
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- optimizer
- 머신러닝
- ViT
- 논문
- 논문리뷰
- transformer
- 프로그래머스
- 논문구현
- programmers
- Semantic Segmentation
- Python
- 논문 리뷰
- Convolution
- opencv
- 인공지능
- object detection
- 코딩테스트
- 파이토치
- Paper Review
- 옵티마이저
- pytorch
- 코드구현
- 딥러닝
- Computer Vision
- 알고리즘
- Segmentation
- 파이썬
- cnn
- Self-supervised
- Ai
- Today
- Total
Attention please
[머신러닝] 시계열 데이터 - 농산물 가격 예측 본문
[안내] 2022 농넷 농산물 가격 변동률 예측 AI 경진대회
aifactory.space
이번 프로젝트는 AIfactory 플랫폼에서 진행하는 대회 중
농산물 가격을 예측하는 것입니다.
다양한 농산물 품목들에 대해 각각 데이터가 준비되어있지만,
이번 글에서는 0번 품목의 데이터만 다루도록 하겠습니다.
또한 성능을 확인하기 위해서 test 데이터는 사용하지 않을 것이며,
train 데이터만을 사용하도록 하겠습니다.
Data
이번 글에서 다룰 데이터는 0번째 품목의 훈련데이터이며,
2013/01/01 ~ 2016/12/31 의 데이터가 저장되어있습니다.
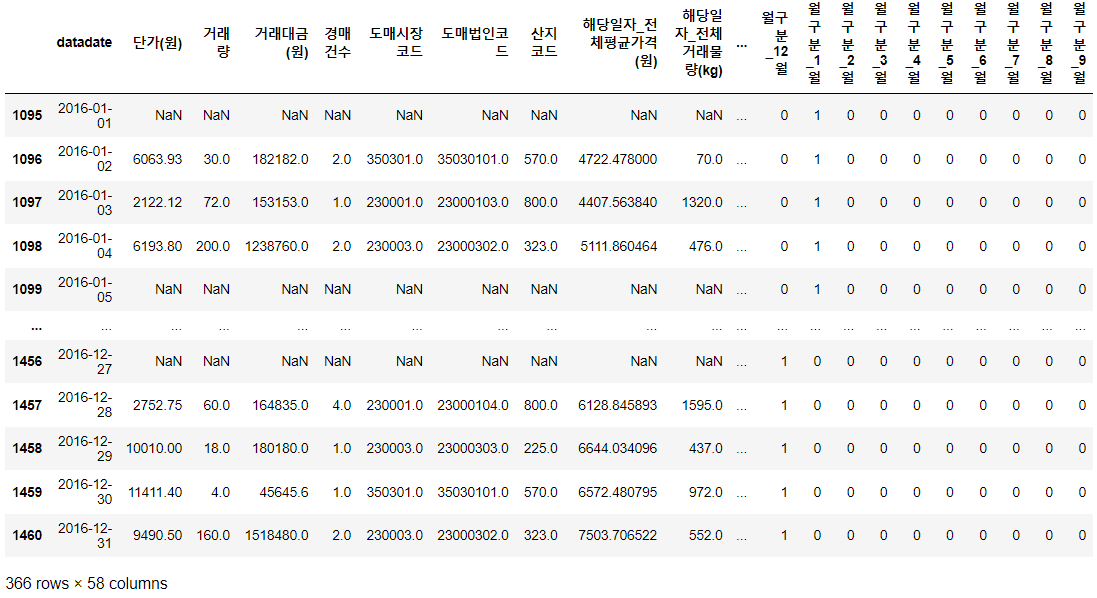
위의 사진과 같이 총 1461개의 행과 58개의 열로 이루어져있습니다.
이중 예측해야하는 target 변수는
"해당일자_전체평균가격(원)"
이 되겠습니다.
2016, 1년 동안의 target 변수의 흐름을 시각화하면,

다음과 같은 추세를 보입니다.
walk-forward validation
시계열 데이터는 종류마다 각각의 패턴들을 가지고 있습니다.
크게 추세(trend), 계절성(seasonality), 주기(cycle) 3가지로 나누어 볼 수 있습니다.
이번에 다룰 데이터는 2013, 2014, 2015, 2016년도 나누어져있으며,
만약 각각 1년의 추세가 일정하다면, trend를 기준으로 분해가 가능합니다.
각 1년의 추세가 일정한지 비교하기 위해 각 데이터를 시각화해보겠습니다.
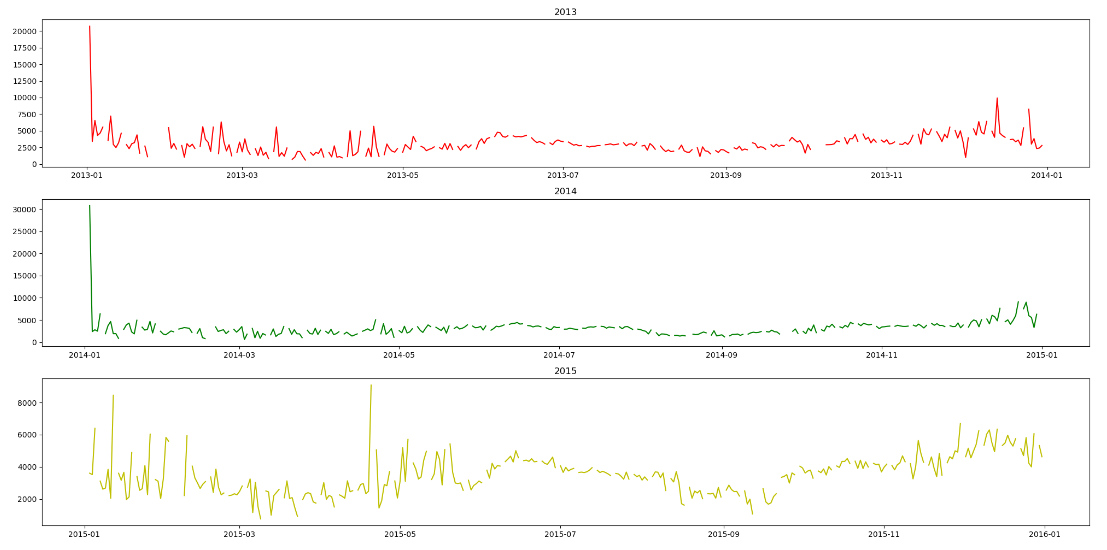
2013 ~ 2015 동안의 각 3년의 데이터의 추세를 시각화 하였으며,
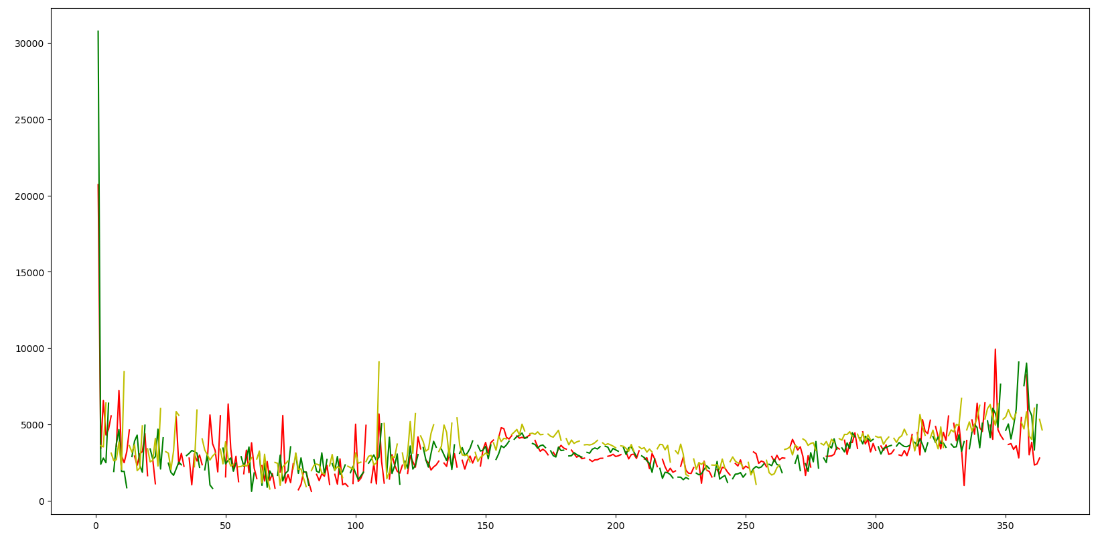
1년을 기준으로 trend를 보았을 때 비슷함을 알 수 있었습니다.
고로 데이터를 분해할 때
2013 ~ 2015 데이터를 train 데이터로,
2016 데이터를 validation 데이터로 분해하도록 하겠습니다.
test_df = df.iloc[-366:]
df = df.iloc[:-366]
Labeling
시계열 데이터는 기본적으로 한 Time point와 그 시점의 수치로 이루어져있습니다.
밑에서 사용할 머신러닝(Random Forest ...) 기법은 지도학습의 형태이므로,
Feature와 Label의 형태로 변형시켜야 합니다.
target 변수를 제외한
나머지 feature들의 변수명들을 모아놓은 리스트를 생성합니다.
target 변수와 object 타입이 들어있는 피처 2개를 추가로 제거해주었습니다.
(object 타입의 데이터가 학습할 때 들어가면 오류가 발생함)
feature = list(df.columns)
feature.pop(8)
feature.pop(29)
feature.pop(40)
또한 기본적으로 시계열 데이터는
"현재의 정보가 미래에 영향을 주는 것을 전제" 로 해야합니다.
즉 해당 feature의 정보들을 가지고 미래를 예측하도록
라벨링을 합니다.
#target: {pred_day}일 후의 해당일자_전체 평균가격(원)
pred_day = -3
df['해당일자_전체평균가격(원)'].head(16)
df['target'] = df['해당일자_전체평균가격(원)'].shift(pred_day)
df['target'].head(8)
pred_day 만큼 행을 shift 하기 전과 후의 series를 뽑아보면

다음과 같이 3일을 기준으로 'target' 변수가 생성된 것을 확인할 수 있습니다.
결측값 제거
결측값을 제거하는 방법은 다양하게 있지만,
이번에는 가장 간단한 "제거" , "채우기" 2가지를 사용하였습니다.
train에 사용할 데이터의 결측치를 제거
df_learn = df[df['target'].notnull()] # target 컬럼의 null값이 들어간 행 제거
df_learn = df_learn.fillna(method='ffill') # 결측치 기준 윗 값 copy
df_learn = df_learn.fillna(method='bfill') # 결측치 기준 아랫 값 copy
test에 사용할 데이터의 결측치 제거
# test_data predict
test_df['target'] = test_df['해당일자_전체평균가격(원)']
test_df = test_df[test_df['target'].notnull()]
test_df = test_df.fillna(method='ffill') # 결측치 기준 윗 값 copy
test_df = test_df.fillna(method='bfill') # 결측치 기준 아랫 값 copy
Random Forest
우선 위에서 분해한 데이터를 이용하여 학습을 진행하도록 하겠습니다.
먼저 feature와 라벨 변수가 들어간 x, y 변수를 지정해줍니다.
X = df_learn[feature] #label이 제거된 df (라벨 : object포함 column, target 변수)
y = df_learn['target'] #label : 3일 밀려난 target변수
x_test = test_df[feature]
y_test = test_df['target']
sklearn 라이브러리의 Random Forest를 이용하여 훈련을 진행하겠습니다.
model = RandomForestRegressor()
model.fit(X, y)
학습이 완료되었으면,
위에서 생성해둔 test 데이터를 사용하여 성능을 확인해보도록 하겠습니다.
y_pred_val = model.predict(x_test)
MAE_val = mean_absolute_error(y_test, y_pred_val)
MAE_val
위 코드를 실행하였을 때 MAE 값이 613.9075... 가 나오는 것을 확인 할 수 있습니다.
다음으로 실제 값인 y_test와 모델이 예측한 값인 y_pred_val을
그래프로 그려 비교해보도록 하겠습니다.
plt.figure(figsize=(20, 10), dpi=300)
plt.title('RandomForest test 2016'+ ' MAE : ' + str(MAE_val)[:7])
plt.plot(np.array(y_test), alpha = 0.9, label = 'Real')
plt.plot(y_pred_val, alpha = 0.6, linestyle = "--", label = 'Predict')
plt.legend()
plt.show()

Result
전통적인 시계열 예측 모델은
과거의 피처가 미래를 예측하도록 하는 것을 전제로 하여 발전해왔습니다.
이중에서도 항상 전제가 되는 것들 중 하나는 정상성(Stationary) 입니다.
하지만 시계열 데이터의 특성상 정상성은 적용되기 상당히 어렵습니다.
물론 시계열에 영향을 주는 변수를 포함하기 위한 기법들이 존재하지만
복잡하고 사용하기에 번거롭기 때문에
궁극적인 해결방안은 아니지만 참고용으로 사용하기에는
Random Forest 모델도 사용하기 적합하다 판단이 듭니다.
출처 : https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
'프로젝트' 카테고리의 다른 글
| pyautogui로 카카오톡 예약 메세지 보내기 (0) | 2023.08.14 |
|---|---|
| [OpenCV] OpenCV를 이용한 얼굴 감지 CCTV 만들기 (0) | 2023.01.10 |
| [OpenCV] OpenCV를 이용한 스캐너 만들기 (0) | 2023.01.09 |
| [딥러닝] KLUE 데이터를 활용한 북마크 분류문제의 해결 (0) | 2023.01.06 |
| [딥러닝] 의료영상 종류에 따른 병변 영역 분할 딥러닝 모델 별 성능 비교 (0) | 2022.12.14 |



