 언급한 바가 있습니다. 다음 그림은 3가지 downstream task에 대해 적용하는 방식을 그림으로 보여줍니다.