
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Computer Vision
- programmers
- 머신러닝
- 파이썬
- Semantic Segmentation
- ViT
- 인공지능
- cnn
- 알고리즘
- 코드구현
- 논문리뷰
- opencv
- Ai
- 논문 리뷰
- 논문구현
- Python
- Self-supervised
- Convolution
- transformer
- pytorch
- 파이토치
- 프로그래머스
- 코딩테스트
- object detection
- optimizer
- 논문
- 옵티마이저
- 딥러닝
- Segmentation
- Paper Review
- Today
- Total
Attention please
[딥러닝] 옵티마이저(optimizer) - Momentum 본문
2022.09.29 - [딥러닝] - 옵티마이저(optimizer) - SGD
옵티마이저(optimizer) - SGD
옵티마이저란 model을 학습시키기 위해 설정해주어야 하는 작업입니다. SGD를 제외한 옵티마이저들은 모두 SGD의 응용으로 만들어졌습니다. optimizer에 대해 쉽게 설명하자면 산을 한걸음 한걸음
smcho1201.tistory.com
지난 글에서는 모든 optimizer의 기초가 되는 SGD에 대해 설명하였습니다.
이번에는 SGD의 문제점 중 local minimum에 빠지는 문제를 해결하기 위해 고안된
Momentum 기법에 대해 알아보겠습니다.
Momentum
위에서 말했던 것처럼 momentum은 SGD의 local minimum에 빠져버리는 문제를
해결하기 위해 생겨난 기법입니다.
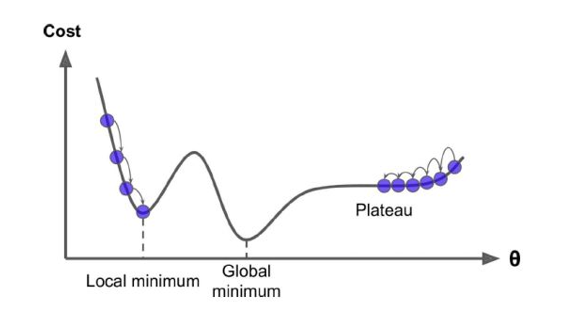
위와 같이 학습의 목표는 global minimum의 위치까지 가야하지만
local minimum에 바져버린다면 최소점이 아니기에 학습이 잘되었다고
말하기 어렵습니다.
그렇다면 어떻게 다시 올라가서 global minimum에 도착할지 생각한 결과
관성을 이용하는 기법이 태어났습니다.
즉 관성을 이용해 힘을 더 받아 최소점까지 갈 수 있도록 유도하는 원리입니다.

또한 SGD의 한계였던 지그재그로 요동치며 나아갔던 것이
Momentum에서는 진동방향이 서로 상쇄되고
진행방향은 관성을 받아 SGD에 비해 더 효율적으로 움직이는 것을 볼 수 있었습니다.
수식
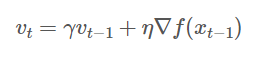

v(n) : 속도, v(n-1) : 관성, r : 관성계수
언뜻 보면 SGD 수식과 유사합니다.
momentum이 SGD의 영향을 받았기 때문이며, 기존의 SGD에서 관성만 넣어준 것입니다.
설정할 파라미터는 관성계수인데 관성계수가 크면 클수록
속도가 관성에 더 많은 영향을 받게 됩니다.
코드구현
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]초기에 설정해주어야 할 파라미터는 learning rate와 momentum계수입니다.
learning rate는 역시 0.01이 일방적으로 쓰이며,
momentum계수(관성계수)는 0.9가 일방적으로 쓰입니다.
한걸음을 나아가는 함수는 update메서드로 정의하였습니다.
처음 출발하였을 때는 이전의 속도가 없었기 때문에 관성이 없으므로 v는 None으로 입력됩니다.
즉 조건문
if self.v is None:이 충족되면 v(-1)의 값은 0이 됩니다.
(처음 출발하였을 때 관성은 존재하지 않기 때문)
그 후에 위 수식을 코드화하여 계산합니다.
'딥러닝 > DNN' 카테고리의 다른 글
| [딥러닝] 옵티마이저(optimizer) - Adam (0) | 2022.09.30 |
|---|---|
| [딥러닝] 옵티마이저(optimizer) - RMSProp (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - AdaGrad (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - NAG (0) | 2022.09.30 |
| [딥러닝] 옵티마이저(optimizer) - SGD (2) | 2022.09.29 |



