
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- optimizer
- object detection
- 논문구현
- Python
- Semantic Segmentation
- Paper Review
- 머신러닝
- Segmentation
- Convolution
- 논문리뷰
- pytorch
- 프로그래머스
- 인공지능
- 코딩테스트
- Computer Vision
- 논문 리뷰
- Self-supervised
- 딥러닝
- programmers
- cnn
- 논문
- 파이썬
- 코드구현
- 파이토치
- 알고리즘
- transformer
- Ai
- ViT
- opencv
- 옵티마이저
- Today
- Total
목록분류 전체보기 (116)
Attention please
 [딥러닝] Batch Normalization (배치정규화)
[딥러닝] Batch Normalization (배치정규화)
2022.10.01 - [딥러닝] - LeCun / Xavier / He 초기값 설정 - 표현력 제한, vanishing gradient문제 보완 LeCun / Xavier / He 초기값 설정 - 표현력 제한, vanishing gradient문제 보완 2022.09.30 - [딥러닝] - 옵티마이저(optimizer) - Adam 옵티마이저(optimizer) - Adam 2022.09.30 - [딥러닝] - 옵티마이저(optimizer) - RMSProp 옵티마이저(optimizer) - RMSProp 2022.09.30 - [딥러닝] - 옵티.. smcho1201.tistory.com 이전 글에서는 표현력 제한과 vanishing gradient문제를 보완하기 위해 초기값을 어떻게 설정해야 하는지..
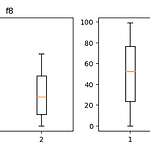 데이터 분석;boxplot으로 중요한 피처 구분하기 - matplotlib
데이터 분석;boxplot으로 중요한 피처 구분하기 - matplotlib
머신러닝에 필요한 데이터들을 수집한 후 우리는 EDA(Exploratory Data Analysis)를 해줄 필요가 있습니다. 어떤 feature가 중요한지 구분하기 위해 class별로 각 feature 값들에 평균의 차이가 클수록 잘 구분한다고 생각하고 시각화를 해보겠습니다. 먼저 데이터를 불러오겠습니다. data = pd.read_table('data/7w_d1.txt', sep = '\t') data 데이터를 보니 feature와 class가 column으로 되어있는 것을 확인할 수 있습니다. 또한 feature는 10개, class는 0과 1 총 2개가 있습니다. 먼저 class별로 데이터를 나누어 주겠습니다. data0 = data.loc[data['class'] == 0] data0 = dat..
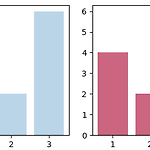 Color와 Style 사용하기 - matplotlib
Color와 Style 사용하기 - matplotlib
지금까지는 matplotlib의 다양한 함수들을 이용해 용도에 맞게 여러 종류의 그림들을 그려보았습니다. 하지만 matplotlib에서 제공되는 기본 컬러는 단조로운 단점이 있습니다. 그렇기에 본인이 직접 원하는 색을 설정하여 보다 다채롭게 그림을 그릴 수 있어야 합니다. rgb 본인이 원하는 컬러를 사용하기 위해 컬러 설정을 rgb로 표현할 수 있습니다. r,g,b는 각각 0~1사이의 float값으로 나타낼 수 있습니다. alpha 또한 alpha 파라미터를 이용하여 투명도를 설정할 수 있습니다. 0~1 사이의 값으로 설정할 수 있으며, default값은 1입니다. 0에 가까울수록 흐리게 표현되며, 1에 가까울수록 진하게 표현됩니다. 그러면 코드로 살펴보겠습니다. fig = plt.figure(figs..
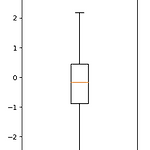 상자그림 그리기(boxplot) - matplotlib
상자그림 그리기(boxplot) - matplotlib
이번에 그려볼 것은 상자그림(boxplot)입니다. 상자그림은 수치형 자료 표현을 위한 기법입니다. 먼저 상자그림을 살펴보겠습니다. fig = plt.figure(figsize = (3,5), dpi = 100) ax = fig.subplots() data = np.random.normal(size = 100) ax.boxplot(data) 상자그림을 그리기 위해 boxplot 함수를 사용합니다. 먼저 결과를 보면 이와 같은 결과가 나오게 되는데 기본적으로 상자그림은 최소값(min), 제1사분위(Q1), 제2사분위(Q2), 제3사분위(Q3), 최대값(max)으로 구성됩니다. 그리고 저 위에 동그라미로 표현된 것은 이상치이며, Q2를 표시한 주황색 선이 평균이 아닌 중앙값임을 주의하도록 합니다. 다음은 피..
 히스토그램 그리기(hist) - matplotlib
히스토그램 그리기(hist) - matplotlib
히스토그램은 도수분포표를 그래프로 나타낸 것입니다. 주로 분포를 확인할 때 자주 사용되는 시각화 기법입니다. 그러면 코드부터 살펴보겠습니다. fig = plt.figure(figsize = (5,3), dpi = 100) ax = fig.subplots() data = np.random.normal(size = 1000) _=ax.hist(data, bins = 20, edgecolor = 'k') 히스토그램을 그리기 위해 사용하는 함수는 hist입니다. 이 hist함수에는 bins와 edgecolor 파라미터가 존재하는데 bins 파라미터는 생성되는 막대그래프의 개수입니다. 그래서 bin수가 20개라면 주어진 data의 최대값, 최소값 사이를 bin 수만큼 균등하게 나누어 표현합니다. 다음으로 edge..
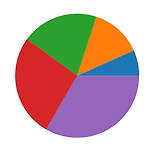 원형차트(pie) 그리기 - matplotlib
원형차트(pie) 그리기 - matplotlib
이번에는 pie 차트를 그려보도록 하겠습니다. pie차트를 그리기 위해 필요한 함수는 "pie" 입니다. 간단하게 파이차트를 그려보도록 하겠습니다. fig = plt.figure(figsize = (5,5), dpi = 100) ax = fig.subplots() data = np.arange(1,6) _=ax.pie(data) normalize pie 함수에는 normalize라는 파라미터가 존재합니다. 디폴트값은 True이며, 만약 False로 하게 되면 파이차트에 남는 공간이 생기더라도 그대로 출력됩니다. fig = plt.figure(figsize = (5,5), dpi = 100) ax = fig.subplots() data = np.arange(1,6) * 0.05 _=ax.pie(data, ..