
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- object detection
- cnn
- 논문 리뷰
- 인공지능
- Segmentation
- 딥러닝
- Paper Review
- Semantic Segmentation
- optimizer
- programmers
- Self-supervised
- Python
- 파이토치
- 논문구현
- 알고리즘
- 옵티마이저
- transformer
- Computer Vision
- ViT
- Ai
- 프로그래머스
- opencv
- pytorch
- 논문
- Convolution
- 코드구현
- 파이썬
- 논문리뷰
- 코딩테스트
- 머신러닝
- Today
- Total
Attention please
왜 semantic segmentation에서 global contextual information이 중요할까? (with PSPNet) 본문
왜 semantic segmentation에서 global contextual information이 중요할까? (with PSPNet)
Seongmin.C 2023. 7. 21. 15:59computer vision에서 가장 처음이자 각광을 받았던 분야는 image classification입니다. 특히 ILSVRC 대회가 열리게 되면서 풍부한 ImageNet 데이터셋을 가지고 많은 사람들이 image classification challenge에 뛰어들었으며, 많은 발전들이 있었습니다. 대표적으로 2012년도의 AlexNet을 시작으로 현재에도 여러 방면으로 활용되고 있는 VGG, Inception, ResNet 등 많은 모델들이 나오기 시작했습니다.
하지만 사람들은 이러한 기법들을 단순히 image classification에서 만족하지 않았으며, 각 객체의 위치를 탐지하는 Image segmentation 에서도 활용하게 됩니다. 간단하게 설명하자면 classification의 경우 단순히 이미지 상에 객체가 어떤 클래스에 속하는 지 분류하는 것이 목적이었다면, segmentation의 경우 객체의 위치를 픽셀단위로 분류하여 영역을 검출하는 것을 목표로 합니다.
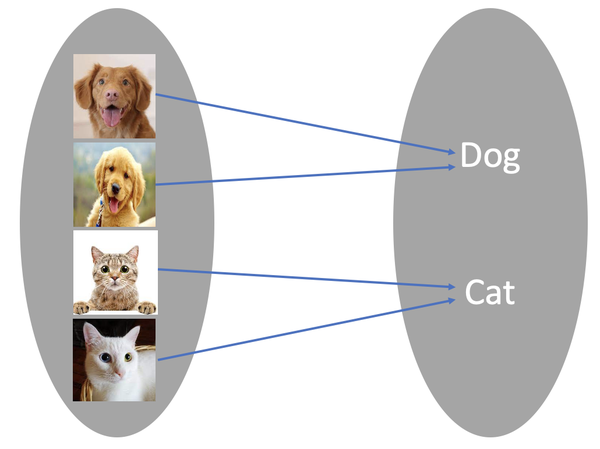
위 사진과 같이 image classification의 경우 단순히 이미지 속 객체가 어떤 클래스인지 분류하는 것에만 초점을 가집니다.

image segmentation의 경우 해당 객체의 위치를 픽셀단위로 분류하는 것에 초점을 맞추죠. 특히 semantic segmentation은 픽셀에 대해 어떤 객체에 속하는 지 카테고리화 하여 분류를 하게 됩니다.
많은 사람들은 image classification에 좋은 performance를 보여주었던 CNN기반 모델들을 image segmentation에 적용하기 시작합니다. 이 결과 생각보다 좋은 결과가 나온다는 것을 깨닫게 됩니다. 간단하게 접근 방식에 대해 살펴보자면 image classification의 경우 이미지가 input으로 들어왔을 때 여러 convolution layer를 통해 다양한 feature를 추출합니다. 처음에는 local 한 feature를 시작으로 pooling층을 거치면서 global한 feature에 대해 학습을 한 후 이미지 속 객체의 특징에 대해 어떤 class에 속하는 지 분류를 수행하죠.
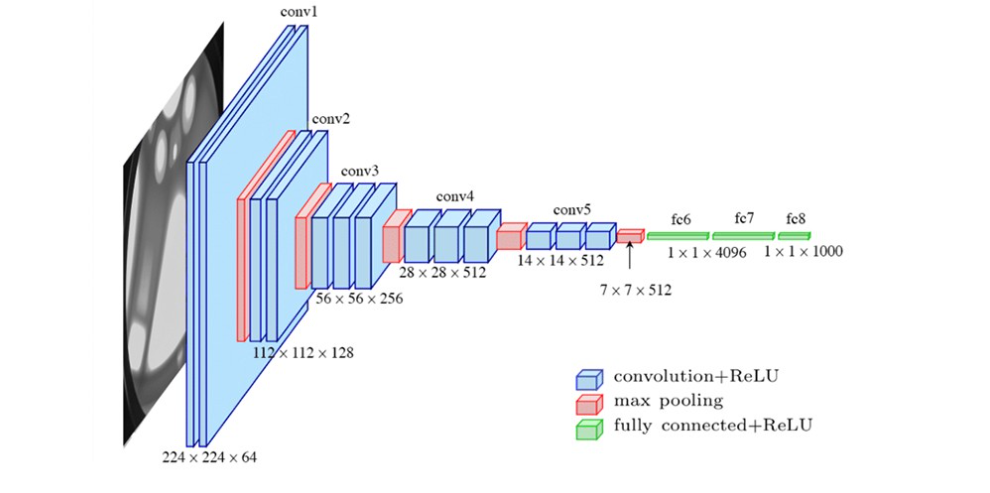
하지만 semantic segmentation의 경우 output의 결과가 vector가 아닌 input image의 같은 resolution을 가진 tensor 형태로 나와야합니다. 하지만 CNN의 경우 층을 지나갈수록 feature map의 해상도는 점차 줄어듭니다. (좀더 global한 정보를 취함과 동시에 연산량을 줄이기 위함이죠) 고로 다시 원 해상도로 복원을 시키기 위해 interpolation 혹은 decoder 형식을 도입합니다.
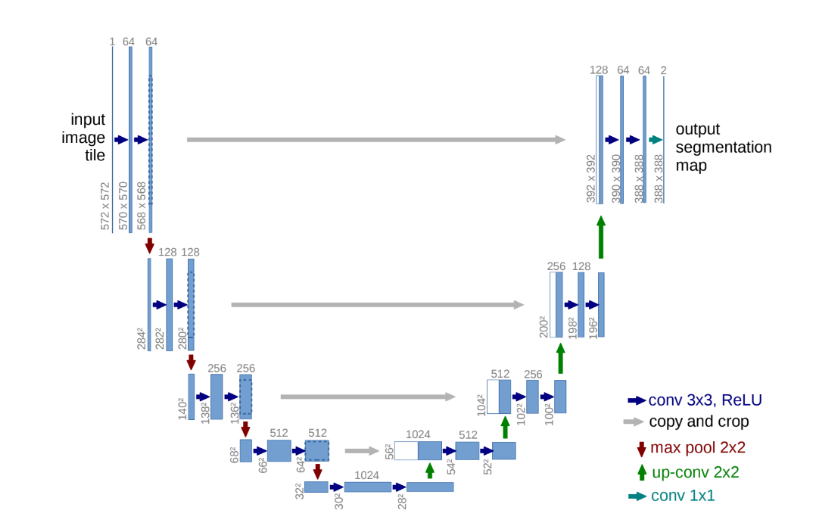
하지만 여기에서 문제가 하나 생기게 됩니다. classification의 경우는 image 내의 객체 위치 정보에 focus를 두지 않습니다. 사실 위치에 민감하지 않으려고 노력을 하죠. 이미지 내의 객체의 위치와 상관없이 robust하게 객체에 해당하는 class를 반환해야하기 때문입니다. 그렇기에 좀 더 추상적인 정보를 추출하는데 초점이 맞춰져 있습니다.
하지만 semantic segmentation의 경우는 다릅니다. 단순히 객체의 feature만을 잡아 class를 분류하는 것 뿐만 아니라 해당 객체의 위치 정보를 학습하여 픽셀 단위로 분류해야하기 때문이죠. 이를 spatial 혹은 contextual information을 얻어야 한다고 표현합니다. 이를 위해 다양한 segmentation 모델들은 contextual information을 보존하기 위해 많은 시도를 합니다. 당장 위 UNet 모델만 해도 contextual information을 보존하기 위해 encoder에서 decoder로 skip connection을 형성하기도 하죠. - [논문 리뷰] U-Net: Convolutional Networks for BiomedicalImage Segmentation(2015)
하지만 보통 CNN기반 모델들은 contextual information 중에서도 local contextual information에 대해 중점을 두는 경우가 많습니다. CNN은 입력 이미지의 local한 패턴을 잘 학습하며, 이는 이웃 픽셀들 사이의 관계를 기반으로 연산을 하는 convolution의 특징 때문이기도 하죠.
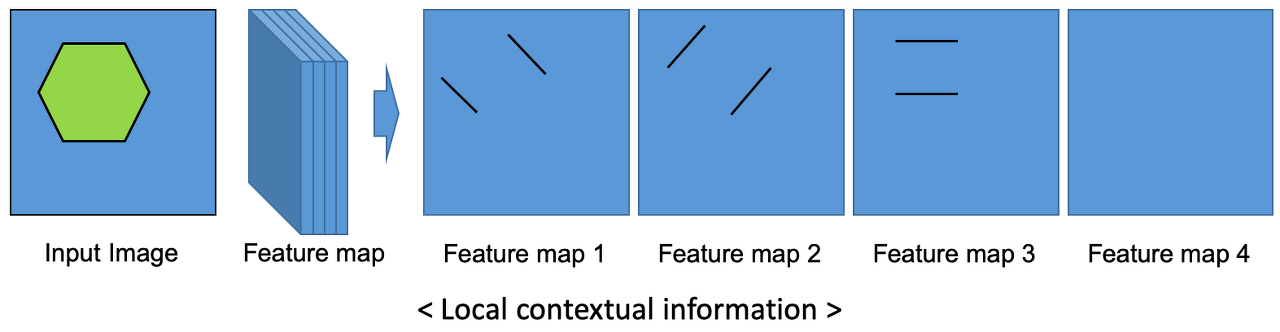
local contextual information의 경우 위 그림과 같이 육각형이라는 Input Image를 인식하기 위해 여러 feature를 학습합니다. 각 feature map을 보면 처음에는 왼쪽에서 아래로 내려가는 대각선, 두 번째는 왼쪽에서 위로 올라가는 대각선, 세 번째는 수평선을 인식하는 filter 역할을 하는 것을 확인할 수 있습니다.
이런 Local contextual information을 통해 객체의 특정 위치만으로도 해당 객체가 어떤 클래스에 속하는 지 분류할 수 있다는 장점을 가지기도 하죠. 보통 모양, 형상, 재질들을 예로 들 수 있겠습니다. 예를 들어 semantic segmentation을 위해 제안되었던 FCN의 경우 기본적인 convolution과 transposed convolution을 사용하여 encoder-decoder를 구축하기 때문에 local contextual information만을 고려하게 되어 기본적으로 성능이 좋지 않습니다.
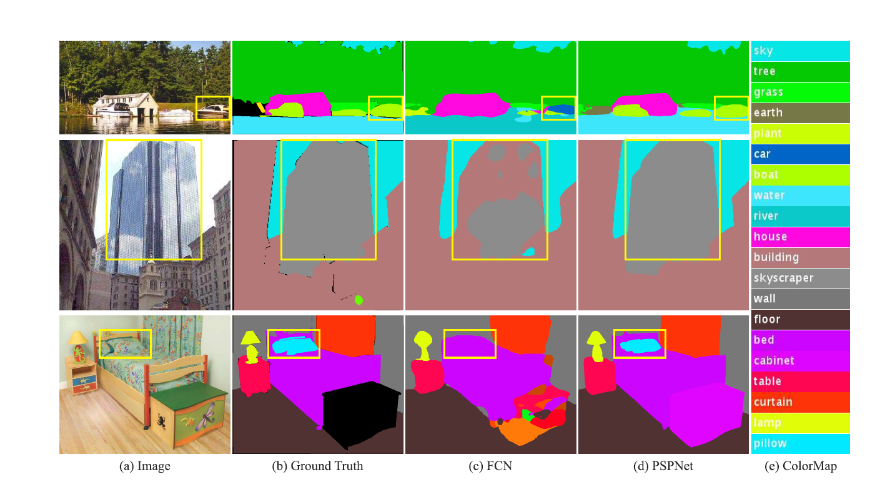
위 이미지를 보면 FCN은 PSPNet과 비교했을 때 다양한 문제점들을 보여줍니다.
- Mismatched Relationship : 주변 상황과 맞지 않는 픽셀 클래스 분류
가장 상단의 이미지를 보면 노란색 박스의 영역은 boat로 분류되어야합니다. 하지만 FCN에서는 노란색 박스 영역에 있는 객체를 자동차로 분류하였죠. 이는 물 위에 떠있는 보트를 단순히 객체의 local한 feature만을 고려하여 자동차라고 오분류한 결과입니다. "물 위에 떠있는 보트" 라는 global contextual information을 고려하지 못했다고 볼 수 있습니다. - Confusion Categories : 헷갈릴 수 있는 픽셀 클래스 분류
가운데 이미지를 보면 노란색 박스 영역에서 FCN의 경우 빌딩의 유리창에 비친 하늘에 대해 하늘이라고 오분류하였습니다. 이는 빌딩 전체에 대한 global contextual information 을 고려하지 못했다고 볼 수 있겠죠. 단순히 하늘에 대한 feature를 고려하여 하늘 영역이라고 고려한 것 같습니다. - Inconspicous Classes : 눈에 잘 띄지 않는 물체의 픽셀 클래스 분류
가장 하단의 이미지를 보면 노란색 영역에 눈에 띄지 않는 배게가 존재하는 것을 확인할 수 있습니다. 아무래도 주변 형상과 비슷하기에 FCN에서 단순히 이불이라 오분류한 모습을 확인할 수 있죠. 이 역시 좁은 영역에서의 feature를 고려하여 생긴 문제라 볼 수 있습니다.
위와 같이 global contextual information을 고려하지 않았을 때 생길 수 있는 문제들에 대해 알아보았습니다. 하지만 FCN과 달리 PSPNet은 오분류 없이 객체를 잘 인지하고 영역을 좋게 분할한 것을 볼 수 있었습니다. 즉, global contextual information을 잘 고려하였다고 볼 수 있겠죠. 그렇다면 어떻게 이를 수행할 수 있었는 지 알아보도록 합시다.
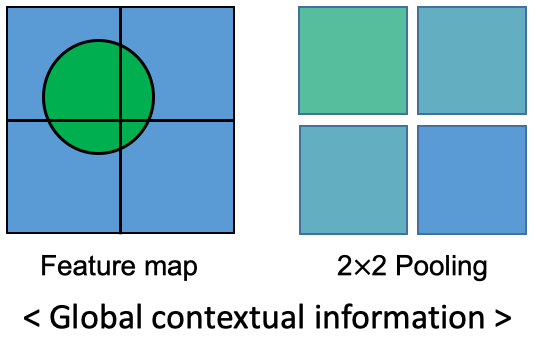
PSPNet의 경우 어떤 픽셀값의 클래스를 분류하기 위해서 단순히 해당 픽셀의 local한 feature만을 고려하지 않고, global한 정보를 같이 고려합니다. 위 이미지와 같이 global information을 고려하기 위해서 pooling을 사용합니다. 대표적으로는 max-pooling과 avg-pooling이 존재하죠.
우선 동그라미 feature를 가진 map을 4개의 sub-region으로 나눕니다. 이렇게 나누어진 sub-region에 대해 2x2 avg-pooling을 적용하여 각 sub-region의 전체적인 feature를 얻을 수 있게 됩니다. 만약 자동차 혹은 보트의 feature로 추정되는 local contextual information 근처에 물에 대한 feature가 포함되어 물 근처에 있는 해당 객체를 자동차가 아닌 보트로 잘 추정할 수 있게 되는 것이죠. 물론 단순히 pooling 연산을 한다고 효과적으로 global contextual information을 얻을 수 있는 것이 아닙니다. 그렇다면 PSPNet에서 효과적으로 global information을 얻기 위해 사용한 기법인 Pyramid Pooling Module에 대해 살펴보도록 합시다.

위 그림은 PSPNet에서 사용한 Pyramid pooling module에 대한 구조를 나타냅니다. 우선 input image에 CNN을 적용하여 feature map을 생성합니다. 본 논문에서는 feature map을 생성하기 위해 Dilated convolution을 적용한 ResNet을 사용하였다고 합니다. 이런 연산을 거쳐 나온 (b)의 feature map은 input image의 1/8 사이즈를 가진다고 합니다.
그 후에는 색깔별로 사이즈가 다른 max/avg-pooling 연산을 수행합니다. 기본적으로 pooling연산은 channel에 대해 독립적으로 연산됩니다. 즉, pooling 연산을 하는 동안 channel 수는 변함이 없다는 것이죠.
우선 각 색에 sub-region을 가지도록 window size를 조절하여 pooling 연산을 진행합니다. 이러한 연산은 Spatial Pyramid Pooling module과 비슷한 구조를 가집니다. - [논문 리뷰] Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition(2015)
각 sub-region이 1x1, 2x2, 3x3, 6x6 이 되도록 pooling 연산을 진행했다면 1x1 convolution으로 channel 수가 1이 되도록 합니다. 이를 통해 각 feature map의 정보를 압축하는 것이죠.
마지막으로 bilinear interpolation을 통해 입력되었을 때 feature map의 resolution이 되도록 하여 기존의 feature map과 빨간색, 주황색, 파란색, 초록색 feature map을 모두 concatenation 시켜줍니다.
PSPNet은 당시 SOTA모델에 비해 더 좋은 performance를 냈으며, 이는 global contextual information을 고려하는 것이 효과적이었음을 보여줍니다.
Reference
'딥러닝 > CNN' 카테고리의 다른 글
| Object Detection이란 무엇일까? (0) | 2022.12.30 |
|---|---|
| AP(Average Precision) & mAP(mean Average Precision)의 개념 (0) | 2022.12.30 |
| NMS(Non-maximum Suppression) 원리 (0) | 2022.12.30 |
| IoU(Intersection over Union)의 개념 및 코드 구현 (0) | 2022.12.30 |
| Separable & Depthwise & Pointwise Convolution 원리 및 Pytorch 구현 (0) | 2022.12.30 |



