
- 분류 전체보기 (123)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- Self-supervised
- 논문리뷰
- Segmentation
- opencv
- 논문 리뷰
- Semantic Segmentation
- 머신러닝
- 알고리즘
- Ai
- Computer Vision
- cnn
- ViT
- 코드구현
- 프로그래머스
- Python
- optimizer
- 논문
- transformer
- object detection
- 파이썬
- Convolution
- 논문구현
- Paper Review
- pytorch
- 옵티마이저
- programmers
- 파이토치
- 코딩테스트
- 딥러닝
- Today
- Total
Attention please
Dilated Convolution(Atrous convolution) 원리 및 Pytorch 구현 본문
다양한 convolution 기법들
- original convolution
- Transposed convolution
- separable & depthwise & pointwise convolution
- depthwise separable convolution
CNN 모델은 input data 와 kernel을 convolution하여 feature를 추출한다.
일반적인 Convolution 기법은 다음과 같다.

하지만 object detection이나 object segmentation과 같은 경우 객체 주변이나 주위의 환경에 대해 판단하기 위해 contextual information을 확보하는 것이 중요한데 이를 위해서는 더 넓은 receptive field를 고려해야한다.
하지만 기존의 Convolution 기법으로 receptive field를 확장시키기 위해서는 kernel의 크기를 늘리거나 layer의 개수를 늘려야 했는데 이는 연산량의 큰 증가로 효율적인 방법이 될 수 없었다.
고로 연산량은 크게 증가시키지 않으면서도 유의미한 정보를 추출하기 위해 다양한 Convolution기법들이 소개되었는데 그 중에서도 이번 글에서는 Dilated Convolution(Atrous convolution) 에 대해 알아보자.
Dilated Convolution
Dilated Convolution은 위 그림처럼 kernel 내부에 zero padding을 추가한다. kernel의 크기는 3x3 이며, dilation rate는 2인 것을 볼 수 있는데 이는 5x5 kernel과 동일한 view를 가지지만 9개의 파라미터만을 사용한다.
이와 같이 적은 파라미터의 수로 보다 넓은 view를 가질 수 있도록 하는데 이는 넓은 시야가 필요하지만 모델의 size는 줄여야하는 real-time segmentation 에서 자주 사용된다. 넓은 receptive field를 가질 수 있는 동시에 효율적으로 contextual information을 확보하는 것이 가능하기 때문에 Segmentation에 유리하다.
또한 receptive field를 크게 가져가기 위해 pooling층을 사용하는데 이는 spatial dimension 손실이 난다. 하지만 dilated convolution은 이러한 spatial dimension 손실을 줄일 수 있고 또 대부분의 가중치 값들이 0이기 때문에 연산에 있어서도 좋은 효율을 낸다.
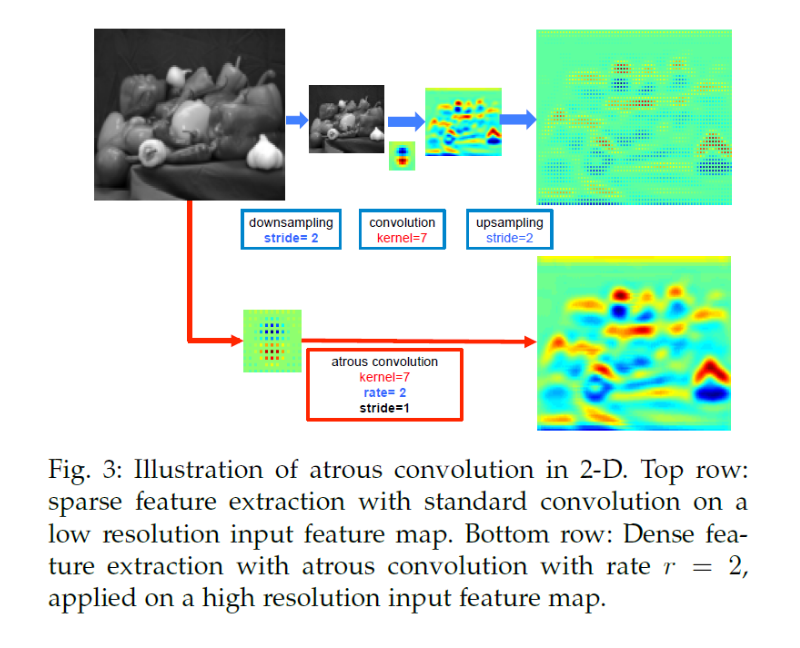
위 그림을 보면 상단에 있는 것이 pooling -> convolution을 통해 down sampling을 한 후 Upsampling을 하는 것이고 하단에 있는 것이 Dilated Convolution을 하는 것이다. 전자의 경우 Upsampling을 하면서 spatial dimension 손실이 발생하여 해상도가 떨어진다.
하지만 Dilated Convolution의 경우 Receptive Field는 크게 가져가는 동시에 spatial dimension 손실 역시 최소화하기 때문에 높은 해상도의 output을 얻을 수 있다.
따라서 Dilated Convolution은 Segmentation, Object Detection과 같이 Contextual information이 중요한 분야에 자주 사용된다.
코드 구현
파이토치로 Dilated Convolution을 구현하는 것은 단순히 torch.nn.Conv2d 함수의 dilation 파라미터 값만 바꾸어 주면 된다. kernel size가 3x3이면서 kernel 사이 간격이 2이고 padding이 0인 convolution은 다음과 같이 구현할 수 있다.
import torch.nn as nn
nn.Conv2d(in_channels=1, out_channels=3, kernel_size=3, stride=1, dilation=2)
'딥러닝 > CNN' 카테고리의 다른 글
| Separable & Depthwise & Pointwise Convolution 원리 및 Pytorch 구현 (0) | 2022.12.30 |
|---|---|
| Transposed Convolution 원리 및 Pytorch 구현 (0) | 2022.12.30 |
| [딥러닝] im2col의 원리, im2col을 이용한 합성곱 (0) | 2022.12.10 |
| [딥러닝] Max Pooling의 원리, 합성곱층과 max pooling층의 차이 (0) | 2022.12.10 |
| [딥러닝] 텐서의 합성곱의 원리, CNN - 합성곱신경망 (0) | 2022.12.09 |



