
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 딥러닝
- 코딩테스트
- Paper Review
- Semantic Segmentation
- ViT
- pytorch
- 논문구현
- cnn
- 논문 리뷰
- 코드구현
- 논문
- optimizer
- 머신러닝
- object detection
- 알고리즘
- opencv
- 옵티마이저
- programmers
- Ai
- Computer Vision
- 프로그래머스
- 논문리뷰
- 인공지능
- 파이토치
- transformer
- 파이썬
- Segmentation
- Python
- Self-supervised
- Convolution
- Today
- Total
Attention please
[논문 리뷰] DINO: Emerging Properties in Self-Supervised Vision Transformers(2021) 본문
[논문 리뷰] DINO: Emerging Properties in Self-Supervised Vision Transformers(2021)
Seongmin.C 2023. 8. 11. 04:26이번에 리뷰할 논문은 Emerging Properties in Self-Supervised Vision Transformers 입니다.
https://paperswithcode.com/paper/emerging-properties-in-self-supervised-vision
Papers with Code - Emerging Properties in Self-Supervised Vision Transformers
#2 best model for Visual Place Recognition on Laurel Caverns (Recall@1 metric)
paperswithcode.com
Introduction
ViT(Vision Transformer) 는 최근 CV(Computer Vision) 분야에서 convnet에 비해 더 좋은 성능을 보여주는 경쟁력을 보여주었습니다. 하지만 convnet을 뛰어넘는 명백한 이점을 보여주지 않는다는 한계가 존재했습니다. 오히려 기존 convnet에 비해 계산 비용이 크며, 더 많은 훈련 데이터셋을 필요로 하고, feature에는 독특한 속성이 존재하지 않죠.
ViT는 기본적으로 학습을 할 때 많은 데이터셋을 필요로 하기 때문에 보통 pre-train을 한 후 특정 domain에 맞게 fine tuning 하는 식으로 사용됩니다. 본 논문에서는 이런 pre-train을 할 때 사용되는 supervision 때문에 ViT가 CV에서 성공하지 못했다고 생각했습니다. ViT는 NLP-task에 큰 성공을 이루었던 transformer 모델을 vision-task에 맞게끔 변형시킨 모델인데, 저자는 transformer가 NLP-task에서 성공한 이유가 "BERT의 close precedure" , "GPT의 language modeling" 과 같은 self-supervised learning 을 사용했기 때문이라고 생각했습니다. 즉, ViT 역시 image 수준에서 supervision을 사용하게 되면 image에 포함된 풍부한 시각정보들을 몇 천개 정도의 카테고리들 중에서 선택된 단일 개념으로 죽인다고 생각을 했던 것이죠.
저자들은 이에 대해 영감을 받아 ViT feature에 대해 self-supervised 로 pre-training 을 할 때 효과에 대해 연구를 진행하였고, supervised ViT 와 convnet 으로는 나타나지 않는 몇가지 흥미로운 특성들을 확인하게 됩니다.

- Self-supervised ViT feature들이 위 figure와 같이 scene layout 과 object boundary를 명시적으로 포함합니다. 이러한 정보들은 마지막 block의 self-attention modules에서 직접적으로 접근할 수 있다고 합니다.
- Self-supervised ViT feature들은 어떠한 finetuning, linear classifier, data augmentation 없이 basic nearest neighbors classifier(k-NN) 에서 특히 ImageNet 데이터셋의 정확도가 78.3%를 달성하는 등 좋은 성능을 보여주었습니다.
하지만 위의 K-NN 에서 보여주었던 우수한 성능은 momentum encoder, multi-crop augmentation 과 같은 특정 요소들이 결합되었을 때만 나타난다고 합니다. 또한 결과 feature의 quality를 올리는데 중요한 것들 중 하나가 바로 ViT에서 사용되는 patch의 크기를 작게 설정하는 것이라고 합니다.
본 논문에서는 위의 발견들에 대해 label이 없는 knowledge distillation의 형태로 해석되는 simple한 self-supervised 방법을 디자인하였으며, "knowledge distillation with no labels" 라고 하여 DINO라는 framework를 설계하게 됩니다. DINO는 표준 cross-entropy loss를 사용하여 momentum encoder와 함께 설계된 teacher network의 output을 직접 예측함으로써 self-supervised training을 간단하게 구축합니다. 단지 teacher output의 centering 과 sharpening 과 함께 작동시켜 collapse를 피할 수 있게 됩니다. 또한 구조 수정 및 내부 정규화 적용 필요 없이 convnet, ViT에서 잘 작동한다고 합니다.
게다가 작은 patch들을 사용한 ViT 가 이전의 self-supervised feature들을 뛰어넘는 것으로 DINO와 ViT 간의 synergy를 검증하게 됩니다. 또한 DINO가 SOTA ResNet-50 모델과 함께 잘 작동하는 것 역시 확인하였다고 합니다.
Approach
SSL with Knowledge Distillation
DINO는 최근 self-supervised 접근법들과 구조가 같지만, knowledge distillation 과 유사합니다. DINO의 전체적인 구조는 다음과 같습니다.
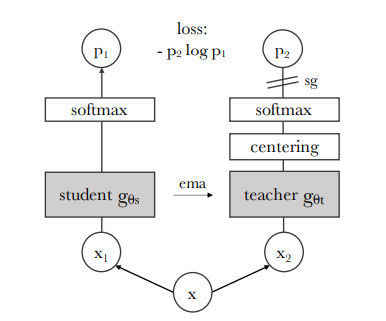
또한 DINO의 알고리즘은 다음과 같이 pseudo-code로 나타낼 수 있습니다.

knowledge distillation 은 student network $ g_{\theta s} $ 를 주어진 teacher network $ g_{\theta t} $ 의 output 에 맞도록 train 하는 식으로 진행됩니다. 여기에서 각 network의 parameter $ \theta_{s}, \theta_{t} $ 는 각각 주어집니다. Image $ x $ 에 대해 2개의 network는 K차원의 확률 분포 $ P_{s} $ 와 $ P_{t} $ 를 출력합니다. 또한 확률 분포 P는 network $ g $의 출력을 softmax function으로 정규화를 통해 생성됩니다. 다음 식은 $ P_{s} $ 확률 분포에 대한 것이며, $ P_{t} $ 역시 동일한 형식으로 정규화가 진행됩니다.
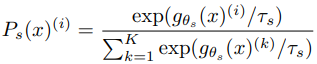
위 식의 temperature parameter인 $ T_{s} > 0 $ 는 출력 분포의 날카로움을 제어하는데 사용됩니다.
고정된 teacher network $ g_{\theta t} $ 가 주어지면, student network의 파라미터 $ \theta_{s} $ 를 cross-entropy loss를 최소화하는 방향으로 update하여 두 network간 출력 분포를 일치시킵니다.

- $ H(a,b) = -a log b $
여기까지 DINO의 전체적인 방법론에 대해 알아보았습니다. 다음으로는 위 방법론에 대해 저자들이 어떻게 적용하였는 지에 대해 알아보겠습니다. 우선 image에 대해 multi-crop 전략으로 다양한 distorted view 나 crop을 구성하여 다양한 view의 집합 V를 생성합니다. 이 집합 V는 2개의 global view $ x^{g}_{1} $ 와 $ x^{g}_{2} $ 그리고, 작은 해상도의 여러 local view를 포함합니다. 이렇게 생성된 모든 crop은 student network를 통과하지만 teacher network의 경우 global view만을 통과시킴으로써 local-to-global correspondence를 장려합니다. 이를 통해 위에서 정의했던 loss를 최소화하는 식을 다음과 같이 재구성할 수 있습니다.
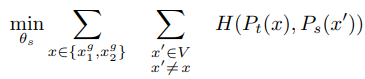
위 loss는 general하며, 2개의 view 뿐만 아닌 여러 개의 view가 사용될 수 있습니다. 하지만 저자들은 다음과 같이 multi-crop을 위해 표준 setting을 따릅니다.
- original image의 50% 이상 넓은 영역을 포함하는 해상도 224x224인 2개의 global views
- original image의 50% 이하 작은 영역을 포함하는 해상도 96x96인 여러개의 local views
두 network 모두 같은 구조 $ g $ 를 공유하지만 서로 다른 파라미터인 $ \theta_{s} $ 와 $ \theta_{t} $ 를 가집니다. 또한 student network의 파라미터인 $ \theta_{s} $ 는 위 loss 식을 최소화하는 방향으로 SGD(Stochastic Gradient Descent) 를 사용하여 학습시킵니다.
Teacher network
knowledge distillation 과 달리 미리 주어진 teacher network가 존재하지 않기 때문에 student network의 과거 iterations 에서 teacher network를 구축합니다. 저자들은 teacher network를 update하는 다양한 방법들에 대해 실험을 진행하였으며, teacher network를 epoch 동안 freeze 하는 방식이 좋은 결과를 보여준다고 하였으며, student network의 weight 를 teacher network에 복사하는 것은 수렴하는데 실패하였다고 합니다. 단순히 복사하는 것이 아닌 student network 의 weight에 EMA(Exponential Moving Average) 를 사용하는 momentum encoder 가 DINO 에 잘 맞았다고 합니다. teacher network 파라미터 $ \theta_{t} $ 는 다음과 같이 update 됩니다.
$$ \theta_{t} \leftarrow \lambda \theta_{t} + (1 - \lambda)\theta_{s} $$
위 식에서 $ \lambda $ 는 훈련 동안 0.996 ~ 1 로부터 cosine schedule을 따릅니다. 또한 원래 momentum encoder 는 contrastive learning의 queue 에서 사용되었었지만, DINO 에서는 queue 나 contrastive loss가 존재하지 않으므로 역할이 다르고 self-training 에 사용하는 mean teacher 의 역할을 합니다. 또한 train 동안은 teacher가 student 보다 성능이 좋으며, teacher 는 target feature를 제공하여 student의 학습을 guide하는 식으로 진행됩니다.
Network architecture
neural network $ g $ 는 ViT 나 ResNet backbone $ f $ 와 projection $ h $ 으로 이루어집니다.
- $ g = h \circ f $
projection head는 3-layer의 MLP(Multi-Layer Perceptron) , $ l_{2} $ normalization , weight normalized 로 구성된 FC-layer 입니다. 또한 표준 convnet과 달리 ViT 는 기본적으로 BN(Batch Normalization) 을 사용하지 않기 때문에 ViT 에 DINO를 적용할 때는 projection head에서 BN 을 제거하여 전체적으로 시스템에 BN이 없도록 하였다고 합니다.
Avoiding collapse
다양한 self-supervised 방법론들은 collapse를 피하기 위해 contrastive loss, clustering constraints, predictor, batch normalization 과 같은 방법들을 사용합니다. 물론 DINO 역시 여러 normalization으로 안정화될 수는 있지만 collapse를 피하기 위해서 단순히 momentum teacher output의 centering 과 sharpening 만으로 잘 작동하는 것을 확인할 수 있었다고 합니다.
centering의 경우 특정 차원이 너무 지배적이지 않도록 하기 위해 사용됩니다. 하지만 이는 uniform 분포로의 collapse를 조장하죠. sharpening 의 경우 centering과 정반대의 효과를 불러옵니다. DINO는 centering과 sharpening 을 모두 사용하여 collapse를 피하도록 균형을 맞춥니다.
collapse를 피하기 위해 centering을 사용하면 batch에 대한 의존도를 낮추기 위해 안정성은 낮아집니다. 이는 centering 이 1차 batch statics에만 의존하며 teacher 에 bias 를 추가하는 것으로 해석될 수 있죠.
$$ g_{t}(x) \leftarrow g_{t}(x) + c $$
위 식에서 중심 c는 EMA로 update되며, batch size가 달라도 잘 적용된다고 합니다.
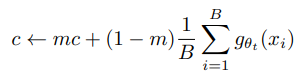
위 식에서 $ m > 0 $ 은 rate parameter 이고, $ B $ 는 batch size를 의미합니다. 또한 sharpening의 경우 teacher softmax normalization 의 temperature parameter $ T_{t} $ 를 낮은 값으로 설정하는 것으로 수행할 수 있습니다.



