
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- object detection
- 프로그래머스
- opencv
- Convolution
- Paper Review
- pytorch
- 코딩테스트
- Self-supervised
- transformer
- 알고리즘
- 머신러닝
- Semantic Segmentation
- 논문 리뷰
- 논문구현
- Segmentation
- 파이토치
- 옵티마이저
- Python
- programmers
- 코드구현
- Computer Vision
- 논문
- 인공지능
- Ai
- 딥러닝
- optimizer
- cnn
- ViT
- 논문리뷰
- 파이썬
- Today
- Total
Attention please
클러스터링 ; 데이터 전처리 - (2) 본문
2023.02.17 - [머신러닝] - 클러스터링 ; 데이터 살펴보기(EDA) - (1)
클러스터링 ; 데이터 살펴보기(EDA) - (1)
Clustering은 Data mining 분야에서 데이터들 간의 유사성을 기반으로 데이터들을 그룹으로 분류하는 기법이다. 머신러닝의 학습은 크게 두가지로 구분되는데 지도 학습(supervised learning) 과 비지도 학
smcho1201.tistory.com
지난 글에서 데이터를 가져온 후 각 변수들의 분포를 살펴보며, 데이터의 정보를 수집하였다.
이번 글에서는 수집한 데이터의 정보들을 근거하여 보다 학습이 잘 되도록 데이터 전처리(preprocessing) 작업을 해주어야 한다. 특히나 Clustering의 경우 데이터의 정보만을 가지고 유사도를 구하고 군집화를 하는 것이기 때문에 데이터 전처리 작업이 필수적이다.
먼저 Categorical 변수를 삭제하자.
군집화를 한다는 것은 데이터 간의 거리를 계산한다는 것인데 Categorical 변수는 거리를 측정하는데 도움이 되지 않는다. 즉, 학습에 사용하지 않기에 이 데이터에도 Gender 변수는 제거해주었다.
df = df.iloc[:, 1:]
df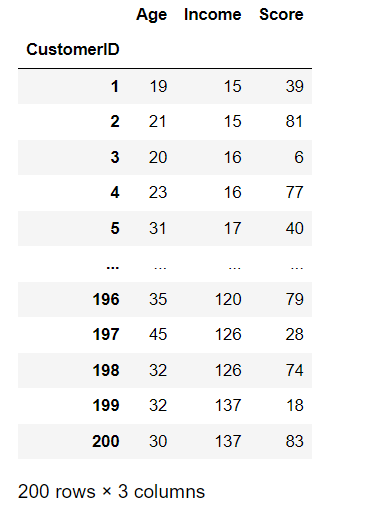
다음으로는 데이터의 분포가 symmetric한지 살펴봐야한다.
Age, Income, Score 변수들의 분포를 본 후 symmetric 하지 않는다면 정규화를 시켜주어야 한다. 먼저 각 변수들에 대해 각각 displot을 그려 분포를 살펴보자.
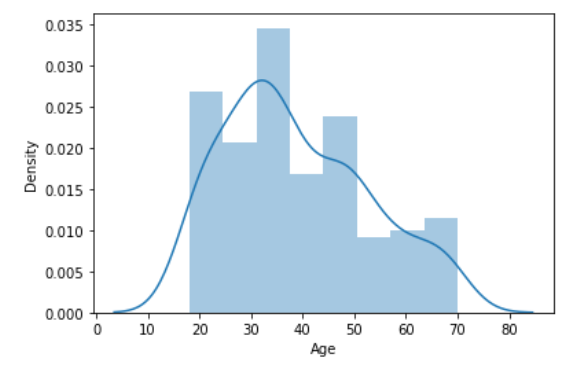
Age 변수의 경우 30세 ~ 40세의 수가 가장 많았으며, 오른쪽으로 꼬리가 길기 때문에 right-skewed 되어 있음을 확인할 수 있다.
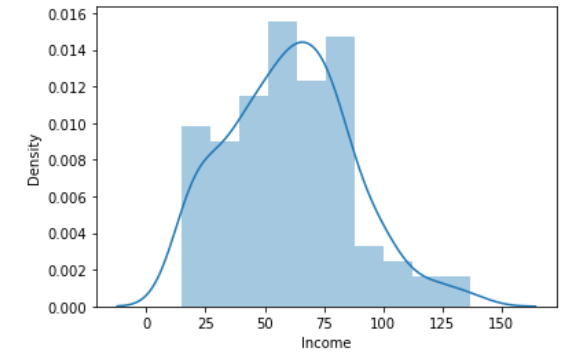
50 ~ 100k 의 소득을 가지는 경우가 가장 많았으며, 오른쪽으로 꼬리가 길기 때문에 right-skewed 되어있음을 알 수 있다.

Score 변수의 경우 symmetric 한 분포를 가지고 있다.
Skewness한 변수들을 조정하기 위해 Log transformation 을 사용하자.
Skewed 변수들을 Symmetric하게 변환하여야 한다. 또한 변환해야할 변수들 모두 0보다 크기 때문에 log transformation을 사용하는데 큰 문제가 일어나지 않으니 바로 적용시켜주자.
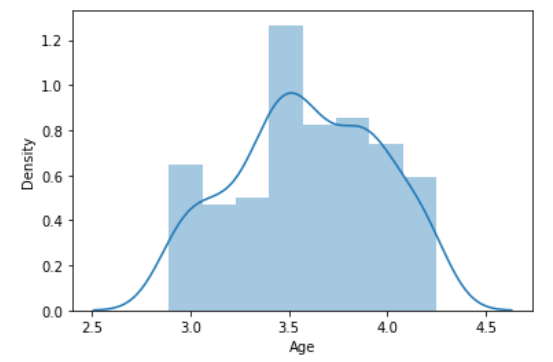
Age 변수에 대해 log를 적용하니 분포가 symmetric하게 변하였다.

Income 변수의 분포가 symmetric하게 조정되었음을 확인할 수 있다.
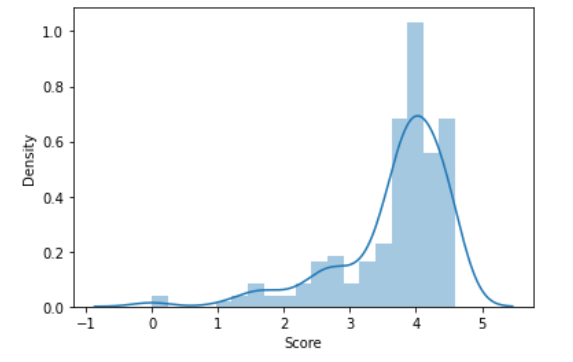
Score 변수에 대해 log를 적용하니 데이터가 오히려 skewed 되었다. 애초에 Score 변수는 정규화를 하기 전부터 symmetric 한 분포를 가지고 있었기에 Score 변수에 대해서는 따로 정규화 작업을 해주지 않았다.
이렇게 Age, Income 변수에 대해서만 정규화를 해주었고, Score 변수에 대해서는 따로 어떤 조치도 취하지 않았다.
Clustering을 하기 위해 표준화 작업을 해주자.
Clustering을 사용하기 위해서는 표준화 작업을 해야한다. 위에서 말했다싶이 군집을 만들기 위해서 데이터 간의 거리를 계산해야 하고 이를 위해서는 각 데이터의 변수값들의 평균과 분산이 같아야 한다.
이전 글에서 데이터의 수치를 살펴보았을 때 각 변수마다 평균과 표준편차가 차이가 있는 것을 확인했으니 표준화 작업을 해주자.
scaler = StandardScaler()
scaler.fit(df_log)
df_scaled = scaler.transform(df_log)
파이썬의 sklearn 라이브러리로 간단하게 표준화 작업을 해주었다.
'머신러닝' 카테고리의 다른 글
| 클러스터링 ; 데이터 살펴보기(EDA) - (1) (0) | 2023.02.17 |
|---|---|
| sklearn의 Simplelmputer으로 결측치 채우기 (0) | 2023.02.09 |
| 타이타닉 - EDA (2) | 2023.01.27 |

