
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Self-supervised
- 파이썬
- 코딩테스트
- 파이토치
- 논문 리뷰
- Ai
- 코드구현
- Computer Vision
- pytorch
- Paper Review
- 논문구현
- 옵티마이저
- 논문리뷰
- 논문
- Segmentation
- 딥러닝
- ViT
- Convolution
- Semantic Segmentation
- 프로그래머스
- optimizer
- programmers
- 인공지능
- cnn
- opencv
- object detection
- 머신러닝
- transformer
- Python
- 알고리즘
- Today
- Total
Attention please
[딥러닝] KLUE 데이터를 활용한 북마크 분류문제의 해결 본문
What Experiment?
KLUE 데이터셋은 Korean Language Understanding Evaluation 의 약자로 한국어 모델 성능을 평가하기 위한 벤치마크 데이터셋이다. KLUE 데이터셋에는 총 8가지의 task가 존재하는데 그 중에서도 이번에 활용할 task는 TC(Topic Classification) 이다.
이번 프로젝트의 주제는 위에서 설명한 KLUE 데이터를 사용하여 북마크된 기사들의 제목들을 각 topic에 맞게 분류하는 것이다. 예를 들어 "[삼성화재배 AI와 함께하는 바둑 해설] 조용히 완성된 철갑 공격군 | 중앙일보" 라는 기사 제목을 보고 "IT과학" 으로 분류한다.
구글에는 원하는 페이지를 북마크할 수 있는 기능이 존재한다. 이 북마크에는 다양한 기능이 존재하는데 그 중에서 이번에 활용할 기능은 북마크를 HTML문서로 내보내고 또 가져오는 것이다. 즉, 이번 프로젝트의 과정을 간단히 말하자면 무작위로 섞여있는 북마크된 기사들을 HTML문서로 추출한 것을 알고리즘을 통해 topic classification을 진행하여 새로운 HTML문서를 만들어주는 것이다.
Bookmark to HTML
실험을 위해 미리 다양한 주제의 기사를 북마크하였다.

총 84개의 기사를 북마크하였고 이를 HTML문서로 변환하였다.

다음과 같이 위의 북마크가 HTML문서로 추출된 것을 볼 수 있다.
Dataset
KLUE 데이터셋으로 pre-trained 되어있는 모델을 fine-tuning 하기 위한 데이터가 필요했고 DACON 경진 대회 플랫폼에서 구할 수 있었다.
https://dacon.io/competitions/official/235747/overview/description
월간 데이콘 뉴스 토픽 분류 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
데이터는 모두 csv파일 형태로 저장되어 있는데 이를 불러와 데이터프레임으로 변환하였다.
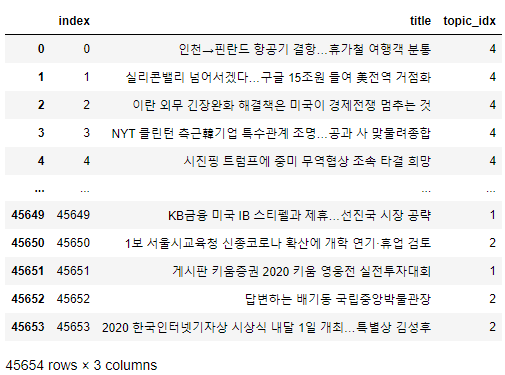
다음과 같이 index, title, topic_idx 컬럼으로 구성되어 있는 것을 볼 수 있으며, topic_idx 컬럼의 숫자들은 다음과 같이 각 기사의 topic 종류를 의미한다.
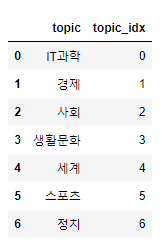
또한 위에서 북마크하였던 84개의 기사에 대한 html문서 역시 데이터프레임으로 변환하였다.
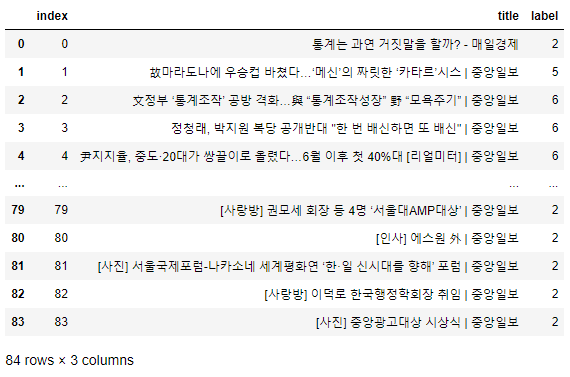
위 데이터 프레임의 label 컬럼의 숫자들 역시 각 기사의 topic을 숫자로 분류해 놓은 것이다.
Model
이 프로젝트에서 사용할 모델은 KLUE 데이터셋을 통해 pretrained된 모델이다. KLUE 데이터셋을 통해 pretrained된 모델은 다양하게 존재하는데 그 중에서도 다양한 task에 대체로 좋은 성능을 보여주었던 KLUE-RoBERTa-large 모델을 사용하였다.
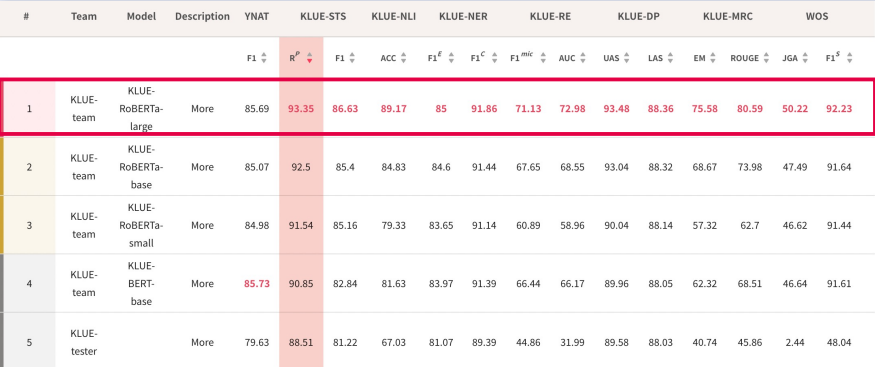
Metric
이번 프로젝트의 metric으로 사용한 것은 F1-score 이다. ACC (정확도) 만으로 판단하기에는 데이터의 비정형성에 취약하다는 단점이 있어 이를 보완한 것이 정밀도와 재현율의 조화평균인 F1-score 이다.
$$ \begin{align*} F1-score = 2 \times \frac{precision \times Recall}{precision + Recall} \end{align*} $$
실험 결과 ACC는 0.79, F1-score는 0.76 의 수치를 보여주었다.
Return to Bookmark
fine-tuning 까지 완료한 KLUE-RoBERTa-large 모델을 통해 북마크하였던 84개의 기사 데이터를 각 topic에 맞게 분류한 후 다시 HTML문서로 변환하였다.
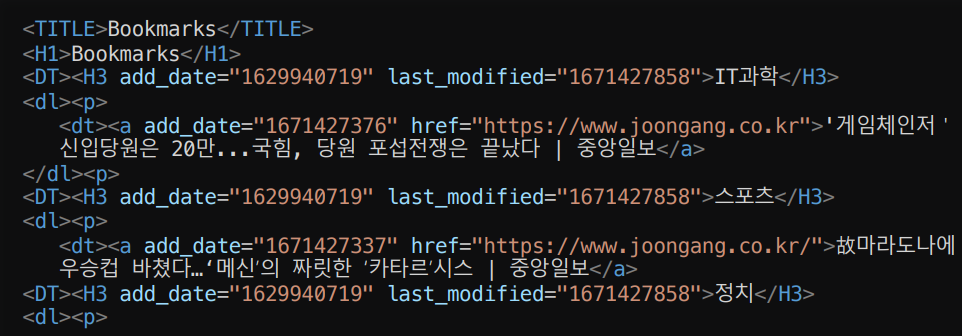
따로 HTML에 대해 공부를 한 적이 없어 하나하나 뜯어보며 파악을 했어야 했다. 하지만 분명 구성도 맞게 코드를 완성했지만 계속되는 오류로 크게 절망했었다. HTML문서를 열었을 때는 잘 분류가 된 상태로 출력되었지만 구글 북마크에 적용하면 폴더가 생기지 않았다. 결국 문제의 원인을 발견했는데 먼저 HTML문서의 태그들을 다루기 위해 사용한 패키지는 BeautifulSoup 이다. 이 패키지의 놓쳤던 특징 한가지는 HTML문서를 불러오면 대문자였던 태그들이 모두 소문자로 바뀐다는 것이다.
폴더를 생성하는 DT 태그는 dt와 같이 소문자로 입력하게 되면 폴더가 따로 생성되지 않았던 문제가 있었다. 즉, 모든 작업을 끝낸 후 마지막에 DT 태그를 대문자로 바꾸어주는 작업을 해야했다.
위의 문제를 무사히 해결하였고 구글 북마크 역시 정상적으로 작동하였다. 위에서 임의로 뽑은 84개의 기사를 topic에 맞게 분류를 한 모습은 다음과 같다.
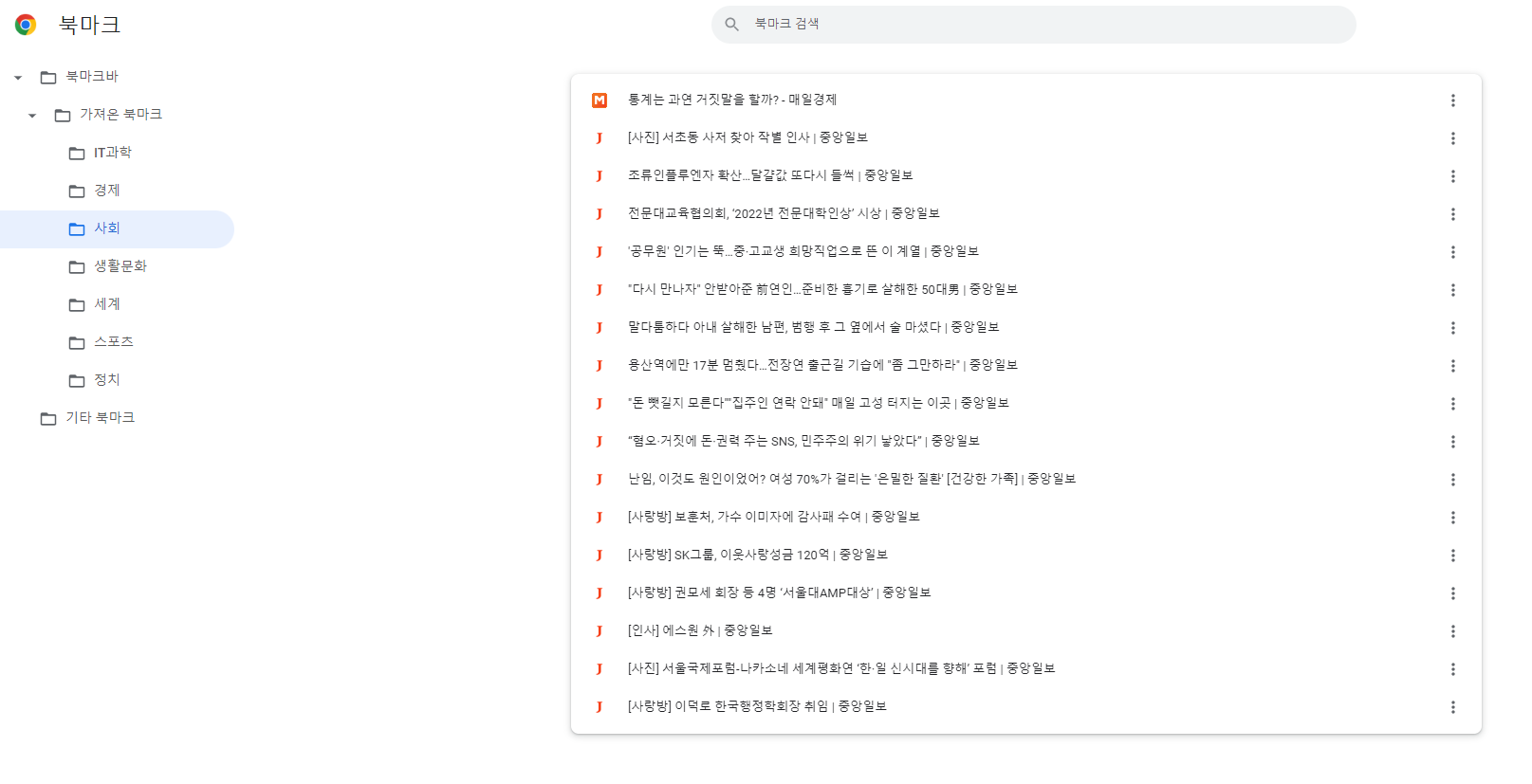
위 사진과 같이 잘 작동되어 북마크에 적용된 것을 확인할 수 있다.
'프로젝트' 카테고리의 다른 글
| pyautogui로 카카오톡 예약 메세지 보내기 (0) | 2023.08.14 |
|---|---|
| [OpenCV] OpenCV를 이용한 얼굴 감지 CCTV 만들기 (0) | 2023.01.10 |
| [OpenCV] OpenCV를 이용한 스캐너 만들기 (0) | 2023.01.09 |
| [딥러닝] 의료영상 종류에 따른 병변 영역 분할 딥러닝 모델 별 성능 비교 (0) | 2022.12.14 |
| [머신러닝] 시계열 데이터 - 농산물 가격 예측 (0) | 2022.11.07 |



