
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 알고리즘
- 딥러닝
- 코딩테스트
- object detection
- 프로그래머스
- 논문
- 강화학습
- pytorch
- Convolution
- ViT
- 코드구현
- 머신러닝
- 인공지능
- cnn
- Semantic Segmentation
- opencv
- 옵티마이저
- programmers
- 논문리뷰
- 논문구현
- Ai
- 논문 리뷰
- Self-supervised
- 파이토치
- transformer
- optimizer
- 파이썬
- Segmentation
- Python
- Computer Vision
- Today
- Total
Attention please
[논문 리뷰] R-CNN(2014) 본문
이번에 리뷰할 논문은 "Rich feature hierarchies for accurate object detection and semantic segmentation" 이다.
R-CNN은 object detection 모델 중 2-stage detector의 시초가 되는 모델이다. R-CNN 모델은 Regions with CNN의 약자로 region proposals 와 CNN이 결합된 구조이다.
이전의 Object Detection 분야의 최고의 성능을 나타낸 기법은 mAP 수치가 30% 정도였지만 R-CNN은 이 수치를 훨씬 뛰어넘는 53.3%를 달성하였다.
2022.12.30 - [딥러닝/CNN] - AP(Average Precision) & mAP(mean Average Precision)의 개념
AP(Average Precision) & mAP(mean Average Precision)의 개념
AP와 mAP는 CNN 모델의 성능을 평가하기 위한 평가지표이다. 하지만 AP와 mAP를 이해하기 위해서는 precision, recall에 대해 이해해야한다. Precision & Recall 정밀도(precision)과 재현율(recall)은 Computer vision
smcho1201.tistory.com
R-CNN?

R-CNN은 classification에 사용되는 CNN과 localization을 위한 regional proposal 알고리즘이 연결되어 있는 모델이다.
<R-CNN은 Input Image에 대해 다음과 같이 작동된다>
1. Image를 입력받은 후 Selective Search 알고리즘을 통해 약 2000개의 regional proposal(bounding box)를 추출한다.
2. 추출된 region proposal들을 warp(resize)하여 CNN에 입력한다.
- 각 region proposal은 size가 다 다르기 때문에 resize를 해주어야 한다.
3. CNN에 의해 4096차원의 feature vector를 추출한다.
4. 추출된 feature vector를 SVM에 넣어 class를 분류한다.
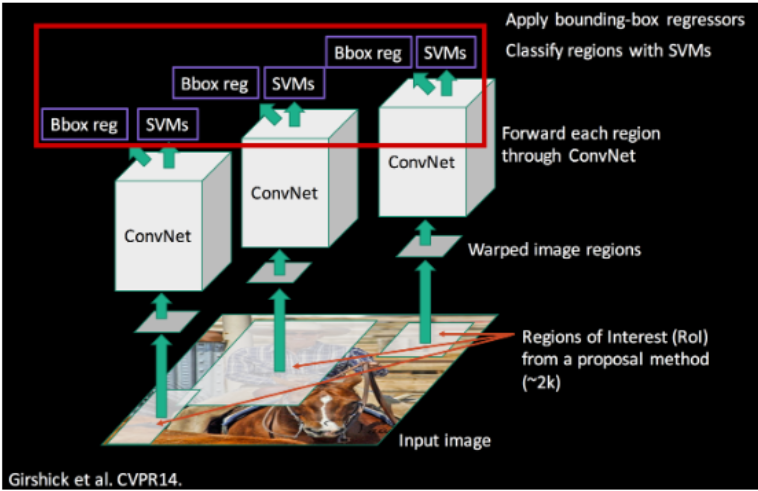
위 과정을 그림으로 표현하면 다음과 같다.

Module of R-CNN
R-CNN은 위 과정을 수행하기 위해 3가지의 module로 이루어져 있다.
- Region Proposal : Object가 있을 만한 영역을 여러개 추출 (selective search 알고리즘 사용)
- CNN : 각 region proposal에 대해 feature vector 추출
- SVM : class 분류를 위한 linear 지도 학습 모델 (그 당시 train data의 부족으로 softmax 사용시 오히려 성능 저하)
Region Proposal

R-CNN의 첫 번째 module은 Region Proposal 즉 object가 있을 만한 영역을 추출하는 것이다. 이를 위해 selective search 알고리즘을 사용하여 각각의 Image에서 2000개의 region proposal을 추출한다.

selective search의 자세한 설명은 아래 링크를 달아두었다.
2022.12.30 - [딥러닝/CNN] - Object Detection이란 무엇일까?
Object Detection이란 무엇일까?
Object Detection? 지금까지 CNN 모델은 분류(classification) 문제에 적용되어왔다. 즉, 어떤 image가 들어오게 되면 해당 image가 무엇인지 분류하는 작업을 해왔다. 이 classification에 객체의 위치를 특정해주
smcho1201.tistory.com
위 selective search를 통해 추출한 2000장의 region proposal들을 모두 warp(resize)를 하여 227x227의 size로 만들어준다.
(R-CNN의 모듈 중 CNN architecture로 AlexNet 모델을 사용하고 있으며 227x227 size의 입력을 요구함)
CNN

R-CNN의 module 중 CNN의 architecture는 AlexNet이다. 방대한 양의 ImageNet 데이터셋으로 pretrained된 AlexNet을 사용하며 Object Detection에 적용할 dataset으로 fine-tuning을 한다.
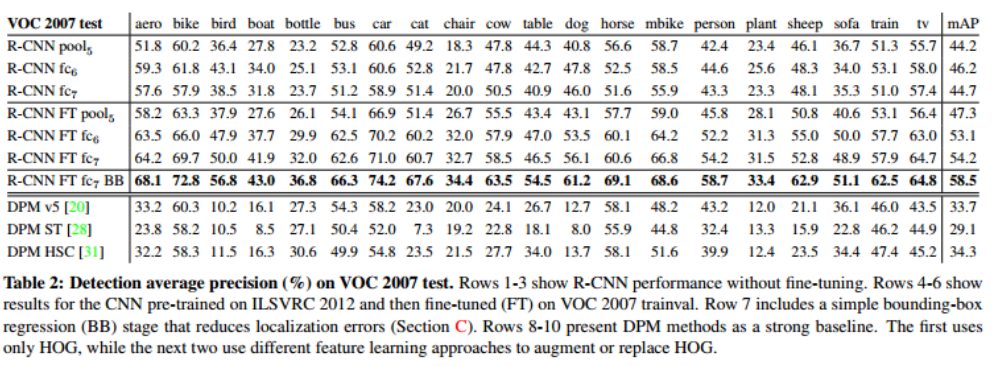
위 표의 1~3행은 fine-tunning을 하지 않았을 때이고, 4~6행은 fine-tunning을 하였을 때의 결과이다. 보시다시피 fine-tunning을 하였을 때 성능이 좋아지는 것을 확인할 수 있다.
이렇게 학습을 마친 CNN에 2000개의 region proposal들을 입력받아 4096 차원의 feature vector를 추출한다.
SVM
CNN 모델로부터 4096 차원의 feature vector를 받아 linear SVM을 통해 classification을 진행한다.
위에서 언급했던 것처럼 부족한 train 데이터로 인해 SVM이 softmax보다 더 좋은 성능을 보여주었기 때문에 classifier로 SVM을 사용한다. 이 classifier는 feature vector들의 점수를 class별로 매겨 object인지 아닌지를 판별한다.
위의 과정을 통해 각 2000개의 region proposal들이 분류되며, 각각 Object일 확률값을 score로 가지게 된다.
하지만 2000개의 bounding box를 모두 사용할 수 없기에 중복되는 box는 제거해줄 필요가 있다. 이때 사용되는 방법이 NMS(Non-Maximum Suppresion)이다.
NMS는 threshold를 통해 같은 object를 가리키고 있는지 다른 object를 가리키고 있는지 선택하게 한 후 중복되는 bounding box를 제거한다. NMS에 대한 설명은 밑에 링크를 달아두었다.
2022.12.30 - [딥러닝/CNN] - NMS(Non-maximum Suppression) 원리
NMS(Non-maximum Suppression) 원리
NMS의 목적은 동일한 object를 가리키는 여러 box의 중복을 제거하는 것이다. NMS에는 IoU의 개념이 포함되어 있으니 IOU를 먼저 알아야한다. 2022.12.30 - [딥러닝/CNN] - IoU(Intersection over Union)의 개념 및 코
smcho1201.tistory.com
bounding box regression
SVM으로 분류된 bounding box에 대해 regression을 적용했다.

selective search에 의해 만들어진 bounding box는 정확하지 않다.
이를 위해 object를 감싸도록 조정을 해주는 선형회귀 모델을 사용하는데 그것이 바로 bounding box regression이다. 이로 인해 bounding box가 물체를 정확히 감쌀 수 있도록 조정해준다.

아래 표를 보면 bounding box regression을 적용하였을 때와 적용하지 않았을 때 성능차이를 보여준다.

보시다시피 bounding box regression을 사용하였을 때 성능이 좋아지는 것을 확인할 수 있다.
단점
R-CNN은 하나의 이미지로부터 2000개의 region proposal을 입력 받아 convolution 연산을 진행하기 때문에 굉장히 연산량이 많다. 그렇기에 detection 속도가 떨어지고 효율성이 좋지 않다는 단점이 있다.
또한 CNN, SVM, Bounding Box Regression 이 3개의 모델이 multi-stage pipelines 이기 때문에 한번에 학습이 되지 않는다. 즉, end to end로 학습하는 것이 불가능하다.
이로 인해 SVM과 Bounding Box Regression에서 학습한 결과로 CNN을 학습하는 것이 불가능하다.



