
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- opencv
- Computer Vision
- 프로그래머스
- 논문 리뷰
- 옵티마이저
- 논문구현
- optimizer
- Self-supervised
- 머신러닝
- 파이토치
- 코딩테스트
- Convolution
- pytorch
- cnn
- 파이썬
- transformer
- Ai
- Semantic Segmentation
- object detection
- 인공지능
- Python
- Paper Review
- 딥러닝
- Segmentation
- 알고리즘
- 논문리뷰
- ViT
- 논문
- 코드구현
- programmers
- Today
- Total
Attention please
[논문 리뷰] DenseNet(2017), 파이토치 구현 본문
이번에 리뷰할 논문은 "Densely Connected Convolutional Networks" 이다.

CNN 모델의 성능을 높이기 위해 가장 직접적인 방법은 층의 깊이를 늘리는 것이다. 하지만 단순히 층이 깊어지기만 하면 vanishing gradient와 같은 문제들이 발생하게 되는데 이러한 문제들을 해결하기 위해 앞부분과 뒷부분을 short path로 연결해주는 ResNet과 같은 모델들이 제안되었다. DenseNet 역시 앞부분과 뒷부분을 연결해준다는 점을 사용하여 접근하였다.
Connectivity
1. ResNet
DenseNet 역시 앞부분과 뒷부분을 연결해주는데 그 방식이 ResNet과 차이가 있다. ResNet의 방식은 입력값과 출력값을 skip connection에 의해 더해준다. 이러한 더하는 방식으로 gradient flow가 직접 전달되지만 information flow가 지연될 수 있다는 단점이 있다고 한다.
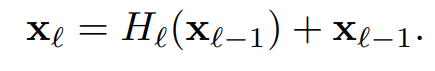
위 수식의 H함수는 Convolution, Batch Normalization, ReLU 함수를 차례대로 연산하는 것을 의미하며, X(l-1) 는 skip connection을 의미한다.
2. DenseNet
DenseNet의 경우 이전 layer와 다음 layer를 모두 concatenation한다. 모든 layer들이 연결되어있기 때문에 information flow 역시 향상된다.

DenseNet의 H함수는 보통의 CNN과는 다르게 Batch Normalization, ReLU, 3x3 Convolution 함수를 차례대로 연산하는 것을 의미한다. 이는 pre-activation 구조를 이용했기 때문이며, ResNet과는 다르게 모든 layer에 대해 H 연산을 수행하는 것을 볼 수 있다.
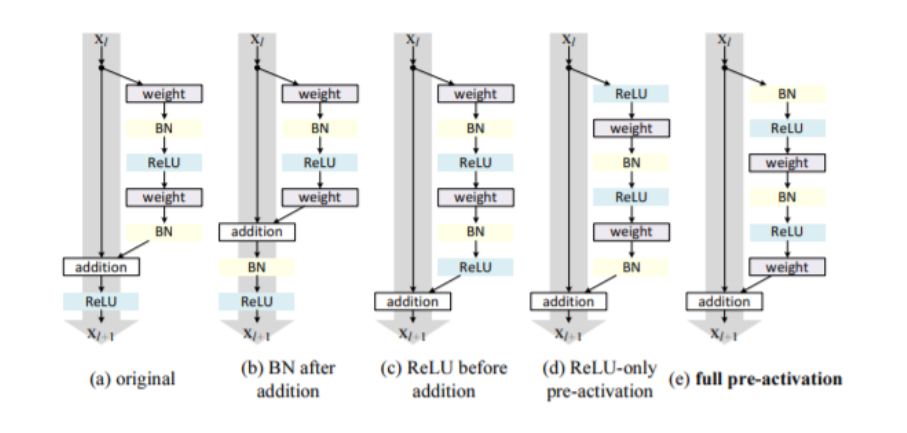
pre-activation은 말 그대로 CNN연산을 하기 전에 activation function 연산을 수행하는 것을 의미한다. 위 figure에서 pre-activation을 사용하는 것은 (d)와 (e)이며, (d)의 경우 ReLU와 Batch Normalization이 함께 쓰이지 못해 ReLU가 Batch Normalization의 효과를 보지 못한다고 설명한다.
pre-activation을 사용하면 optimize가 더 쉽고 overfitting을 줄일 수 있다는 장점이 존재한다.
Dense Block
concatenation을 하기 위해서는 한가지 조건이 필요한데 바로 feature map의 size가 동일해야 한다는 것이다. 하지만 CNN의 특성 상 size를 줄여나가는 down-sampling을 뺄 수 없다. 이를 해결하기 위해 나온 것이 transition layer이다.

Dense Block을 사용하면 다양한 장점들이 존재한다.
- vanishing gradient 문제 해결
- Feature Propagation 강화
- Feature Reuse
- Parameter 수 절약
Transition Layer
위 figure를 보면 dense block 사이에 convolution과 pooling을 수행하는 것을 볼 수 있는데 이를 transition layer이라 칭하며, transition layer는 1x1 convolution 과 2x2 average pooling으로 이루어져있다. 이 transition으로 feature map의 size와 channel 수를 감소시켜 down-sampling을 진행한다.
transition layer에는 theta라는 하이퍼 파라미터가 존재한다. theta는 transition layer가 출력하는 채널 수를 조절하는데 만약 transition layer의 입력값 채널 수가 m이라면 theta * m 개의 채널 수를 출력한다. 채널 수를 조절하기 위해 1x1 convolution을 사용하며, 논문에서는 theta를 0.5로 설정하였다.
Growth rate
DenseNet에는 Growth rate라는 하이퍼 파라미터가 존재한다. Dense Block 내의 layer는 k개의 feature map을 생성하는데 이때 k가 growth rate이다. L번째 layer는 k0 + k * (L-1) 개의 입력값을 가진다. (k0 : 입력 layer의 채널 수) 논문에서는 k=12를 사용한다.
Bottleneck Layers
Bottlenect이라는 개념은 이미 ResNet에서도 쓰인 적이 있다. 이 기법은 3x3 convolution 의 입력값 채널의 수를 조절하여 연산량을 줄이기 위해 사용되는데 ResNet과 DenseNet의 bottleneck의 형태는 다음과 같다.
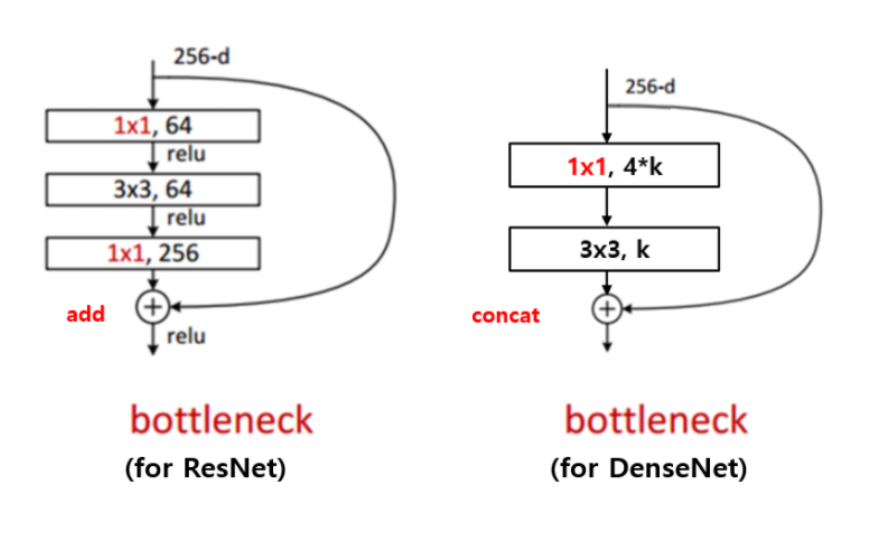
DenseNet의 bottleneck은 1x1 convolution으로 3x3 convolution의 입력값을 4*k 로 조절하는 것을 볼 수 있다.
Architecture
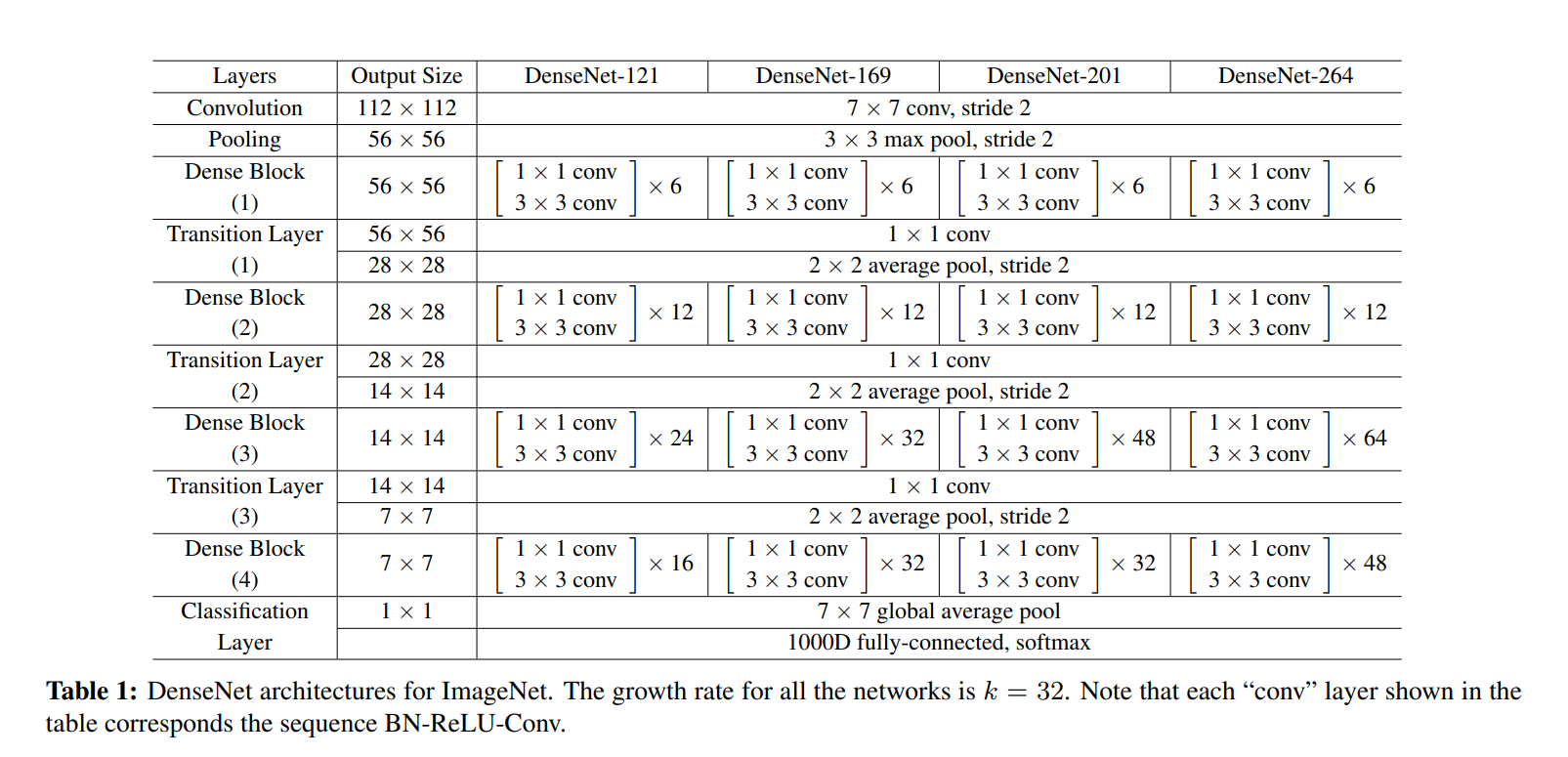
다음은 ImageNet 데이터셋을 위한 DenseNet architecture이다. ImageNet 데이터셋은 class가 1000개로 다른 데이터셋에 비해 size가 아주 크기 때문에 다른 구조를 가진다. ImageNet 데이터셋을 다룰 때에는 growth rate인 k를 32로 설정하였다고 한다.

다음은 k0 = 256, k(growth rate) = 32 인 DenseNet에 (128x128x3) size의 input data를 넣게 되었을 때 진행 과정을 보여주는 그림이다.
코드 구현
먼저 BottleNect class를 구현하자.
class Bottleneck(nn.Module):
def __init__(self, in_planes, growth_rate):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, 4*growth_rate, kernel_size=1, bias=False) # 1x1 convolution을 할 때는 output 채널 값이 4*k 가 되도록 함
self.bn2 = nn.BatchNorm2d(4*growth_rate)
self.conv2 = nn.Conv2d(4*growth_rate, growth_rate, kernel_size=3, padding=1, bias=False) # size를 맞추기 위해 padding값을 1로 지정
def forward(self, x): # pre-activation resnet의 순서 (Batch Normalization - ReLU - Convolution)
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat([out, x], 1) # 입력값과 출력값을 concatenation 해준다.
return out
다음으로 transition layer를 class로 구현하자.
class Transition(nn.Module):
def __init__(self, in_planes, out_planes):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(in_planes)
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False)
def forward(self, x): # Batch Normalization - Relu - 1×1 Convolution - 2×2 Average Pooling
out = self.conv(F.relu(self.bn(x)))
out = F.avg_pool2d(out, 2)
return out
마지막으로 위에서 정의한 class들을 이용하여 DenseNet class를 구현하자.
class DenseNet(nn.Module):
def __init__(self, block, nblocks, growth_rate=12, reduction=0.5, num_classes=10): # reduction : 논문의 theta
super(DenseNet, self).__init__()
self.growth_rate = growth_rate
num_planes = 2*growth_rate
self.conv1 = nn.Conv2d(3, num_planes, kernel_size=3, padding=1, bias=False) # architecture 구현 시 padding=3 -> 7x7 filter 이므로 size를 맞추기 위함
self.dense1 = self._make_dense_layers(block, num_planes, nblocks[0])
num_planes += nblocks[0]*growth_rate # K0 + num_planes * K
out_planes = int(math.floor(num_planes*reduction))
self.trans1 = Transition(num_planes, out_planes)
num_planes = out_planes
self.dense2 = self._make_dense_layers(block, num_planes, nblocks[1])
num_planes += nblocks[1]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans2 = Transition(num_planes, out_planes)
num_planes = out_planes
self.dense3 = self._make_dense_layers(block, num_planes, nblocks[2])
num_planes += nblocks[2]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans3 = Transition(num_planes, out_planes)
num_planes = out_planes
self.dense4 = self._make_dense_layers(block, num_planes, nblocks[3])
num_planes += nblocks[3]*growth_rate
self.bn = nn.BatchNorm2d(num_planes)
self.linear = nn.Linear(num_planes, num_classes)
def _make_dense_layers(self, block, in_planes, nblocks):
layers=[]
for i in range(nblocks):
layers.append(block(in_planes, self.growth_rate))
in_planes += self.growth_rate # input과 output값이 concatenation 되었기 때문에 input의 in_planes와 output의 growth_rate를 더해준다.
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
# out = self.max_pool2d(out, kernel_size=3, stride=2, padding=1) # 논문에서 max pooling layer
out = self.trans1(self.dense1(out))
out = self.trans2(self.dense2(out))
out = self.trans3(self.dense3(out))
out = self.dense4(out)
out = F.avg_pool2d(F.relu(self.bn(out)), 4) # 논문에서는 7x7 GAP
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def DenseNet121():
return DenseNet(Bottleneck, [6, 12, 24, 16], growth_rate=32)
net = DenseNet121()
net = net.to(device)
print(net)
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] ResNeXt(2017), 파이토치 구현 (0) | 2022.12.29 |
|---|---|
| [논문 리뷰] MobileNet V1(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] Xception(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] ResNet(2016), 파이토치 구현 (0) | 2022.12.28 |
| [논문 리뷰] Inception V1 - GoogLeNet(2014), 파이토치 구현 (0) | 2022.12.28 |



