
- 분류 전체보기 (128)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ViT
- Python
- cnn
- 머신러닝
- Self-supervised
- pytorch
- 인공지능
- opencv
- Computer Vision
- 프로그래머스
- transformer
- 강화학습
- 코딩테스트
- 알고리즘
- 딥러닝
- 코드구현
- Semantic Segmentation
- programmers
- object detection
- 파이토치
- 파이썬
- optimizer
- Ai
- 논문구현
- 논문리뷰
- 논문
- 옵티마이저
- 논문 리뷰
- Segmentation
- Convolution
- Today
- Total
Attention please
[논문 리뷰] SPP: Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition(2015) 본문
[논문 리뷰] SPP: Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition(2015)
Seongmin.C 2023. 7. 6. 10:25이번에 리뷰할 논문은 Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition 입니다.
https://paperswithcode.com/method/spatial-pyramid-pooling
Papers with Code - Spatial Pyramid Pooling Explained
Spatial Pyramid Pooling (SPP) is a pooling layer that removes the fixed-size constraint of the network, i.e. a CNN does not require a fixed-size input image. Specifically, we add an SPP layer on top of the last convolutional layer. The SPP layer pools the
paperswithcode.com
본래 CNN 모델들은 한가지 공통점이 있었습니다. 바로 input image의 resolution이 고정돼야한다는 것인데요. 이런점을 해결하고자 나온 기법이 SPP(Spatial Pyramid Pooling) 입니다.
model에 들어갈 이미지들의 크기는 모두 제각각입니다. 하지만 input image의 size가 고정되어있기 때문에 cropping 이나 warping 을 사용해서 size를 통일시켜줍니다.

하지만 crop된 이미지는 object의 전체를 포함하지 못한다는 문제가 존재하며 warp된 이미지는 공간적으로 왜곡되는 문제가 발생합니다. 이러한 내용 손실과 왜곡으로 인해 정확도가 떨어질 수 있습니다.
저자들은 여기서 한 가지 질문을 던집니다.
왜 CNN 모델은 input size가 고정되어야 하는가?
CNN 모델의 구조는 크게 두가지로 나눌 수 있습니다. convolution layer와 다음으로 따라오는 fully-connected layer 이죠. 사실 convolution layer는 input으로 들어오는 image size가 고정될 필요는 없습니다. 어떠한 size의 이미지도 feature map을 만들 수 있죠.
하지만 문제는 fully-connected layer에 있습니다. fc-layer는 고정된 input size가 미리 정의되어야 합니다. 고로 size가 고정되어야 한다는 제약은 오직 fully-connected layer에서만 오는 것이죠.
본 논문에서는 위와 같은 fixed-size에 대한 제약을 제거하기 위해 spatial pyramid pooling (SPP) 기법을 소개합니다. SPP layer는 마지막 convolution layer 다음에 위치합니다. feature map을 pooling 하여 고정된 size의 output을 생성하기에 서로 다른 크기의 이미지들을 crop 이나 warp 해줄 필요가 사라지게 됩니다.

이렇게 CNN 모델에 적용된 SPP 는 다음과 같은 특징들을 가집니다.
- input size에 관계없이 고정된 길이의 output을 출력할 수 있습니다.
- sliding window pooling은 단 한 size의 single window를 사용하는 반면 SPP는 다중 수준의 공간적인 bin들을 사용합니다.
- input scale의 유연함 덕분에 다양한 scale에서 추출된 feature를 pool 할 수 있습니다.
SPP-net은 object detection 에서도 좋은 performance를 보여줍니다. 기존의 object detection분야에서 사용되었던 R-CNN 모델의 경우 후보 window에서 deep convolution network를 반복적으로 적용하여 feature들을 추출합니다. 이 방법은 높은 정확도를 보여주지만 계산 비용이 많이 소모된다는 단점이 존재하죠.
하지만 본 논문에서는 전체 이미지에서 convolution layer를 단 한번만 적용한 후 feature map에서 SPP-net을 통해 feature를 추출합니다. 이 방법은 R-CNN 에 비해 100배 이상의 빠른 모습을 보여주었다고 합니다.
The Spatial Pyramid Pooling Layer
convolution layer는 다양한 size의 이미지들을 받을 수 있지만 output 역시 다양한 크기를 출력합니다. 하지만 그 뒤에 오는 fully-connected layer는 고정된 크기의 vector만을 받을 수 있죠. 그렇기에 마지막 convolution layer 다음에 오는 pooling layer 대신 spatial pyramid pooling layer로 대체합니다.

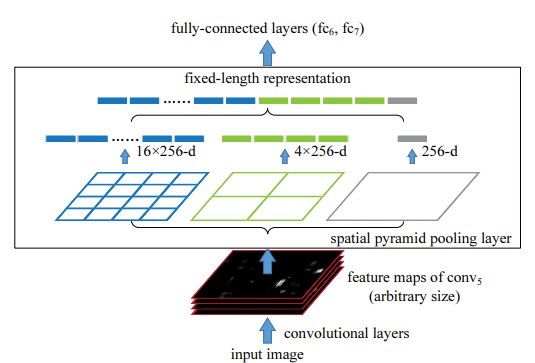
위 figure를 보면 input image를 convolution layer들을 통과시키며 마지막 conv 층인 conv5의 feature map이 생성된 것을 볼 수 있습니다. 물론 feature map의 size는 정해진 size가 아닌 임의로 정해진 size입니다. (input size가 고정되지 않았기 때문)
fc-layer를 통과하기 전 Spatial pyramid pooling layer를 거치게 됩니다. 먼저 input으로 받은 feature map을 정해진 size의 영역으로 나누어주게 되는데 위 그림에서는 4x4, 2x2, 1x1 3가지의 영역(피라미드)을 제공합니다.
이때 해당 영역(피라미드) 한 칸을 bin이라고 부릅니다. 만약 input으로 들어온 feature map의 size가 32x32x256 이라고 한다면 4x4 피라미드의 bin의 크기는 32 / 4 = 8 이 됩니다. 보통 pooling의 방법으로는 max pooling을 사용하며 stride는 window가 서로 겹치지 않도록 window의 size와 똑같이 설정한다고 합니다. (window size=2 -> stride=2)
이렇게 max pooling을 수행해준 후 나온 결과를 쭉 이어줍니다.
위의 figure 예시를 생각해보자면 먼저 사용한 피라미드는 4x4, 2x2, 1x1 피라미드입니다. input으로 들어온 feature map의 차원은 256이죠. (num of filters : 256)
먼저 첫번째 4x4 피라미드를 통해 16개의 bin이 만들어지며 filter의 개수가 256개이므로 16x256 dimension vector가 만들어집니다. 2x2 피라미드의 경우 4x256-d vector, 1x1 피라미드의 경우 1x256-d vector 가 만들어지며 차례대로 concate됩니다.
여기서도 알 수 있듯이 각 피라미드의 bin 개수를 정해놓기 때문에 SPP layer의 output size는 항상 고정되게 됩니다.
Pytorch 구현
import math
def spatial_pyramid_pool(self,previous_conv, num_sample, previous_conv_size, out_pool_size):
'''
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer
out_pool_size: a int vector of expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
'''
# print(previous_conv.size())
for i in range(len(out_pool_size)):
# print(previous_conv_size)
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_wid*out_pool_size[i] - previous_conv_size[0] + 1)/2
w_pad = (w_wid*out_pool_size[i] - previous_conv_size[1] + 1)/2
maxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv)
if(i == 0):
spp = x.view(num_sample,-1)
# print("spp size:",spp.size())
else:
# print("size:",spp.size())
spp = torch.cat((spp,x.view(num_sample,-1)), 1)
return spp먼저 SPP layer를 코드로 구현해야합니다. 우선 각 파라미터의 의미를 파악해봅시다
- previous_conv : 바로 전의 convolution layer에서 출력된 feature map
- num_sample : 이미지 batch의 sample 개수
- previous_conv_size : 이전 conv layer 의 feature map의 [height, width]
- out_pool_size : 기대되는 최대 pooling layer의 출력 크기
먼저 SPP layer 를 진행할 때 각 피라미드에 대해 계산 후 다음 피라미드를 계산하는 식의 순차적으로 진행이 됩니다. 본 논문의 예시인 다음 그림을 살펴보죠.
피라미드의 size는 각각 4x4, 2x2, 1x1 입니다. 고로 out_pool_size = [4, 2, 1] 이 들어가게 됩니다. 먼저 크기가 4인 피라미드에 대해 계산을 시작해야합니다.
만약 바로 전 layer 인 conv5 에서 나온 출력 feature map의 size가 32x32x256 이라고 한다면 previous_conv_size = [32, 32] 가 될겁니다. 그러면 h_wid, w_wid 값은 32 / 4 = 8 이 됩니다. 즉, 이전 layer의 출력값의 크기와 정해져있는 bin 개수에 맞게 pooling window의 size가 결정된 것이죠.
추가로 bin의 개수와 이전 feature map size가 맞아떨어지지 않아 올림처리가 되었을 때 가장자리 부분을 padding을 채워주어 계산이 원할하게 될 수 있도록 해줍니다. 그 후에는 위에서 계산한 pooling window size와 stride(window size가 동일), padding 크기를 맞추어 max pooling 을 계산합니다.
이 과정을 각 out_pool_size에 대해 계산한 후 모두 flatten하게 이어 붙여 다음 층인 fc-layer의 input으로 넘겨주게 됩니다.
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.autograd import Variable
import numpy as np
import torch.nn.functional as F
from spp_layer import spatial_pyramid_pool
class SPP_NET(nn.Module):
'''
A CNN model which adds spp layer so that we can input multi-size tensor
'''
def __init__(self, opt, input_nc, ndf=64, gpu_ids=[]):
super(SPP_NET, self).__init__()
self.gpu_ids = gpu_ids
self.output_num = [4,2,1]
self.conv1 = nn.Conv2d(input_nc, ndf, 4, 2, 1, bias=False)
self.conv2 = nn.Conv2d(ndf, ndf * 2, 4, 1, 1, bias=False)
self.BN1 = nn.BatchNorm2d(ndf * 2)
self.conv3 = nn.Conv2d(ndf * 2, ndf * 4, 4, 1, 1, bias=False)
self.BN2 = nn.BatchNorm2d(ndf * 4)
self.conv4 = nn.Conv2d(ndf * 4, ndf * 8, 4, 1, 1, bias=False)
self.BN3 = nn.BatchNorm2d(ndf * 8)
self.conv5 = nn.Conv2d(ndf * 8, 64, 4, 1, 0, bias=False)
self.fc1 = nn.Linear(10752,4096)
self.fc2 = nn.Linear(4096,1000)
def forward(self,x):
x = self.conv1(x)
x = self.LReLU1(x)
x = self.conv2(x)
x = F.leaky_relu(self.BN1(x))
x = self.conv3(x)
x = F.leaky_relu(self.BN2(x))
x = self.conv4(x)
# x = F.leaky_relu(self.BN3(x))
# x = self.conv5(x)
spp = spatial_pyramid_pool(x,1,[int(x.size(2)),int(x.size(3))],self.output_num)
# print(spp.size())
fc1 = self.fc1(spp)
fc2 = self.fc2(fc1)
s = nn.Sigmoid()
output = s(fc2)
return output
위 코드는 일반적인 classification 을 위한 CNN 모델에 SPP layer를 붙인 모델입니다. 이와 같이 SPP Net 자체가 존재하는 것이 아닌 어떤 CNN 모델에도 하나의 모듈로서 기능을 해줄 수 있음을 보여줍니다.
'논문 리뷰 > Object detection' 카테고리의 다른 글
| [논문 리뷰] YOLO: You Only Look Once:Unified, Real-Time Object Detection(2016) (0) | 2023.07.17 |
|---|---|
| [논문 리뷰] A Method for Detection of Small Moving Objects in UAV Videos(2021) (0) | 2023.07.14 |
| [논문 리뷰] YOLO v1(2016) 리뷰 (0) | 2023.01.10 |
| [논문 리뷰] R-CNN(2014) (0) | 2022.12.30 |



