
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Segmentation
- opencv
- 머신러닝
- Convolution
- Computer Vision
- 인공지능
- Ai
- optimizer
- object detection
- programmers
- pytorch
- Semantic Segmentation
- 프로그래머스
- Self-supervised
- ViT
- transformer
- 파이썬
- 딥러닝
- 코딩테스트
- 논문구현
- 코드구현
- 논문 리뷰
- 파이토치
- 논문
- Python
- 논문리뷰
- Paper Review
- 옵티마이저
- cnn
- 알고리즘
- Today
- Total
Attention please
[딥러닝] 의료영상 종류에 따른 병변 영역 분할 딥러닝 모델 별 성능 비교 본문
What Experiment?
영역 분할(segmentation) 딥러닝 모델은 의료영상에서 많이 쓰이며 또 발전해왔다. 의료영상은 질환에 따라 영상의 종류와 feature가 전부 다르며, 딥러닝 모델 역시 영역 분할을 위해 개발된 다양한 모델들이 존재한다. 하지만 새로운 의료영상이 주어졌을 때 어떤 딥러닝 모델이 적합할지 선택할 때 어려움을 겪을 수 있다. 이러한 문제를 해결하고자 여러 종류의 의료영상에 대해 다양한 딥러닝 모델로 실험을 하여 성능을 비교하였다.
Dataset
의료영상에서 병변 영역을 검출할 때 가장 중요한 것은 의료영상의 종류이다. 어떤 종류의 영상인지에 따라 feature가 다르기 때문에 이는 모델 성능에 직접적으로 영향을 미친다. 이미 다양한 의료영상들이 나와있으며 이번 실험을 위해서 총 6가지의 데이터를 가져왔다.
외상 영상
- 피부암의 병변 (ISIC Challenge)
- 족부 궤양 (wound data)
내시경 영상
- 대장 내시경 내 용종 (Kvasir - SEG)
- 위장 내시경 내 용종 (CVC - ClinicDB)
초음파 영상
- 유방 내 양성종양 (Breast Ultrasound)
- 유방 내 악성종양 (Breast Ultrasound)
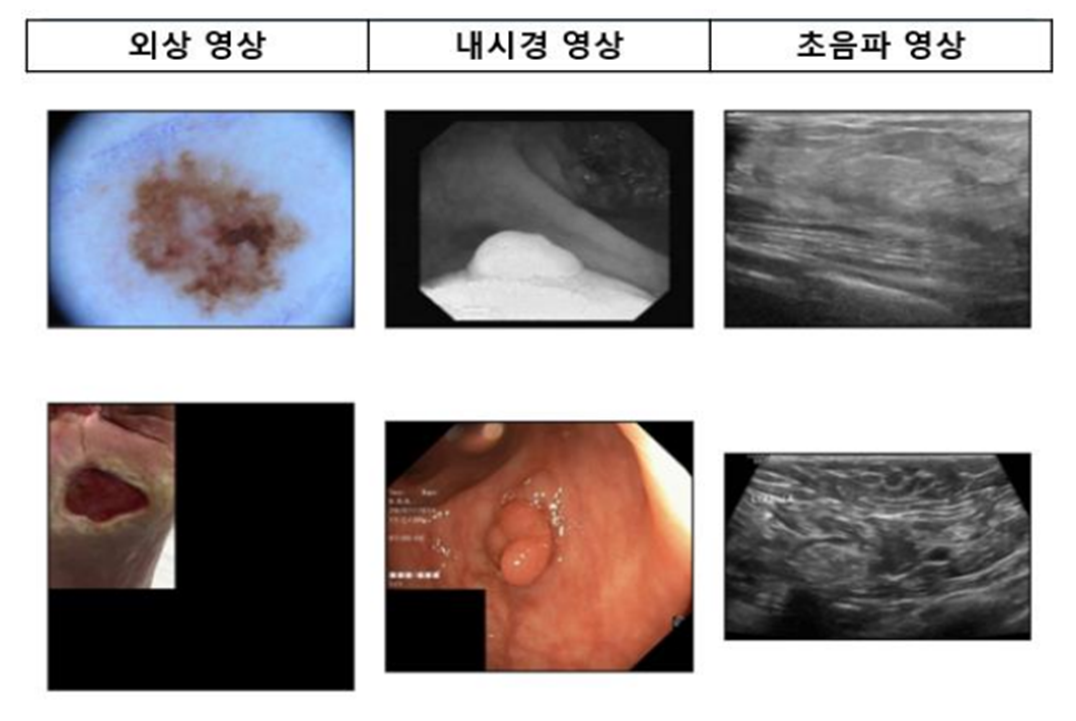
위 데이터들과 같이 모두 의료 영상 데이터이지만 해상도, 영상 내 패딩, 컬러 스케일 등등 큰 차이가 있으며, feature 역시 전부 다름을 확인할 수 있다.
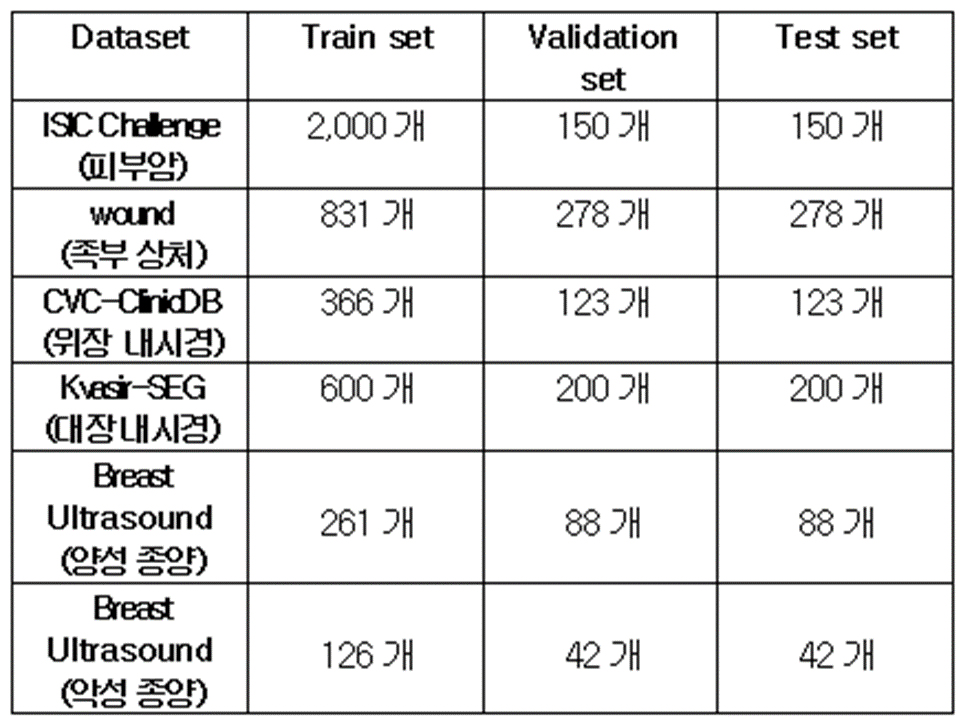
데이터가 모두 해상도가 다르기 때문에 실험을 위해 해상도는 224 * 224 로 고정하였으며, 다른 데이터에 비해 개수가 많은 ISIC Challenge 데이터를 제외하고는 모두 Train : Validation : Test = 6 : 2 : 2 로 설계하였다.
Model
이번 실험이 각각의 의료영상 데이터에 적합한 딥러닝 모델을 위한 것이기에 다양한 종류의 모델들이 필요했다. 모델을 선택하기 위해 총 3가지 기준을 정하였으며, 각 기준에 맞는 모델 3가지를 선정하였다.
1. 의료 영상 외 다양한 분야에서 인기 있는 모델
- FCN
- SegNet
- DeepLab V3+
2. 의료 분야에서 인기 있는 모델
- UNet
- UNet++
- Conlon SegNet
3. 비전 트랜스포머 기반 모델
- FCBFormer
- ESFPNet
- Colon Former
FCN :
https://paperswithcode.com/method/fcn
SegNet :
https://paperswithcode.com/method/segnet
DeepLab V3+ :
https://github.com/VainF/DeepLabV3Plus-Pytorch
UNet :
https://paperswithcode.com/paper/u-net-convolutional-networks-for-biomedical
UNet++ :
https://paperswithcode.com/paper/unet-a-nested-u-net-architecture-for-medical
Conlon SegNet :
https://paperswithcode.com/paper/real-time-polyp-detection-localisation-and
FCBFormer :
https://paperswithcode.com/paper/fcn-transformer-feature-fusion-for-polyp
ESFPNet :
https://paperswithcode.com/paper/esfpnet-efficient-deep-learning-architecture
Colon Former :
https://paperswithcode.com/paper/colonformer-an-efficient-transformer-based
Loss & Metric & Optimizer
이번 실험은 병변인 영역과 병변이 아닌 영역만을 분할한다. 이와 같이 이진 분류에서 자주 사용되는 f1 score와 비슷하면서도 영역 분할 분야에서 자주 사용되는 Dice Score를 평가지표로 사용하였다.

손실 함수는 이진 분류 문제에 많이 사용되는 Binary Cross Entropy에 Dice Score를 더해 준 Dice BCELoss를 사용하여 영상 내 병변 영역에 대한 학습 효율을 높이도록 설계하였다.

옵티마이저의 경우 모두 Adam을 사용하였으며 Batch size 8, learning rate 1e-4, weight decay 1e-8으로 적용하였다.
또한 epoch은 100으로 설정하였으며 학습 도중 validation set에 대해 Dice score가 20 epoch동안 개선되지 않으면, 학습을 종료하도록 Early Stopping을 적용하였다.
Result
성능 비교는 위에서 언급한대로 Dice Score를 기준으로 비교하였다.

실험 결과 전체 데이터에서 대부분 FCBFormer 모델이 좋은 성능을 보였다. 또한 VIT기반 모델 3개가 다른 모델들에 비해 좋은 성능을 보였으며, Wound 데이터에 한해서만 SegNet 모델이 최고 성능을 보여주었다.
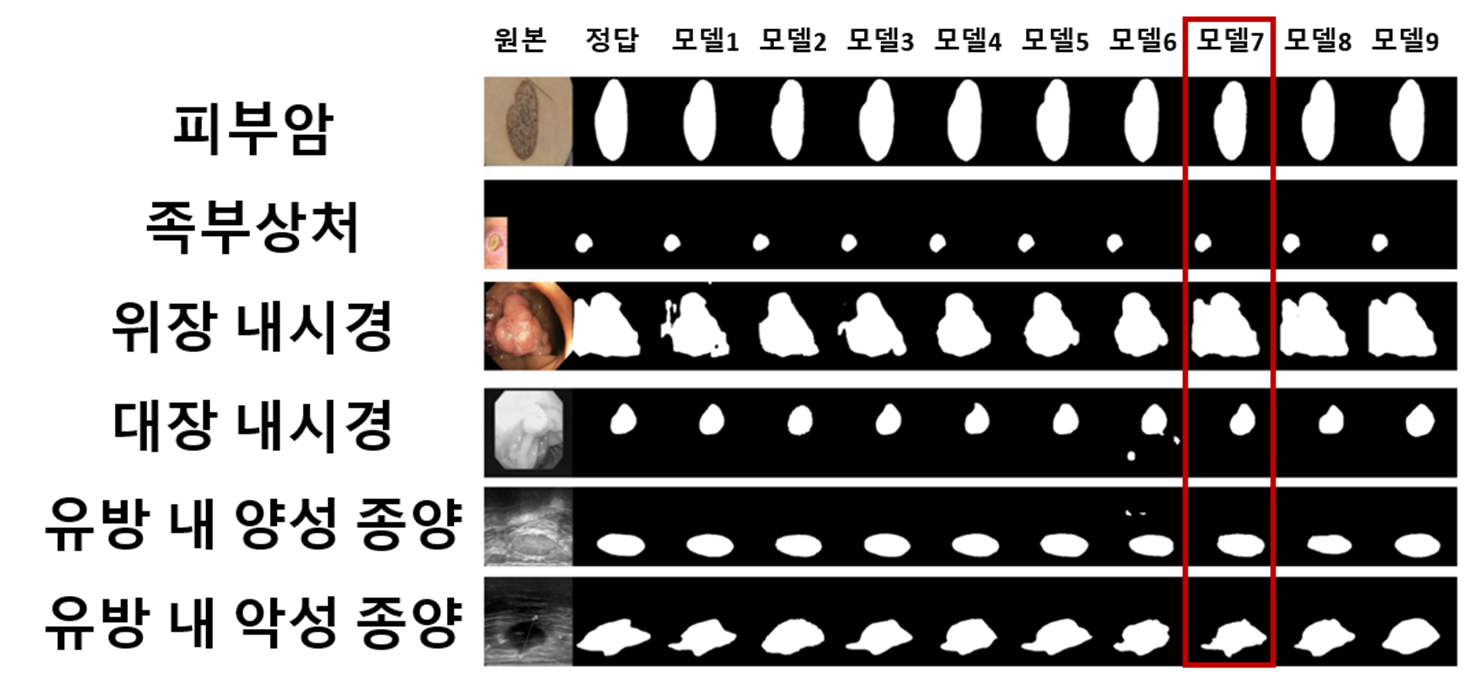
Wound 데이터는 다른 데이터들과 다른 차이점이 존재했다. Wound 데이터를 제외한 나머지 데이터들은 따로 padding처리가 되지 않았던 반면 Wound 데이터만 유일하게 padding처리가 되어있었다. 그렇다면 왜 VIT기반 모델은 패딩처리가 된 데이터에 약한 모습을 보였던 걸까?
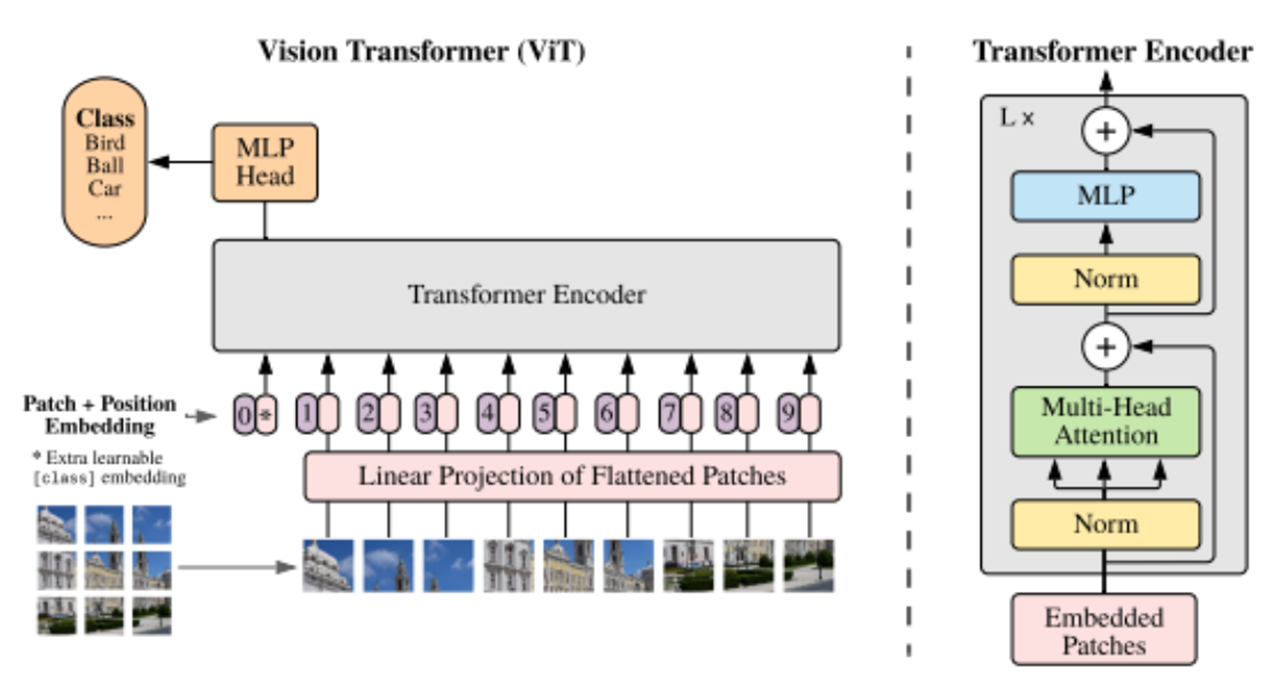
최근 transfomer기반 모델들이 여러 인공지능 분야에서 높은 성능을 자랑하고 있다.
VIT 모델은 학습 데이터로 들어온 이미지를 여러 patch로 나누어 Flatten을 한 후 Transfomer Encoder로 들어간다. 여기에 padding 처리가 된 데이터의 성능이 좋지 않은 이유를 추측할 수 있다. 데이터의 대부분이 padding처리가 되어버리면 CNN기반 모델의 경우 이미지의 feature를 Convolution의 과정을 거쳐 학습을 하지만 transfomer기반 모델인 경우 정보가 없는 patch들이 대거 생길 수 있고 이는 성능 하락으로 이어진다고 볼 수 있다.
실험 결과를 생각해보면 FCBFormer 모델처럼 다양한 데이터에 대해 좋은 성능을 보인 모델이 분명 존재했다. 하지만 Wound 데이터와 같이 특정 데이터에 대해 잘 작동되는 데이터가 존재할 수 있기 때문에 여러 데이터에 대해 다양한 모델들을 학습하여 성능을 비교하는 것은 분명 필요해보인다.
'프로젝트' 카테고리의 다른 글
| pyautogui로 카카오톡 예약 메세지 보내기 (0) | 2023.08.14 |
|---|---|
| [OpenCV] OpenCV를 이용한 얼굴 감지 CCTV 만들기 (0) | 2023.01.10 |
| [OpenCV] OpenCV를 이용한 스캐너 만들기 (0) | 2023.01.09 |
| [딥러닝] KLUE 데이터를 활용한 북마크 분류문제의 해결 (0) | 2023.01.06 |
| [머신러닝] 시계열 데이터 - 농산물 가격 예측 (0) | 2022.11.07 |



