
- 분류 전체보기 (130)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- optimizer
- Segmentation
- Computer Vision
- 논문 리뷰
- Self-supervised
- 논문리뷰
- 코딩테스트
- Ai
- Convolution
- 프로그래머스
- programmers
- 딥러닝
- Semantic Segmentation
- 알고리즘
- cnn
- 논문
- 머신러닝
- ViT
- 파이썬
- transformer
- 인공지능
- Python
- 강화학습
- object detection
- 옵티마이저
- 파이토치
- pytorch
- opencv
- 논문구현
- 코드구현
- Today
- Total
Attention please
[딥러닝] 텐서의 합성곱의 원리, CNN - 합성곱신경망 본문
2022.12.09 - [딥러닝/CNN] - 이미지와 텐서, 전치(transpose)
이미지와 텐서, 전치(transpose)
CNN(합성곱 신경망) 앞으로 다룰 CNN - Convolution Neural Network 은 컴퓨터 비전 즉 이미지를 처리하는데 특화되어있다. 즉, 이미지를 학습을 한다는 것인데 컴퓨터에 학습시키기 위해서는 데이터를 수
smcho1201.tistory.com
저번 글에서는 학습을 할 이미지가 텐서로 구성됨을 보였으며, 학습을 위한 전처리 방법 중 하나인 전치(transpose)에 대해 알아보았다. 이번 글에서는 CNN의 핵심이라 할 수 있는 합성곱이 어떻게 이루어지는지 알아보자.
합성곱(Convolution)이란 무엇인가?
앞에서 다루었던 Affine층으로 이루어진 fully connected layer 은 텐서를 flatten을 하여 1차원으로 차원을 줄이고 학습을 진행한다. 하지만 이미지는 인접해있는 픽셀과 픽셀의 정보 즉, locality한 정보를 가진다. 하지만 flatten을 하는 순간 locality한 정보는 모두 사라지게 되는 문제가 있다.

이러한 이유로 Affine층으로만 이루어진 기본 DNN은 이미지를 확대하거나 회전하는 등의 변형에 취약한 모습을 보였다.

또한 픽셀수가 많은 고해상도 이미지를 학습할 때는 파라미터의 수가 급격하게 많아져 막대한 계산비용과 오버피팅을 초래한다는 문제가 있었다.
이런 단점들을 보완하기 위해 나온 것이 Convolution Neural Network(합성곱 신경망)이다.
Frobenius inner product
합성곱에는 다양한 방법들이 존재한다. 그 중 가장 일반적으로 쓰이는 Frobenius 방법을 알아보자.
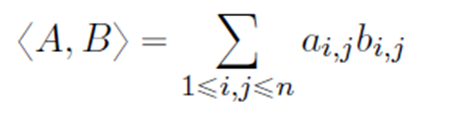
Frobenius 내적은 같은 축의 위치에 있는 원소들끼리 곱한 후 그 값들을 모두 더하는 방식으로 진행된다.
예를 들어 다음과 같은 행렬 2개에 대해 합성곱을 적용시켜 보자.
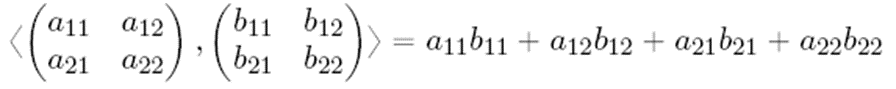
다음과 같이 같은 축의 위치에 있는 원소들 끼리 곱하여 더해지는 것을 볼 수 있다.
행렬의 합성곱
이미지는 흑백 이미지인 행렬과 컬러 이미지인 3차원 텐서가 존재하는데 이번에는 행렬에 대해 알아보자.
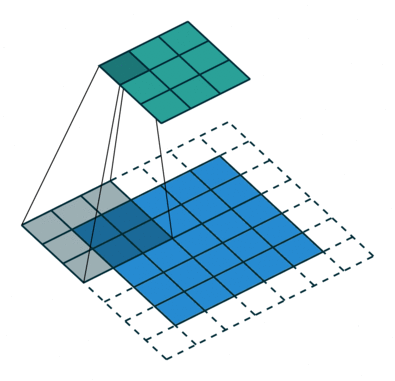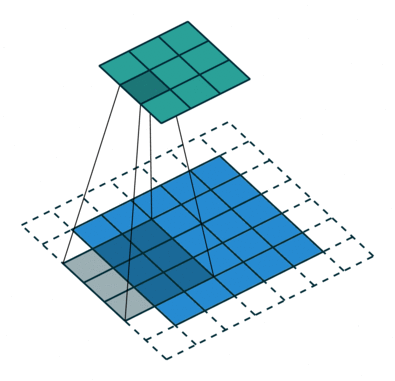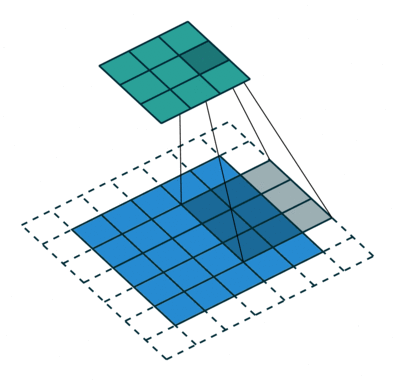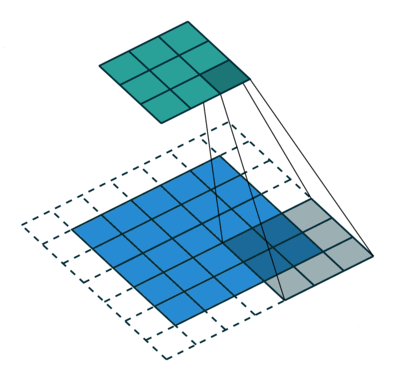
CNN에는 Filter가 존재한다. Filter는 학습데이터로 들어온 이미지 행렬과 합성곱을 하는데 이때 이 Filter의 size에 따라 합성곱의 결과가 달라지게 된다.
또한 Padding은 데이터 주위를 0값으로 감싸주는 것으로 계산이 원할히 되도록 도와주는 역할을 한다.
마지막으로 stride는 필터가 움직이는 칸수를 의미한다.
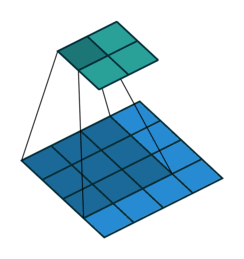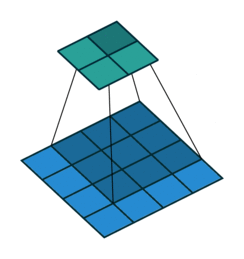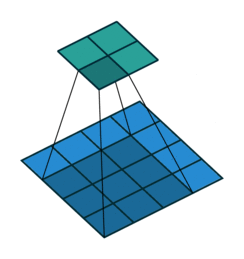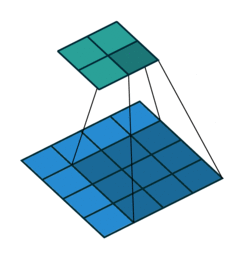
- Filter : 3 x 3
- Padding : 0
- stride : 1

- Filter : 4 x 4
- Padding : 2
- stride : 1
- Filter : 3 x 3
- Padding : 1
- stride : 2
다음과 같이 Filter, Padding, stride 값에 따라 합성곱의 결과가 달라지는 것을 볼 수 있다.
이번에는 직접 계산을 해보자.
| 1 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 1 |
다음과 같은 Filter를 생각하자.
Filter : 3 x 3 , padding : 0 , stride : 1 의 파라미터를 가진 합성곱을 진행하면
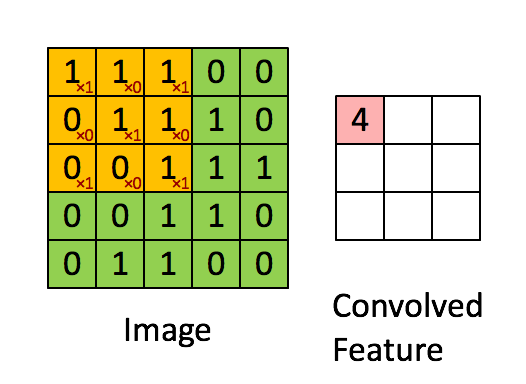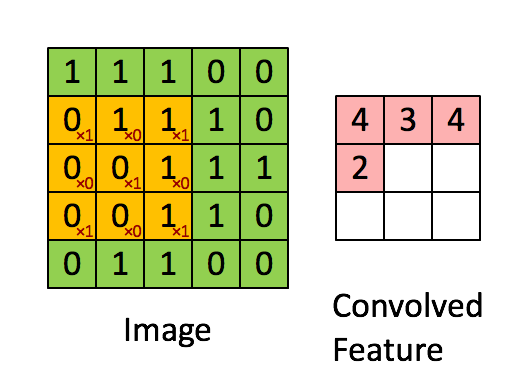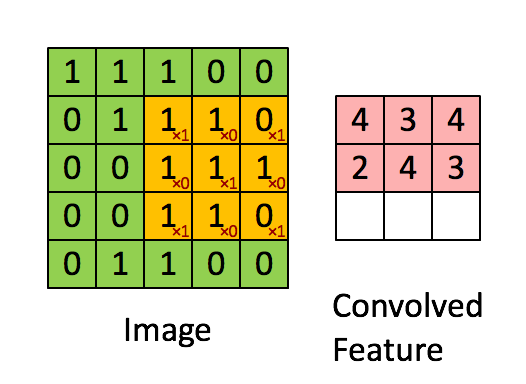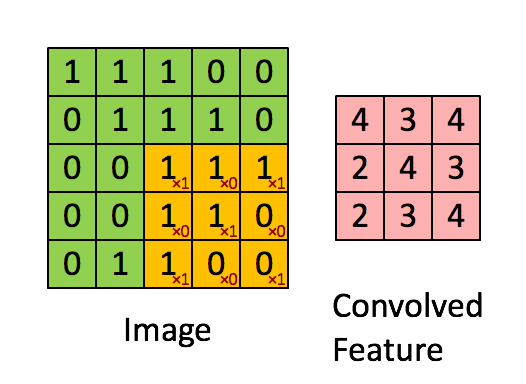
다음과 같은 결과가 나오게 된다.
합성곱 출력 크기
다음은 Image를 합성곱한 결과의 size를 구하는 공식이다.
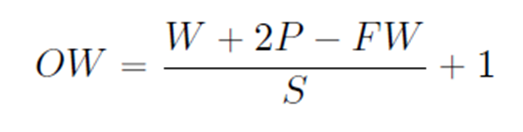
- W(Width) : 입력하는 이미지 행렬의 가로 해상도
- P(Padding) : 주위에 0이 채워지는 줄의 개수
- FW(Filter Width) : Filter의 가로 해상도
- S(Stride) : 필터의 움직이는 칸 수
- OW(Output Width) : 합성곱을 하여 출력된 행렬의 가로 해상도
텐서의 합성곱
위에서 하였던 행렬의 합성곱은 흑백 이미지(행렬)에 대한 합성곱이다. 이번에는 컬러 이미지(텐서)의 합성곱에 대해 알아보자. 텐서의 합성곱은 다음과 같이 이루어진다.
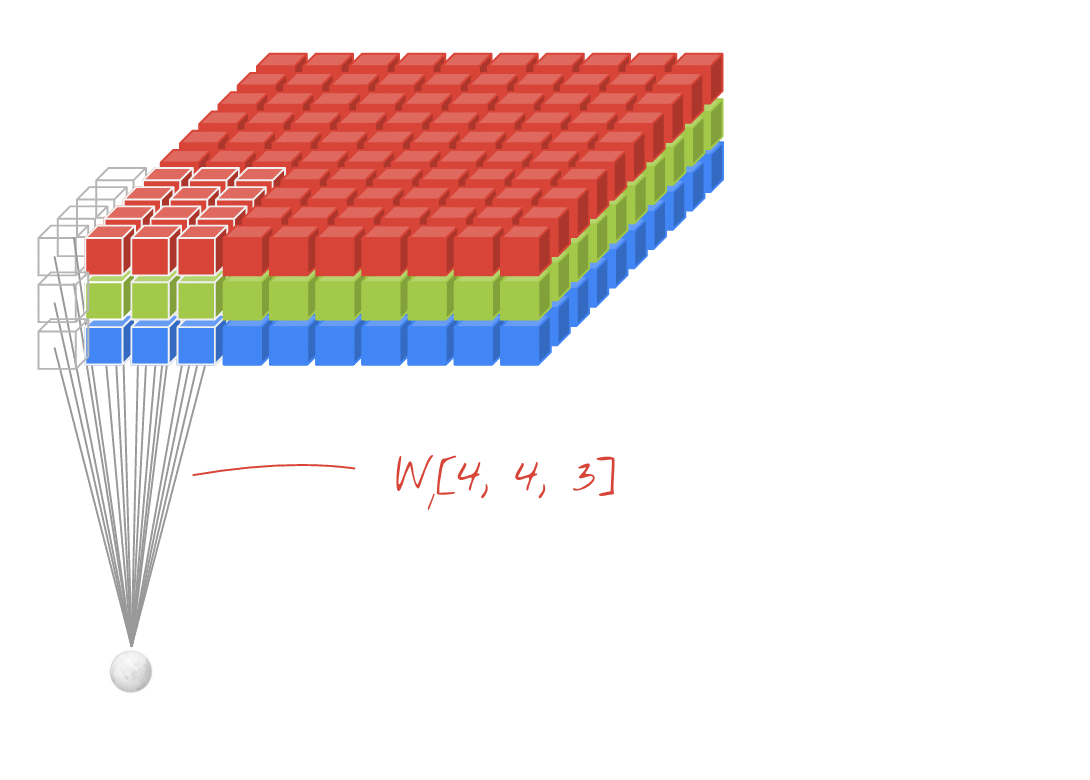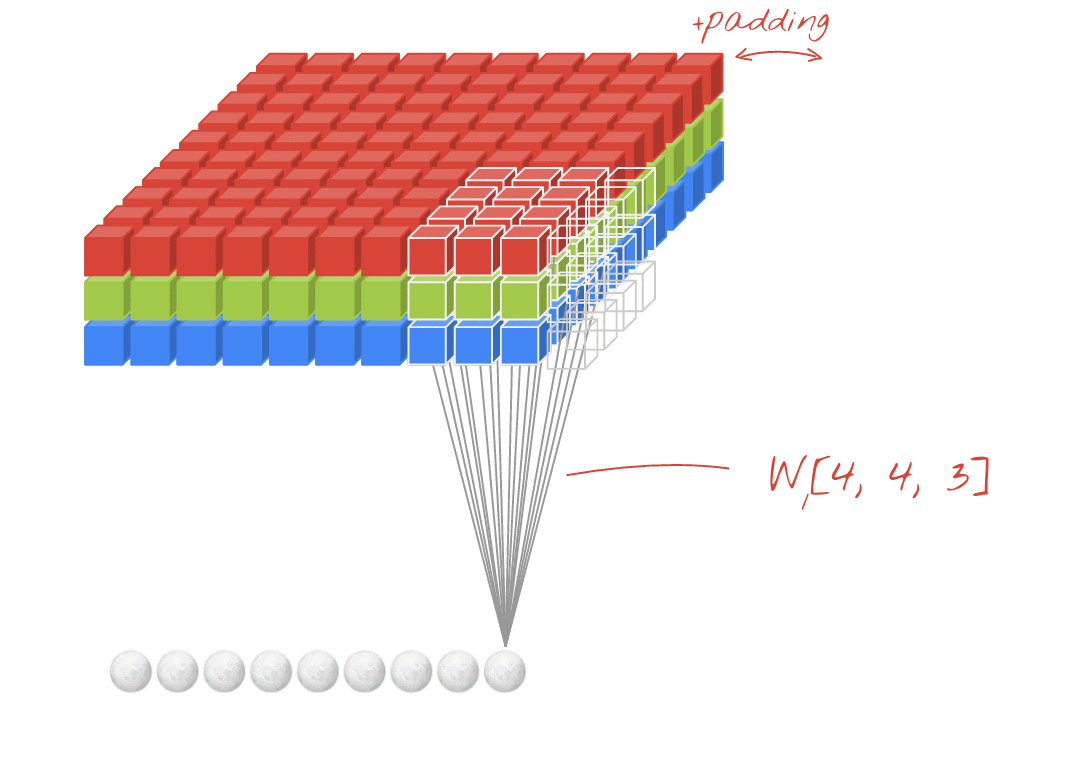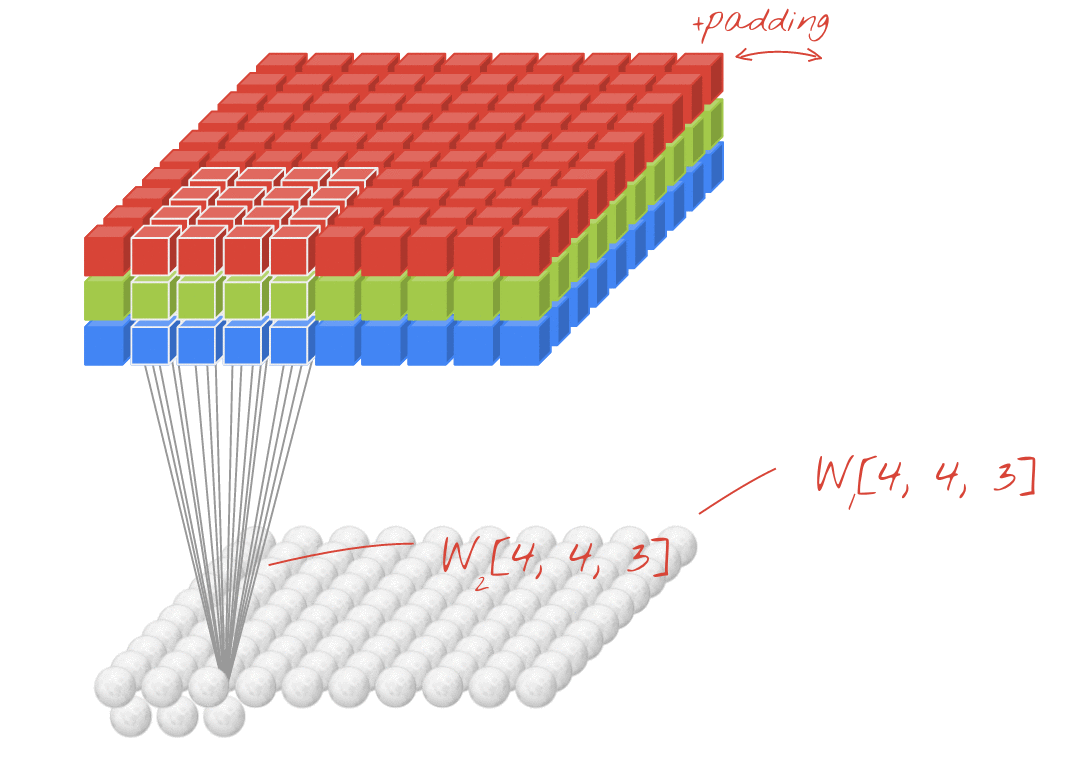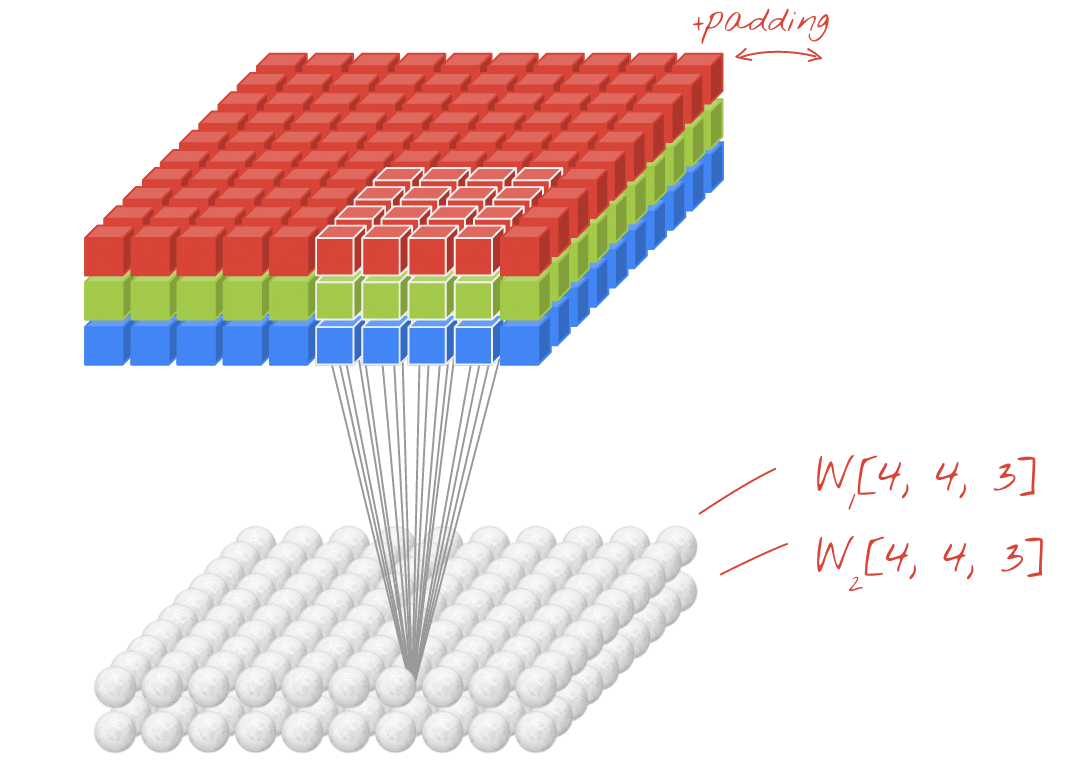
텐서의 합성곱 역시 행렬의 합성곱처럼 필터와 그 필터에 대응하는 텐서와 내적하여 나온 스칼라 값들로 하나의 행렬을 도출한다. 또한 하나의 필터로는 텐서에 대한 다양한 정보들을 찾기 어렵다. 즉, 여러개의 필터를 사용하여 locality한 정보를 찾는다. 물론 여러개의 필터를 사용하는만큼 필터의 차원수만큼 결과값의 차원수가 생긴다. 예를 들어 30개의 필터를 사용하였다면 결과값의 차원수는 30개가 된다.
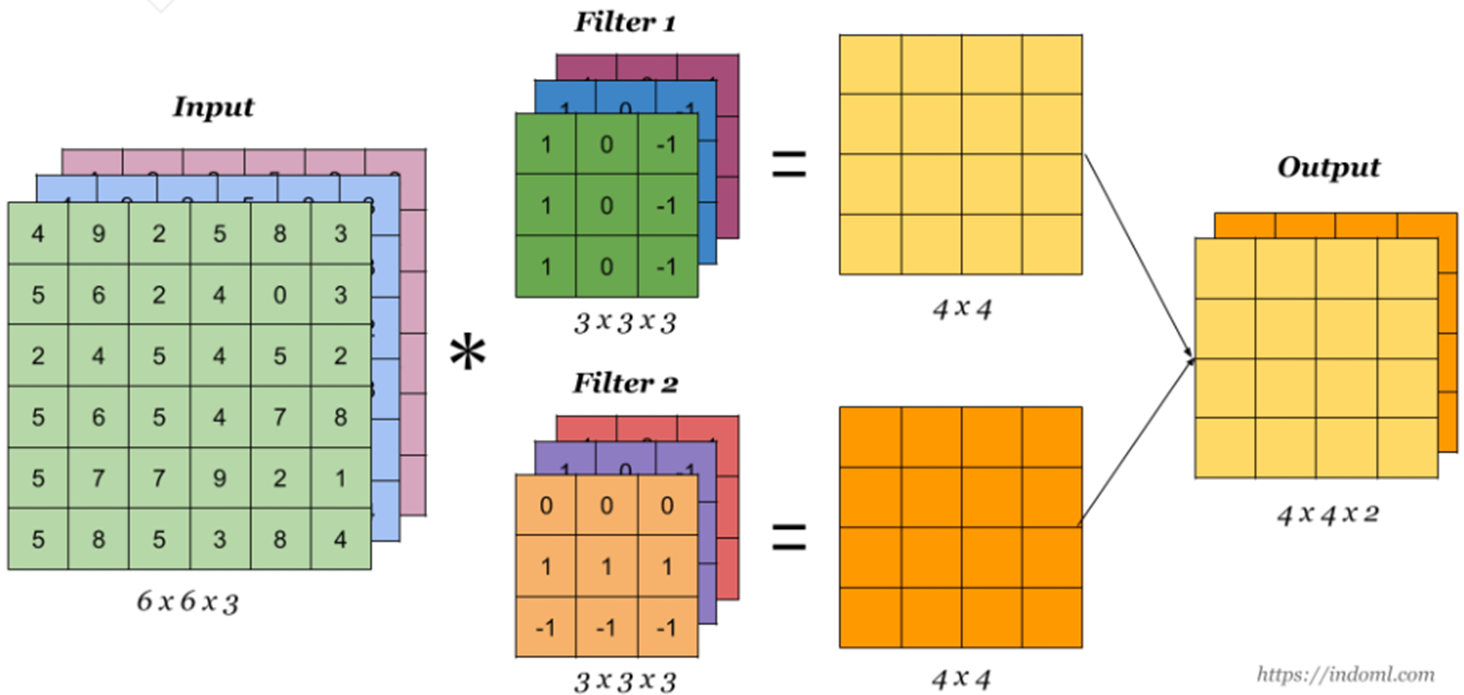
- Filter : 3 x 3 x 3
- Padding : 0
- stride : 1
- Channel : 3
- Filter Number : 2
3차원 텐서의 합성곱
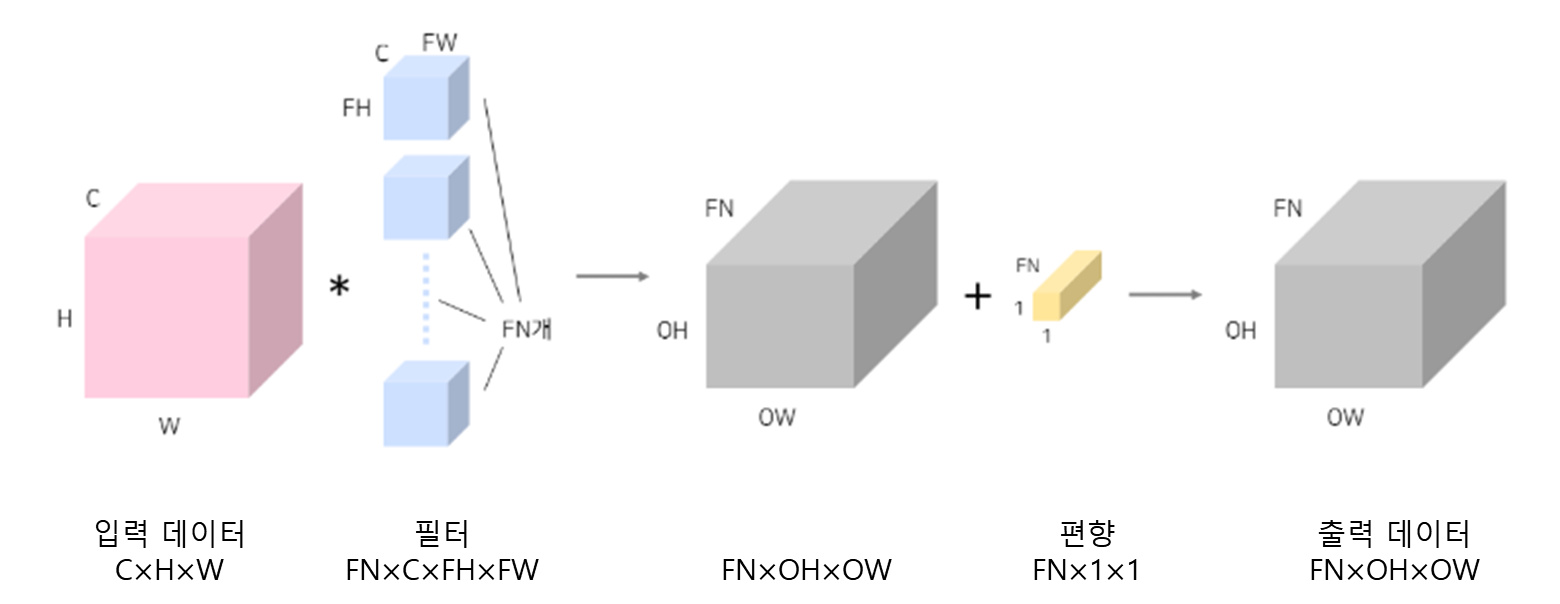
항상 입력데이터의 채널 수와 필터의 차원 수는 같아야 하며, 필터 1개가 OH x OW 사이즈의 행렬 1개를 만든다. 즉, 필터의 개수가 FN이기 때문에 합성곱을 하여 나온 텐서의 차원수 역시 FN이다.
4차원 텐서의 합성곱
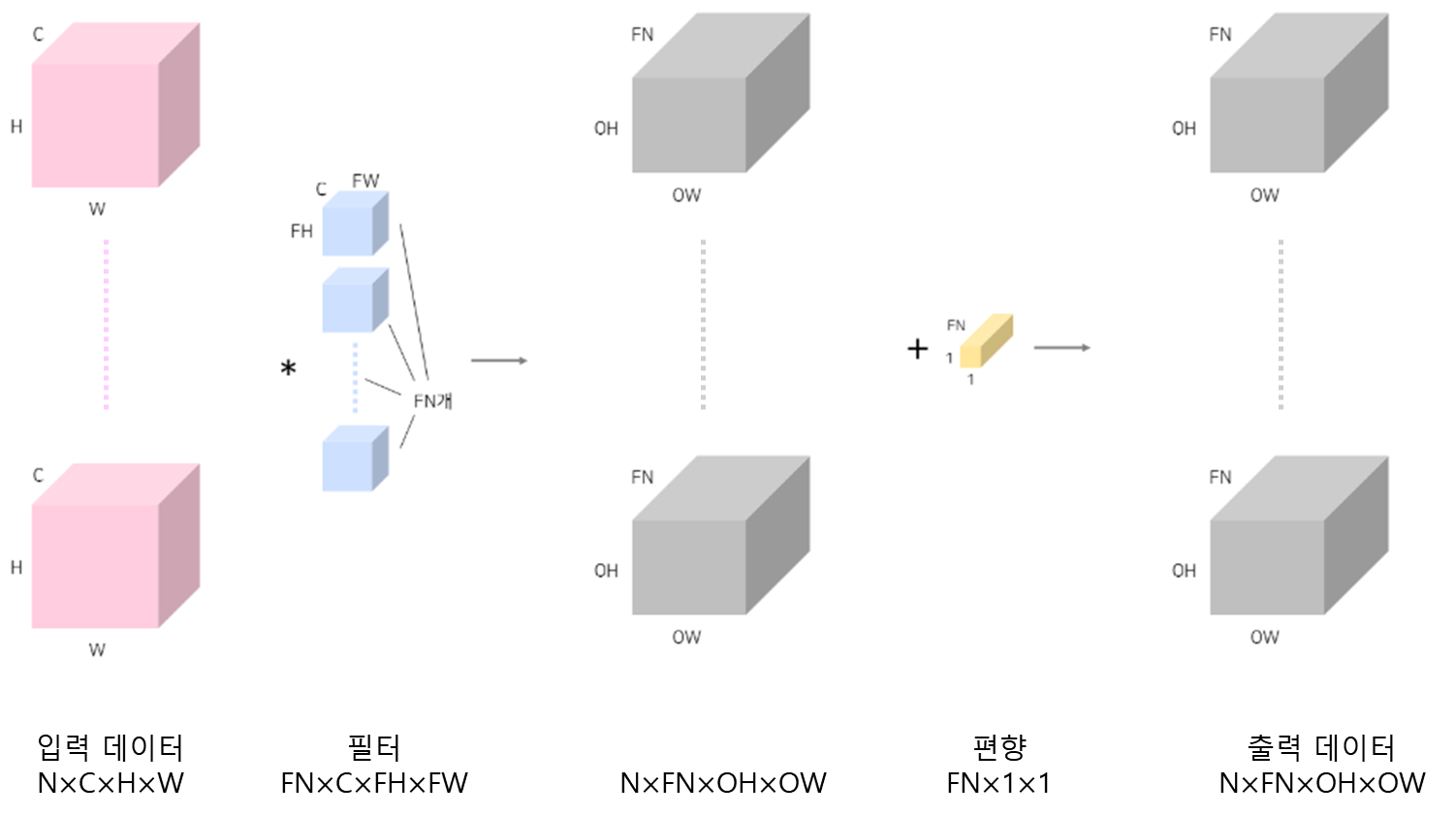
컬러 이미지 1장은 3차원 텐서이다. 이런 컬러 이미지가 여러 장 묶인 배치를 학습할때는 4차원 텐서를 학습하게 된다. 입력 데이터의 늘어난 N개만큼 합성곱을 한 결과인 출력 데이터의 개수 역시 N개가 된다.
CNN의 핵심은 합성곱이다. 기존 신경망은 데이터를 flatten하여 학습하기에 locality한 정보를 학습하는데 어려움이 있었고 이를 해결하기 위해 Convolution을 하였다. 예를 들어 Mnist데이터와 같이 손글씨에도 직선, 곡선, 꺽여짐과 같은 local한 특징들이 존재하는데 합성곱을 통해 이러한 특징들을 학습할 수 있게 되는 것이다. 즉, 이미지와 합성곱을 하는 Filter가 얼마나 완성도가 있는지에 따라 성능이 결정된다. 처음 CNN의 Filter의 값은 랜덤으로 주어지지만 데이터를 학습하면서 Filter를 학습하게 되고 가장 이상적인 Filter를 찾아내게 되면서 이미지들의 locality한 정보를 추출할 수 있게 된다.
'딥러닝 > Computer Vision' 카테고리의 다른 글
| Transposed Convolution 원리 및 Pytorch 구현 (0) | 2022.12.30 |
|---|---|
| Dilated Convolution(Atrous convolution) 원리 및 Pytorch 구현 (0) | 2022.12.30 |
| [딥러닝] im2col의 원리, im2col을 이용한 합성곱 (0) | 2022.12.10 |
| [딥러닝] Max Pooling의 원리, 합성곱층과 max pooling층의 차이 (0) | 2022.12.10 |
| [딥러닝] 이미지와 텐서의 관계, 전치(transpose) - CHW, HWC (0) | 2022.12.09 |



