
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 프로그래머스
- 파이썬
- transformer
- Learning
- opencv
- VLM
- 딥러닝
- 인공지능
- Python
- object detection
- 머신러닝
- 알고리즘
- 코드구현
- 논문리뷰
- 옵티마이저
- 논문구현
- Ai
- pytorch
- cnn
- Computer Vision
- reinforcement
- 강화학습
- 코딩테스트
- ViT
- llm
- Vision
- Segmentation
- optimizer
- 파이토치
- programmers
- Today
- Total
Attention please
[논문 리뷰] DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs(2017) 본문
[논문 리뷰] DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs(2017)
Seongmin.C 2023. 7. 20. 23:55이번에 리뷰할 논문은 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs 입니다.
https://paperswithcode.com/paper/deeplab-semantic-image-segmentation-with-deep
Papers with Code - DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CR
#3 best model for Semantic Segmentation on Event-based Segmentation Dataset (mIoU metric)
paperswithcode.com
DCNNs(Deep Convolutional Neural Networks) 는 image classification, object detection 과 같은 다양한 high-level 문제에서 아주 좋은 성능을 보여주었습니다. 이는 DNN이 이미지에 대해 추장적인 데이터 표현을 학습할 수 있기 때문이죠. 이런 DCNN의 invariance함이 image classification 에서는 아주 효과적이었습니다.
하지만 image segmentation의 경우 DCNN의 invariance함이 오히려 단점이 되었습니다. pixel단위로 디테일하게 분류를 해야하는데 추장적인 정보를 주로 학습하는 DCNN에는 spatial information이 부족했던 것이 이유였죠.
본 논문에서는 총 3가지의 문제를 제시합니다.
- max-pooling과 downsampling에 의한 feature map의 resolution 감소
- 다양한 scale을 가진 object들의 존재
- DCNN의 spatial transformation에 대한 invariance로 인한 spatial accuracy 제한
위의 문제들을 해결하기 위해 Atrous Spatial Pyramid Pooling(ASPP)와 fully-connected Conditional Random Field (CRF) 같은 기법들을 사용합니다. 밑에서 해당 기법들에 대해 자세히 설명드리도록 하겠습니다.
Atrous Convolution
DCNN은 pooling layer를 연속적으로 적용하여 down sampling을 진행합니다. 이는 보다 추장적이고 global 한 정보를 추출하기 위함인데 image classification에서는 단순히 image 속 객체의 위치가 달라져도 전체적인 형태를 파악함으로써 어떤 class에 속하는 지 분류하기에 최적화되어있습니다. 하지만 image segmentation의 경우 pixel단위로 객체의 디테일한 spatial information을 학습해야합니다. 기존의 DCNN과는 아무래도 거리가 멀죠.
이때 등장한 것이 바로 atrous convolution 입니다. down sampling을 통해 이미지의 전체적인 정보를 대략적으로 학습하는 것이 아닌 convolution 자체의 view를 늘려주어 학습하자는 아이디어에서 나온 기법입니다. atrous convolution은 굳이 pooling layer를 거치지 않고도 이미지의 넓은 view를 학습할 수 있었으며 down sampling의 대체가 가능해집니다.

위 figure의 (a)는 standard convolution, (b)는 atrous convolution을 보여줍니다. 보시다시피 1차원 input data에 대해 각각 합성곱을 진행하며, 수식으로 표현하면 다음과 같습니다.
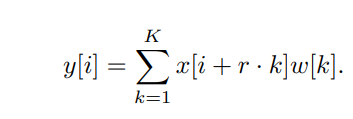
- w : atrous convolution
- r : dilation rate (r of original convolution = 1)
- k : filter indexing (K : filter length)
(b) 그림을 보면 dilation rate가 2로 설정돼있음을 확인할 수 있습니다. 기존의 convolution인 (a)와 달리 1칸씩 띄어 convolution을 연산하는 것을 볼 수 있습니다. 만약 2번째(k=2) filter의 연산을 위 식을 통해 표현하면 다음과 같습니다.

위와 같이 그림으로 표현할 수 있으며, 수식으로 표현하면 $ y[2] = x[2]w[1] + x[4]w[2] + x[6]w[3] $ 입니다. 2차원의 경우 역시 마찬가지 입니다. 단지 convolution filter의 사이사이에 padding을 dilation rate만큼 추가해주면 되는 것이죠. 만약 원래의 convolution filter가 [5, 3, 8] 로 구성되어 있었다면 dilation rate를 2로 주어 [5, 0, 3, 0, 8] 로 만들어 사용하게 됩니다.
실제로 이미지에서 downsampling을 진행한 후 다시 upsampling을 하였을 때와 atrous convolution을 사용하였을 때를 비교해보면 다음과 같은 결과가 나온다고 합니다.

downsampling을 한 후 upsampling을 했을 때는 feature의 추출이 sparse함을 확인할 수 있습니다. 반면 atrous convolution을 사용한 결과는 아주 dense하게 feature가 잘 추출되었음을 확인할 수 있죠. 이와 같이 atrous convolution의 경우 dilation을 주어 view를 확장하기 때문에 down sampling을 하지 않아도 detail함을 가질 수 있으며, 더 넓은 context information을 학습할 수 있습니다.
Atrous Spatial Pyramid Pooling
Image안의 object들의 scale은 다 제각각입니다. DCNN의 경우 단순히 객체에 대해 분류를 하면 되기에 전체적으로 추상적인 정보를 학습하는 것만으로도 좋은 performance를 낼 수 있지만 image segmentation의 경우는 좀 다릅니다. 영역을 검출해야하는데 같은 객체이지만 크고 작은 경우가 있을 수 있으며, 이에 대해 디테일한 정보를 학습하는데 있어서 방해 요소가 됩니다. 본 논문에서는 다양한 scale을 처리하는 두가지 접근법을 제시합니다.
Standard multiscale processing
이 방법은 우선 original image에서 다양한 scale로 조정합니다. 그 후에 같은 파라미터를 공유하는 DNNs branch들을 병렬적으로 사용하여 독립적으로 수행한 후 원래 이미지 해상도로 interpolation을 하여 해상도를 통일하였으며, 각 scale에서 얻어진 결과를 결합합니다. 본 논문에서는 각 위치에서 최대값을 선택하는 식으로 융합을 진행한다고 합니다. 하지만 이 방법의 경우 여러 scale의 데이터들을 병렬적으로 처리하기 때문에 많은 계산 비용이 든다는 단점이 존재합니다.
Atrous spatial pyramid pooling
기존의 atrous convolution을 사용하게 되면 같은 level에서 한번의 feature만 추출할 수 있었습니다. 이는 같은 클래스를 가진 객체이지만 다양한 scale을 가질 수 있기 때문에 여러 feature를 학습하는 것이 필요합니다. ASPP는 여러가지 dilation rate를 가진 atrous convolution을 병렬적으로 적용하여 이 문제를 해결했습니다.

들어온 feature map에 대해서 동시에 여러 scale의 feature를 처리함으로써 보다 다양한 scale을 가진 객체들에 대해 대비하는 것이 가능해진 것이죠.
fully-connected Conditional Random Fields
DCNN과 같이 깊은 모델은 여러개의 max-pooling을 거쳐 classification에서는 성공적으로 수행했습니다. 이는 높은 invariance와 최상위 노드의 넓은 receptive-filed 덕에 smooth한 결과를 얻을 수 있다고 하였죠. 하지만 이런 DCNN은 객체의 존재와 대략적인 위치만을 탐지할 수 있었으며, 해당 object의 경계를 그리기에는 어려움이 있었습니다. 본 논문에서는 object의 경계를 좀더 디테일하게 그리기 위해 fully-connected Conditional Random Fields 를 사용합니다.

위 figure를 보면 단순히 DCNN을 사용한 결과에 비해 CRF를 사용한 결과의 경계가 좀 더 확실하게 잡혀있음을 확인할 수 있습니다.
전통적인 CRFs의 경우 noise가 많은 segmentation map을 smooth하게 만드는 데 사용되었습니다. 이 방법론은 인접 노드를 결합하여 공간적으로 가까운 픽셀에 동일한 라벨 할당을 하여 진행됩니다. 하지만 본 논문에서는 좀 더 세밀한 구조를 복구하기 위해 개선된 fully-connected CRF 를 사용합니다.
fully-connected CRFs는 에너지 함수 $ E(x) $를 사용하여 각 label의 에너지를 계산합니다.
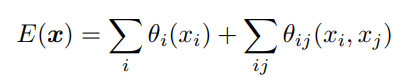
위 식에서의 $ x $는 픽셀에 대한 label 할당이며, $ \theta_{i} $와 $ \theta_{ij} $는 각각 unary potentials과 pairwide potentials를 나타냅니다.
unary potentials $ \theta_{i}(x_{i}) $는 각 픽셀 i가 라벨 $ x_{i} $를 갖는 확률에 대한 negative log probability 입니다. pairwise potentials $ \theta_{ij}(x_{i}, x_{j}) $는 픽셀 i와 j 사이의 라벨 $ x_{i} $와 $ x_{j} $에 대한 패널티를 나타냅니다. 이는 두 픽셀이 비슷한 색상과 위치를 가지고 있을 때, 그들이 같은 라벨값을 갖도록 하는 역할을 하죠. 이 함수는 gaussian kernel을 사용하여 계산되며, 형태는 다음과 같습니다.

위 식에서 $ \mu(x_{i}, x_{j}) $는 $ x_{i} $와 $ x_{j} $가 다를 때 1이고, 그렇지 않을 때 0을 반환합니다. 즉, 같은 라벨이 아닌 노드에 대해서만 패널티가 부과하는 셈이죠. 그 뒤에 오는 나머지 두 항은 두 gaussian kernel을 나타냅니다. 이들은 색상과 공간 위치에 따른 유사성을 각각 측정하죠. gaussian kernel의 scale은 하이퍼 파라미터 $ \sigma_{\alpha}, \sigma_{\beta}, \sigma_{\lambda} $로 조절됩니다.
이렇게 DeepLab v2에서 사용되는 기법들을 모두 알아보았습니다. 전체적인 구조는 밑의 그림과 같습니다.




