
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Self-supervised
- opencv
- 코딩테스트
- 코드구현
- 프로그래머스
- Computer Vision
- Convolution
- pytorch
- 파이썬
- 논문리뷰
- 논문
- 머신러닝
- ViT
- Python
- 알고리즘
- Ai
- Segmentation
- 논문구현
- cnn
- 인공지능
- optimizer
- 파이토치
- 논문 리뷰
- transformer
- 딥러닝
- Paper Review
- 옵티마이저
- programmers
- object detection
- Semantic Segmentation
- Today
- Total
Attention please
[딥러닝] Max Pooling의 원리, 합성곱층과 max pooling층의 차이 본문
2022.12.09 - [딥러닝/CNN] - 텐서의 합성곱
텐서의 합성곱
2022.12.09 - [딥러닝/CNN] - 이미지와 텐서, 전치(transpose) 이미지와 텐서, 전치(transpose) CNN(합성곱 신경망) 앞으로 다룰 CNN - Convolution Neural Network 은 컴퓨터 비전 즉 이미지를 처리하는데 특화되어있다
smcho1201.tistory.com
합성곱 신경망(CNN)을 구성하는 요소는 총 3가지가 있다.
- Affine - ReLu - Affine - softmax - CrossEntropy
- 합성곱층(Convolution)
- max pooling
저번 글에서는 위 3가지 요소중 합성곱층에 대해 알아보았으며, 이번 글에서는 max pooling에 대해 알아보자.
Max Pooling이란 무엇인가?
Max Pooling은 합성곱층과 같이 데이터로 들어온 텐서에 대해 stride를 기준으로 결과값인 텐서를 도출한다.
계산 방식만 보면 이 둘은 비슷해보이지만 큰 차이가 있다. 합성곱층은 입력데이터와 필터를 내적하여 스칼라 값을 도출하지만 max pooling은 입력데이터에서 필터 크기에 맞는 값들 중 최대값을 가져온다.
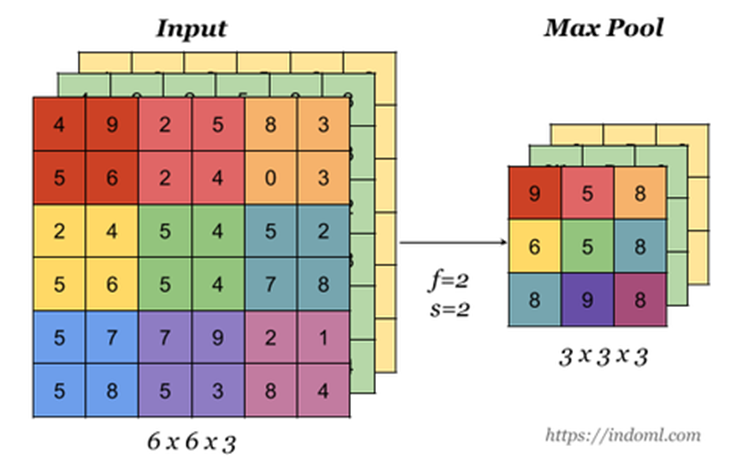
- 입력 데이터 : N x C x H x W
- 출력 데이터 : N x C x OH x OW
max pooling의 큰 특징은 따로 필터가 존재하는 것이 아닌 채널별로 독립적으로 시행한다는 것이다. 물론 max pooling에도 filter와 stride값이 존재하기는 하지만 합성곱층처럼 채널별로 스칼라값을 도출하여 더하는 식의 상호작용이 없기 때문에 학습해야할 파라미터인 필터와 편향이 존재하는 합성곱층과 다르게 max pooling은 학습해야할 매개변수가 존재하지 않는다는 것을 의미한다.
입력 데이터와 출력 데이터의 축을 보면 배치개수인 N은 합성곱층과 같이 동일하지만 max pooling의 경우 채널별로 독립적으로 시행되기 때문에 채널의 수가 계속 변하는 합성곱층과 다르게 출력 데이터의 채널의 수가 C 그대로인 것을 확인할 수 있다. (합성곱층의 경우 출력 데이터의 채널은 C가 아닌 FN이다)
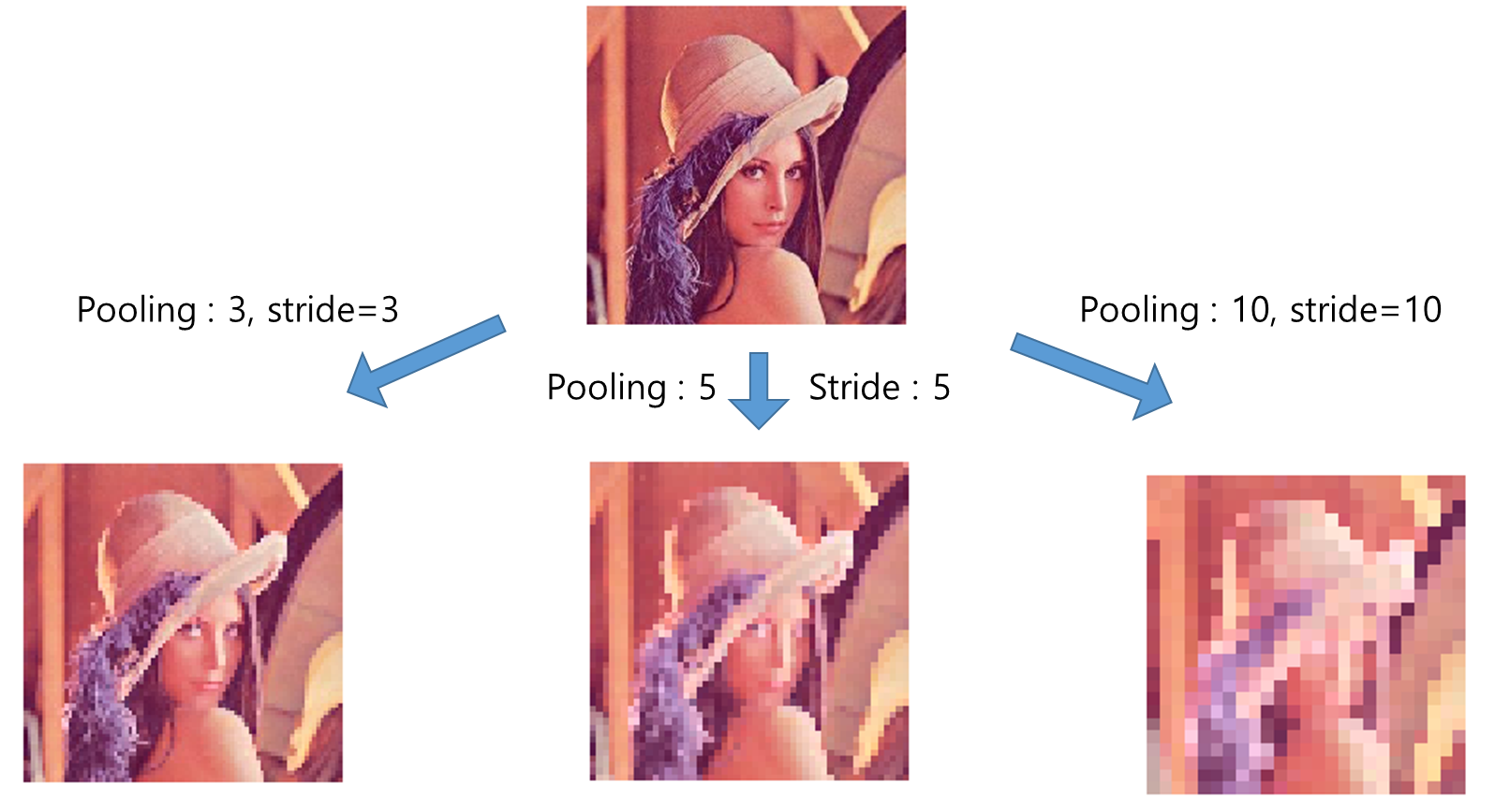
Max Pooling층을 지나면 Dawn Sampling을 하게 된다. 정해진 filter의 크기에서 해상도를 가장 큰 값인 픽셀값 1개로 줄이기 때문에 입력데이터가 max pooling층을 지나게 되면 마치 모자이크를 한 것처럼 보인다.
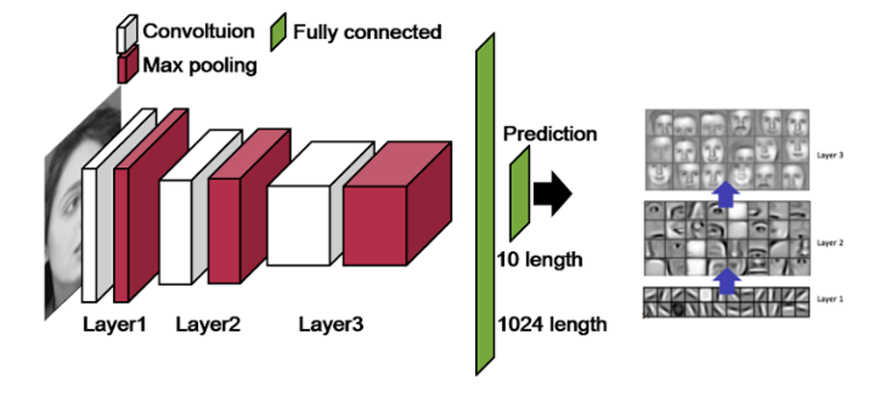
합성곱 신경망은 합성곱층과 max pooling층이 반복된 후 fully-connected layer이 등장하는 구조로 이루어진다.
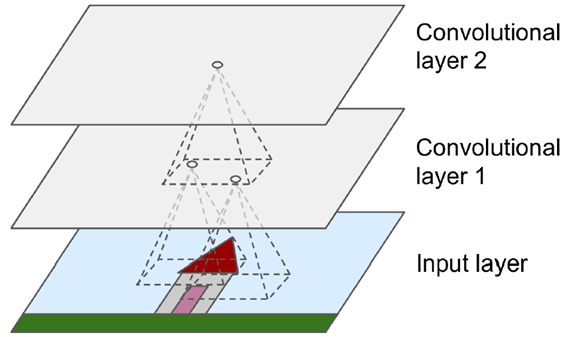
합성곱층의 필터들은 학습 시작전에는 랜덤하게 생성되며 학습데이터를 통해 학습을 하면서 손실함수 값이 낮아지도록 필터를 훈련시킨다. 충분히 학습이 이루어지게 되면 낮은 층의 필터는 저수준의 local한 특징을 찾아내고, 층이 높아질수록 더 고수준의 global한 특징을 찾아내게 된다.
예를 들어 사람 얼굴이 데이터로 들어오게 되면 층이 높아질수록 (단순패턴 -> 눈,코,입,눈썹,귀 -> 얼굴 전체) 와 같이 더 global한 특징을 찾게 된다.
합성곱층 vs Max Pooling층
CNN을 구성하는 층들 중 합성곱층과 max pooling층은 비슷하면서도 큰 차이를 가진다.
- 합성곱층 -
- 필터와 편향을 학습시킨다.
- 입력데이터의 채널이 사라진다. (입력데이터 : N x C x H x W / 출력데이터 : N x FN x OH x OW)
- 필터를 훈련시켜 낮은 층의 필터는 저수준의 local한 특징을 찾고, 높은 층의 필터는 고수준의 global한 특징을 찾는 것을 목표로 한다.
- Max Pooling -
- 학습시킬 parameter가 없다.
- 채널별로 독립적으로 시행한다. (입력데이터 : N x C x H x W / 출력데이터 : N x C x OH x OW)
- Dawn Sampling을 통해 다음 합성곱층에서 더 빨리 global한 특징을 찾을 수 있도록 도와주고, 파라미터의 수를 줄여서 계산비용을 줄여주며 overfitting을 억제한다. 또한 약간의 평행이동에 대해 변하지 않도록 한다.

'딥러닝 > CNN' 카테고리의 다른 글
| Transposed Convolution 원리 및 Pytorch 구현 (0) | 2022.12.30 |
|---|---|
| Dilated Convolution(Atrous convolution) 원리 및 Pytorch 구현 (0) | 2022.12.30 |
| [딥러닝] im2col의 원리, im2col을 이용한 합성곱 (0) | 2022.12.10 |
| [딥러닝] 텐서의 합성곱의 원리, CNN - 합성곱신경망 (0) | 2022.12.09 |
| [딥러닝] 이미지와 텐서의 관계, 전치(transpose) - CHW, HWC (0) | 2022.12.09 |



