
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문리뷰
- 강화학습
- 딥러닝
- opencv
- 인공지능
- transformer
- Self-supervised
- Computer Vision
- 코드구현
- 논문
- optimizer
- 논문구현
- Semantic Segmentation
- pytorch
- 프로그래머스
- Convolution
- 알고리즘
- Ai
- cnn
- 옵티마이저
- 논문 리뷰
- Segmentation
- Python
- 파이토치
- 파이썬
- ViT
- 머신러닝
- 코딩테스트
- programmers
- object detection
- Today
- Total
Attention please
[논문 리뷰] EfficientNet(2019), 파이토치 구현 본문
이번에 리뷰할 논문은 "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" 이다. 본 논문에서 제안한 EfficientNet은 ImageNet 데이터셋의 classification task에 SOTA에 달성하였다.
본 논문의 부제목을 살펴보면 "CNN 모델들을 모델 scaling하는 방법에 대해 다시 생각해보자" 이다. 즉, 모델을 scaling하는 방법들에 대해 실험을 하여 보다 효율적인 성능을 내도록 하는 것이 본 논문의 목적인데, 이 효율적이라 함은 적은 파라미터의 수로 좋은 성능을 낸다는 것에 있다.
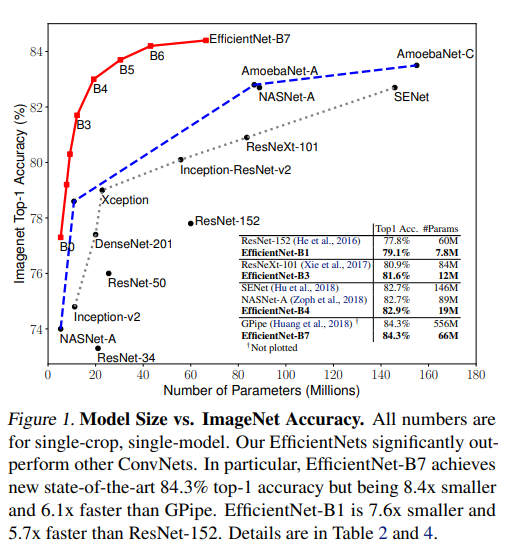
다음 figure와 같이 모델의 파라미터 수와 정확도를 비교한 표이다. 다른 모델들은 파라미터의 수가 많아지는 것에 비해 정확도가 낮은 폭으로 올라가는 것에 비해 EfficientNet은 적은 파라미터의 수로 높은 정확도를 보여준다.
Compound Scaling Method
CNN 모델의 성능을 끌어올리기 위한 방법은 총 3가지가 존재했다.
- Width Scaling : Filter의 개수를 늘림
- Depth Scaling : Layer의 개수를 늘림
- Resolution Scaling : Input data의 해상도를 늘림
지금까지는 CNN 모델의 성능을 올리기 위해서 위 세가지 방법들 중 한가지만을 선택해왔다. 하지만 EfficientNet 에서는 위 scaling 방법들을 각각 조절해가면서 실험을 했다.
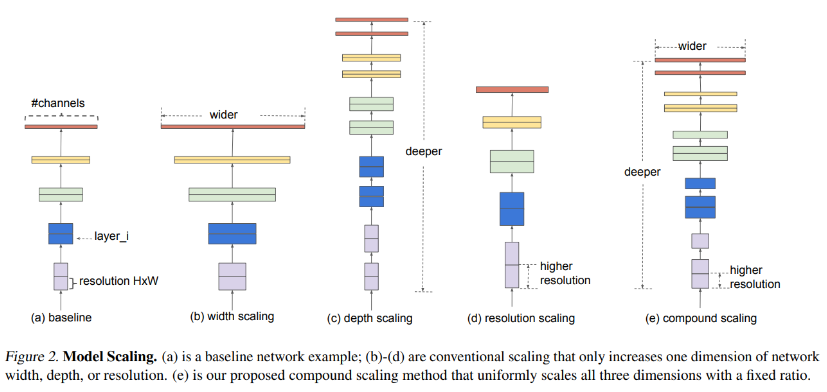
위 figure를 보면 기존 baseline에서 width, depth, resolution에 대해 scaling하는 것을 볼 수 있는데 본 논문에서는 3가지의 scaling을 적절히 섞어서 balance를 맞추는 것이었고 이 방법을 Compound Scaling Method라 칭했다.
그렇다면 어떤 방식으로 3가지의 scaling method를 효율적으로 조합할 수 있을까?
(1) Problem Formulation

다음 수식은 ConvNet의 연산을 수식화한 것이다. input data의 size인 H, W, C를 Conv Layer인 F에 집어넣으면 N이 나온다는 것이다. 여기에서 본 논문은 효율적임에 초점이 맞추어져있고 이는 제한된 환경에서도 좋은 성능을 이끌어낼 수 있어야 한다.

자원이 제한된 환경에서 모델의 정보를 최대화하는 것에 대한 문제를 수식으로 표현한 것이다. baseline은 고정해준 상태로 d, w, r을 바꾸어 accuracy를 최대화 한다. 하지만 N(d, w, r)은 target memory와 target flops를 넘어가선 안된다.
- FLOPS : floating point operations per second (초당 부동소수점 연산량)
(2) Scailing Dimensions
● Depth(d)
ConvNet은 깊이가 깊어질수록 다양한 feature들을 학습할 수 있고, 모델의 capacity가 커진다. 하지만 vanishing gradient 문제로 학습시키기 어려워진다. 이를 해결하기위해 Batch Norm, skip connection 등 해결 방법들이 나왔지만 모델의 깊이가 너무 깊어지면 효과가 없어지며 오히려 저하되는 모습을 보인다.
● Width(d)
size가 작은 모델에서 자주 쓰이며 fine-grained한 feature를 capture하는데 많이 사용된다. 하지만 width가 넓어지게 되면서 포화 역시 되기 쉬어진다.
● Resolution(r)
이미지의 해상도를 늘려 보다 fine-grained한 feature들을 학습할 수 있다. 하지만 Resolution이 증가할 수록 성능의 증가폭은 점점 감소된다.

위 figure와 같이 분명 Width, Depth, Resolution을 scaling-up 하는 것은 정확도 향상에 도움이 된다. 하지만 모델이 점점 커질수록 성능이 향상되는 폭이 줄어들게 된다.
(3) Compound Scaling
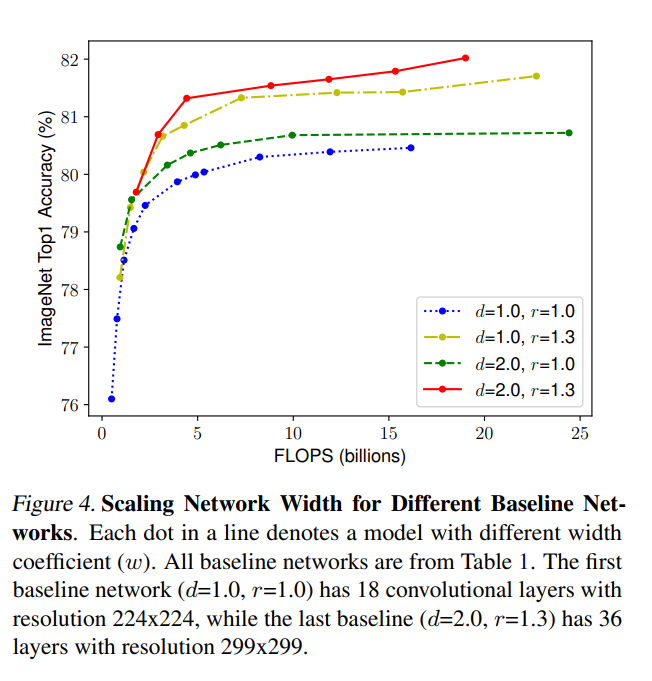
실험을 통해 resolution이 커지면 유사한 픽셀의 영역이 증가하기 때문에 Layer의 증가가 필요된다.
또한 더 넓어진 resolution을 더 잘 사용하기 위해 fine-grained한 feature들을 학습하는 것이 필요되어 channel의 증가가 필요되기 때문에 channel의 크기가 커지기 위해서는 Width의 증가가 필요된다.
즉, depth, width, resolution 3가지의 scaling method들은 서로 밀접하게 연관되어 있기에 단일 차원의 scaling이 아닌, 복합적인 차원의 균형 및 조정이 필요하다.
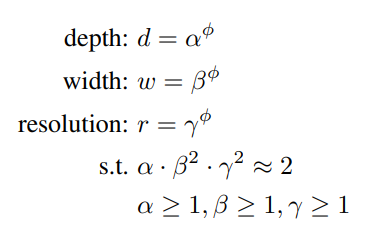
- ϕ : 자원이 추가되면 model scaling에 비례하여 증가시킬 계수 (User-Specified Coef)
- d ∝ FLOPS / w ∝ FLOPS^2 / r ∝ FLOPS^2
Architecture
EfficientNet의 경우 baseline network에 따라 성능이 크게 갈리기 때문에 baseline을 잘 잡는 것이 아주 중요하다. 본 논문에서는 MnasNet 에 기반하여 baseline network를 사용한다.
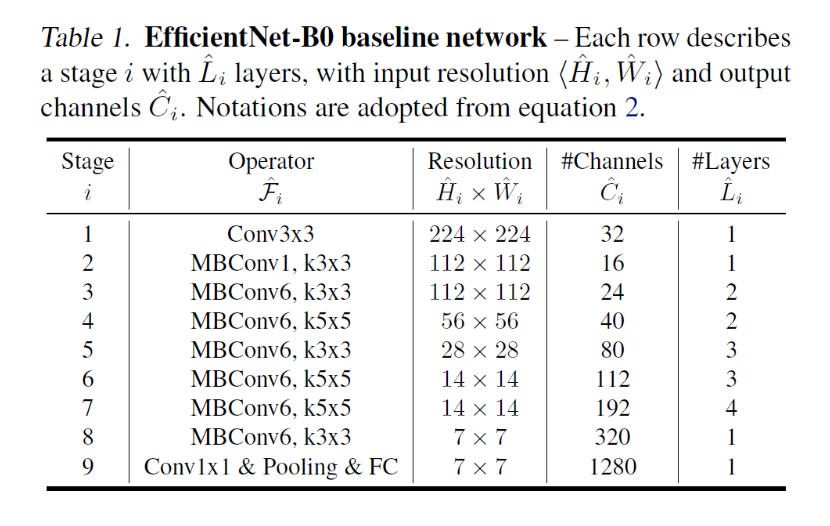
위 baseline network를 기반으로 시작된다.
α, β, γ를 찾아 큰 모델에 적용하면 더 좋은 성능을 기대할 수 있었지만 큰 모델의 경우 그 값을 찾는 비용이 오히려 더 많이 드는 문제가 생겼다.
이 연구에서는 다음 두 단계를 이용하여 이 문제를 해결하였다.
1. ϕ = 1 로 고정한 후, α, β, γ 에 대해 grid search를 수행한다.
2. 찾은 α, β, γ 를 고정한 후 ϕ를 변화하여 baseline network의 scale을 키운다.
그렇게 ϕ 값만을 변화시켜 B0 ~ B7 까지 만들었다.
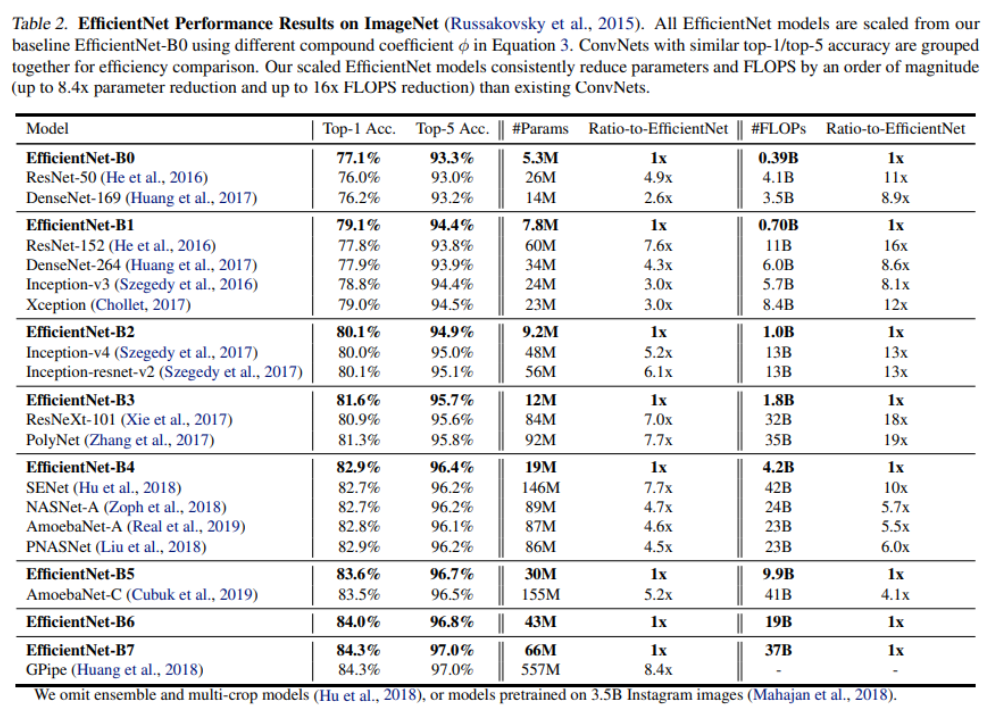
Experiment
다음은 ImageNet 데이터셋에 대한 EfficientNet의 결과이며, 전이학습에도 좋은 결과를 보임을 확인할 수 있다.
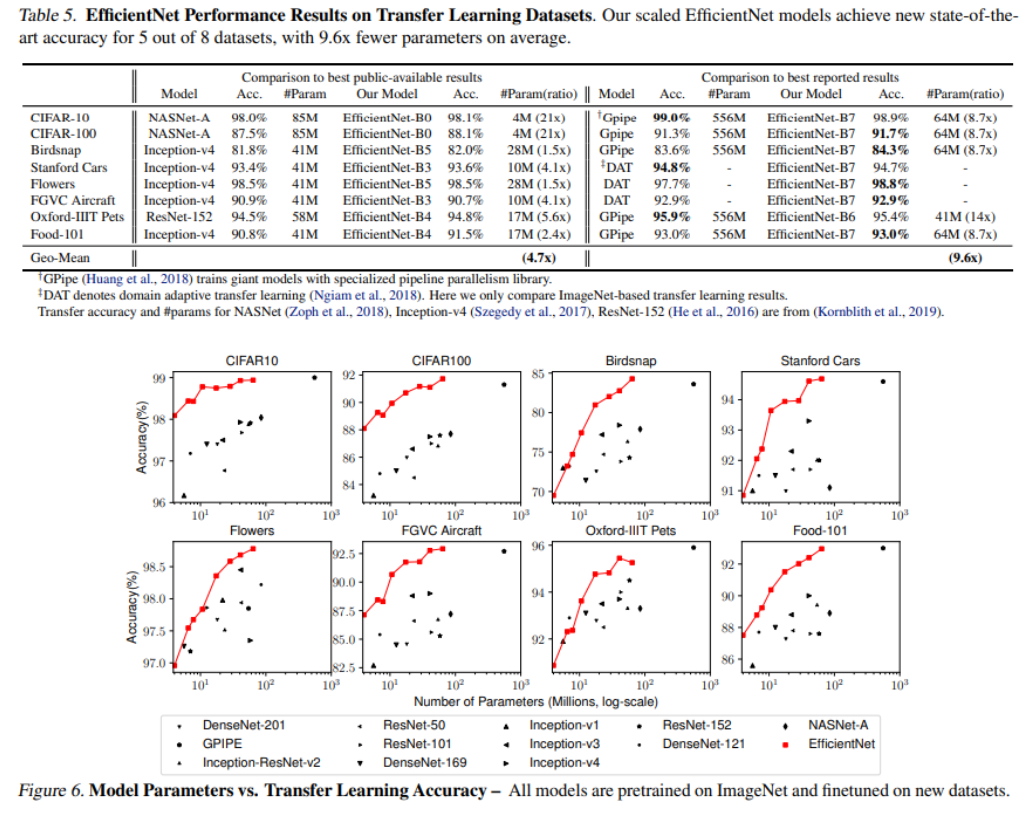
코드 구현
EfficientNet을 구현하기 전에 사용되는 활성화 함수 Swish를 정의해주어야한다.
class Swish(nn.Module):
def __init__(self):
super().__init__()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return x * self.sigmoid(x)
또한 EfficientNet에는 SE block을 사용한다.
class SEBlock(nn.Module):
def __init__(self, in_channels, r=4):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1,1))
self.excitation = nn.Sequential(
nn.Linear(in_channels, in_channels * r),
Swish(),
nn.Linear(in_channels * r, in_channels),
nn.Sigmoid()
)
def forward(self, x):
x = self.squeeze(x)
x = x.view(x.size(0), -1)
x = self.excitation(x)
x = x.view(x.size(0), x.size(1), 1, 1)
return x
EfficientNet의 전체적인 구조는 다음과 같다.
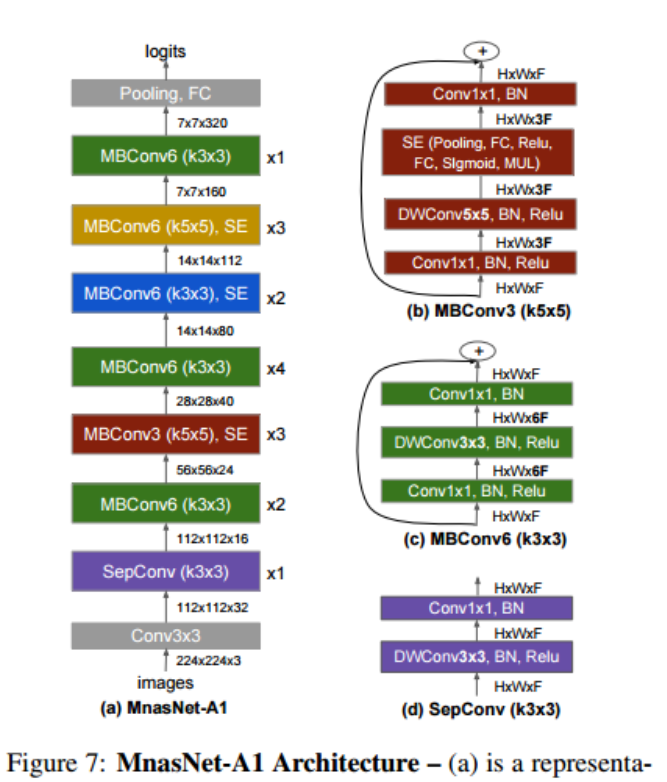
baseline network인 MnasNet을 구현하기 위해서는 먼저 MBConv 클래스와 SepConv 클래스를 먼저 정의해주어야 한다.
우선 MBConv 클래스를 구현하자.
또한 학습 시에 stochastic depth도 사용되기 때문에 같이 구현해야 한다.
class MBConv(nn.Module):
expand = 6
def __init__(self, in_channels, out_channels, kernel_size, stride=1, se_scale=4, p=0.5):
super().__init__()
# first MBConv is not using stochastic depth
self.p = torch.tensor(p).float() if (in_channels == out_channels) else torch.tensor(1).float()
self.residual = nn.Sequential(
nn.Conv2d(in_channels, in_channels * MBConv.expand, 1, stride=stride, padding=0, bias=False),
nn.BatchNorm2d(in_channels * MBConv.expand, momentum=0.99, eps=1e-3),
Swish(),
nn.Conv2d(in_channels * MBConv.expand, in_channels * MBConv.expand, kernel_size=kernel_size,
stride=1, padding=kernel_size//2, bias=False, groups=in_channels*MBConv.expand),
nn.BatchNorm2d(in_channels * MBConv.expand, momentum=0.99, eps=1e-3),
Swish()
)
self.se = SEBlock(in_channels * MBConv.expand, se_scale)
self.project = nn.Sequential(
nn.Conv2d(in_channels*MBConv.expand, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels, momentum=0.99, eps=1e-3)
)
self.shortcut = (stride == 1) and (in_channels == out_channels)
def forward(self, x):
# stochastic depth
if self.training:
if not torch.bernoulli(self.p):
return x
x_shortcut = x
x_residual = self.residual(x)
x_se = self.se(x_residual)
x = x_se * x_residual
x = self.project(x)
if self.shortcut:
x= x_shortcut + x
return x
그 후에 SepConv 클래스를 구현해야한다.
MBConv 와의 차이는 expand가 1인 것과 2개의 layer으로 이루어져 있다는 것이다.
class SepConv(nn.Module):
expand = 1
def __init__(self, in_channels, out_channels, kernel_size, stride=1, se_scale=4, p=0.5):
super().__init__()
# first SepConv is not using stochastic depth
self.p = torch.tensor(p).float() if (in_channels == out_channels) else torch.tensor(1).float()
self.residual = nn.Sequential(
nn.Conv2d(in_channels * SepConv.expand, in_channels * SepConv.expand, kernel_size=kernel_size,
stride=1, padding=kernel_size//2, bias=False, groups=in_channels*SepConv.expand),
nn.BatchNorm2d(in_channels * SepConv.expand, momentum=0.99, eps=1e-3),
Swish()
)
self.se = SEBlock(in_channels * SepConv.expand, se_scale)
self.project = nn.Sequential(
nn.Conv2d(in_channels*SepConv.expand, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels, momentum=0.99, eps=1e-3)
)
self.shortcut = (stride == 1) and (in_channels == out_channels)
def forward(self, x):
# stochastic depth
if self.training:
if not torch.bernoulli(self.p):
return x
x_shortcut = x
x_residual = self.residual(x)
x_se = self.se(x_residual)
x = x_se * x_residual
x = self.project(x)
if self.shortcut:
x= x_shortcut + x
return x
이제 최종적으로 EfficientNet을 구현하자.
class EfficientNet(nn.Module):
def __init__(self, num_classes=10, width_coef=1., depth_coef=1., scale=1., dropout=0.2, se_scale=4, stochastic_depth=False, p=0.5):
super().__init__()
channels = [32, 16, 24, 40, 80, 112, 192, 320, 1280]
repeats = [1, 2, 2, 3, 3, 4, 1]
strides = [1, 2, 2, 2, 1, 2, 1]
kernel_size = [3, 3, 5, 3, 5, 5, 3]
depth = depth_coef
width = width_coef
channels = [int(x*width) for x in channels]
repeats = [int(x*depth) for x in repeats]
# stochastic depth
if stochastic_depth:
self.p = p
self.step = (1 - 0.5) / (sum(repeats) - 1)
else:
self.p = 1
self.step = 0
# efficient net
self.upsample = nn.Upsample(scale_factor=scale, mode='bilinear', align_corners=False)
self.stage1 = nn.Sequential(
nn.Conv2d(3, channels[0],3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(channels[0], momentum=0.99, eps=1e-3)
)
self.stage2 = self._make_Block(SepConv, repeats[0], channels[0], channels[1], kernel_size[0], strides[0], se_scale)
self.stage3 = self._make_Block(MBConv, repeats[1], channels[1], channels[2], kernel_size[1], strides[1], se_scale)
self.stage4 = self._make_Block(MBConv, repeats[2], channels[2], channels[3], kernel_size[2], strides[2], se_scale)
self.stage5 = self._make_Block(MBConv, repeats[3], channels[3], channels[4], kernel_size[3], strides[3], se_scale)
self.stage6 = self._make_Block(MBConv, repeats[4], channels[4], channels[5], kernel_size[4], strides[4], se_scale)
self.stage7 = self._make_Block(MBConv, repeats[5], channels[5], channels[6], kernel_size[5], strides[5], se_scale)
self.stage8 = self._make_Block(MBConv, repeats[6], channels[6], channels[7], kernel_size[6], strides[6], se_scale)
self.stage9 = nn.Sequential(
nn.Conv2d(channels[7], channels[8], 1, stride=1, bias=False),
nn.BatchNorm2d(channels[8], momentum=0.99, eps=1e-3),
Swish()
)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.dropout = nn.Dropout(p=dropout)
self.linear = nn.Linear(channels[8], num_classes)
def forward(self, x):
x = self.upsample(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.stage6(x)
x = self.stage7(x)
x = self.stage8(x)
x = self.stage9(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.linear(x)
return x
def _make_Block(self, block, repeats, in_channels, out_channels, kernel_size, stride, se_scale):
strides = [stride] + [1] * (repeats - 1)
layers = []
for stride in strides:
layers.append(block(in_channels, out_channels, kernel_size, stride, se_scale, self.p))
in_channels = out_channels
self.p -= self.step
return nn.Sequential(*layers)
def efficientnet_b0(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.0, depth_coef=1.0, scale=1.0,dropout=0.2, se_scale=4)
def efficientnet_b1(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.0, depth_coef=1.1, scale=240/224, dropout=0.2, se_scale=4)
def efficientnet_b2(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.1, depth_coef=1.2, scale=260/224., dropout=0.3, se_scale=4)
def efficientnet_b3(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.2, depth_coef=1.4, scale=300/224, dropout=0.3, se_scale=4)
def efficientnet_b4(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.4, depth_coef=1.8, scale=380/224, dropout=0.4, se_scale=4)
def efficientnet_b5(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.6, depth_coef=2.2, scale=456/224, dropout=0.4, se_scale=4)
def efficientnet_b6(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=1.8, depth_coef=2.6, scale=528/224, dropout=0.5, se_scale=4)
def efficientnet_b7(num_classes=10):
return EfficientNet(num_classes=num_classes, width_coef=2.0, depth_coef=3.1, scale=600/224, dropout=0.5, se_scale=4)
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(2021) (2) | 2023.07.28 |
|---|---|
| [논문 리뷰] ViT: AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(2021) (0) | 2023.07.24 |
| [논문 리뷰] SENet(2018), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] ResNeXt(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] MobileNet V1(2017), 파이토치 구현 (0) | 2022.12.29 |



