
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Segmentation
- programmers
- 파이썬
- pytorch
- 코드구현
- Convolution
- 딥러닝
- transformer
- 옵티마이저
- Self-supervised
- 강화학습
- Computer Vision
- 논문구현
- 인공지능
- optimizer
- Semantic Segmentation
- 코딩테스트
- 파이토치
- Python
- opencv
- 논문리뷰
- 머신러닝
- 알고리즘
- cnn
- 논문
- 프로그래머스
- Ai
- object detection
- ViT
- 논문 리뷰
Archives
- Today
- Total
Attention please
데이터 분석;boxplot으로 중요한 피처 구분하기 - matplotlib 본문
728x90
반응형
머신러닝에 필요한 데이터들을 수집한 후
우리는 EDA(Exploratory Data Analysis)를 해줄 필요가 있습니다.
어떤 feature가 중요한지 구분하기 위해
class별로 각 feature 값들에 평균의 차이가 클수록
잘 구분한다고 생각하고 시각화를 해보겠습니다.
먼저 데이터를 불러오겠습니다.
data = pd.read_table('data/7w_d1.txt', sep = '\t')
data
데이터를 보니 feature와 class가 column으로 되어있는 것을 확인할 수 있습니다.
또한 feature는 10개, class는 0과 1 총 2개가 있습니다.
먼저 class별로 데이터를 나누어 주겠습니다.
data0 = data.loc[data['class'] == 0]
data0 = data0.drop(columns=['class'])
data1 = data.loc[data['class'] == 1]
data1 = data1.drop(columns = ['class'])data0은 class가 0인 행들,
data1은 class가 1인 행들로 구분지어 주었습니다.
이제 중요한 피처를 추출해보겠습니다.
mean_diff = abs(data0.mean(axis=0) - data1.mean(axis=0))
mean_diff_sorted = mean_diff.sort_values()
g1, g2 = mean_diff_sorted.index[-2:]
b1, b2 = mean_diff_sorted.index[:2]
g1,g2피처 값들의 평균 차가 작은 순서대로 정렬시킨 후
가장 중요한 피처 2개는 g1, g2로
가장 중요하지 않은 피처 2개는 b1, b2에 저장시켜주었습니다.
이제 이 4개의 피처들이 어떤식으로 분포되어있는지
boxplot으로 시각화를 해보겠습니다.
fig = plt.figure(figsize = (15, 3), dpi = 100)
axs = fig.subplots(1,4)
for ii,f in enumerate([g1, g2, b1, b2]):
_= axs[ii].boxplot([data0[f], data1[f]])
_= axs[ii].set_title(f)
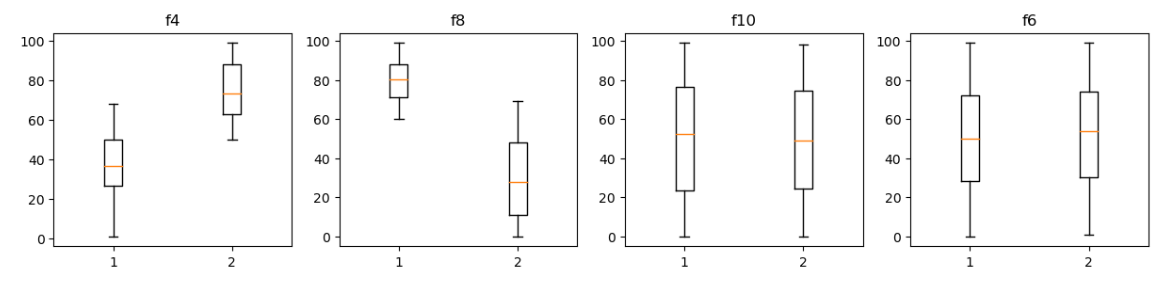
위와 같이 성능이 좋은 피처일 수록 class마다 차이가 나는 것을
boxplot으로 확인할 수 있습니다.
728x90
반응형
'데이터 시각화 > matplotlib' 카테고리의 다른 글
| 데이터 시각화(tick label & tick param & text) - matplotlib (0) | 2022.11.18 |
|---|---|
| 데이터 시각화(title & lim & tick) - matplotlib (0) | 2022.11.17 |
| Color와 Style 사용하기 - matplotlib (0) | 2022.10.08 |
| 상자그림 그리기(boxplot) - matplotlib (0) | 2022.10.08 |
| 히스토그램 그리기(hist) - matplotlib (0) | 2022.10.08 |
'데이터 시각화/matplotlib' Related Articles
more




Comments