
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문구현
- pytorch
- 파이토치
- ViT
- 파이썬
- Computer Vision
- optimizer
- 논문리뷰
- 옵티마이저
- 인공지능
- opencv
- 논문
- programmers
- 프로그래머스
- 논문 리뷰
- transformer
- Segmentation
- 코딩테스트
- Paper Review
- 머신러닝
- Convolution
- 알고리즘
- 코드구현
- cnn
- Semantic Segmentation
- object detection
- Self-supervised
- Ai
- Python
- 딥러닝
- Today
- Total
Attention please
[논문 리뷰] SENet(2018), 파이토치 구현 본문
이번에 리뷰할 논문은 "Squeeze-and-Excitation Networks" 이다.
SENet은 2017년 ImageNet 대회에서 우승을 차지한 모델이다. top-error가 2.251%로 사람의 error rate 인 5%보다 적은 수치를 달성하기도 했다.

논문의 제목을 읽어보면 Squeeze(짜내다)와 Excitation(활성화) 한 network라고 한다. 본 논문에서는 기존의 어떤 모델들과도 적용할 수 있는 SE block이라는 것을 제안했는데 이때 이 블럭의 과정이 squeeze하고 excitation을 한다고 하여 SE block이라고 한다.
SE block은 기존 모델인 VGGNet, GoogLeNe, ResNet 에 첨가되어 성능이 향상되는 동시에 하이퍼 파라미터는 많이 늘지 않아서 연산량 증가 없이 모델의 성능을 높일 수 있었다. 이러한 점에서 SE block은 모델의 깊이를 늘려 성능을 높이는 것에 비해 상당히 효율적이라 볼 수 있다.
SE block
SENet은 각 channel 간의 상호작용에 집중하여 성능을 올렸다. 이때 channel간의 상호작용은 가중치로 생각할 수 있는데 이 가중치는 각 channel에 대해 중요한 feature를 담고 있다. 즉, feature map에 각 channel의 가중치들을 각 channel에 곱하여 성능을 끌어올렸다.

위 그림은 SE block의 과정을 보여준다. 먼저 처음 등장하는 X와 U는 feature map이며, Ftr은 convolution이다. H'xW'xC'의 크기를 가진 feature map X는 Ftr convolution을 통해 HxWxC의 크기를 가진 feature map U가 된다. 이때까지는 다른 CNN 모델들과 다를 바 없이 진행된다.
Squeeze
이 다음 SE block이 등장하는데 feature map U에서 squeeze를 실행한다. HxWxC의 feature map을 1x1xC의 feature map으로 변환해주는데 이는 HxW의 2차원 feature map을 1x1의 feature map으로 변환해주는 것이고 이 과정은 global average pooling (GAP)를 통해 각 2차원의 feature map을 평균을 내어 하나의 값으로 변환해 주어 연산할 수 있다.
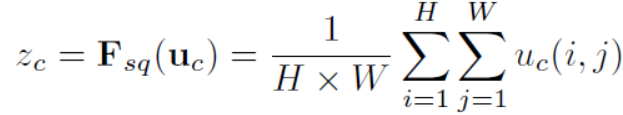
squeeze를 통해 각 channel들을 하나의 값으로 변환하였다. 즉, HxWxC의 feature map을 1x1xC로 squeeze를 해준 것인데 이는 feature map의 global한 정보들이라 볼 수 있다. 즉, convolution을 통해 local한 정보를 다루고 squeeze를 통해 global한 정보를 다룬다고 볼 수 있다.
Excitation
squeeze를 한 후에는 excitation을 한다. excitation을 하는 과정은 2개의 fully-connected layer을 더해준다.

위 수식은 squeeze를 통해 나온 값인 z를 excitation을 하여 s로 추출한다. 들어온 z를 첫 번째 가중치인 W1과 fully-connected 하여 곱한 후 ReLU함수를 적용하여 activation해준다. 그 후에 두 번째 가중치인 W2와 fully-connected 하여 곱한 후 sigmoid 함수를 적용하여 activation 해주어 0~1 의 값으로 나오게 한다.
excitation을 하여 나온 C개의 값들을 feature map U의 각 channel들에 곱하여 나온 feature map을 ~X라고 한다.

Architecture

다음 그림은 SENet의 구조이다. 기존의 ResNet과 ResNeXt 모델에 SE block을 적용한 것을 볼 수 있다.
SE block은 다른 CNN 모델들과 결합하여 사용할 수 있다. VGGNet과 같은 모델은 convolution layer과 activation 을 한 후에 붙여 사용이 가능하다.

또한 GoogLeNet (Inception V1)과 ResNet 모델에 SE block을 붙여 사용하는 것을 볼 수 있다. GoogLeNet의 경우에는 Inception module을 한 후 SE block을 붙여 사용하고, ResNet의 경우 Residual module을 한 후 SE block을 붙여 사용하는 것을 볼 수 있다.
Experiment
ResNet, ResNeXt 등등 여러 모델에 SE block을 적용하였을 때 나온 결과에 대한 표이다. 적용하지 않았을 때에 비해 더 좋은 성능이 나오는 것이 확인된다.

코드 구현
SENet의 핵심인 SE block을 구현해보자.
class SEBlock(nn.Module):
def __init__(self, c, r=16):
super(SEBlock, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(c, c // r, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c // r, c, bias=False),
nn.Sigmoid()
)
def forward(self, input_filter):
batch, channel, _, _ = input_filter.size()
se = self.squeeze(input_filter).view(batch, channel)
se = self.excitation(se).view(batch, channel, 1, 1)
return input_filter * se.expand_as(input_filter)
C는 filter의 channel의 개수이며, r은 reduction ratio로 channel을 얼마나 축소하고 늘릴지에 대한 값이다.
AdaptiveAvgPool함수를 통해 input data를 1x1의 filter로 바꿔준 후 excitation을 통해 fully-connected를 하여 global한 정보를 담고있는 map을 추출한다. 그 후에 기존의 input filter와 추출한 가중치를 곱하여 return한다.
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] ViT: AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(2021) (0) | 2023.07.24 |
|---|---|
| [논문 리뷰] EfficientNet(2019), 파이토치 구현 (2) | 2022.12.30 |
| [논문 리뷰] ResNeXt(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] MobileNet V1(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] DenseNet(2017), 파이토치 구현 (0) | 2022.12.29 |



