
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Convolution
- 프로그래머스
- 인공지능
- 강화학습
- 머신러닝
- cnn
- Semantic Segmentation
- programmers
- Ai
- pytorch
- 딥러닝
- 논문구현
- 논문
- 파이토치
- Self-supervised
- 파이썬
- ViT
- 옵티마이저
- 코딩테스트
- Computer Vision
- 논문리뷰
- 코드구현
- 논문 리뷰
- 알고리즘
- opencv
- Segmentation
- object detection
- optimizer
- Python
- transformer
- Today
- Total
Attention please
[논문 리뷰] Mind with Eyes: from Language Reasoning toMultimodal Reasoning (2025) 본문
[논문 리뷰] Mind with Eyes: from Language Reasoning toMultimodal Reasoning (2025)
Seongmin.C 2025. 4. 10. 18:33이번에 리뷰할 논문은 Mind with Eyes: from Language Reasoning to Multimodal Reasoning 입니다.
https://arxiv.org/abs/2503.18071
Mind with Eyes: from Language Reasoning to Multimodal Reasoning
Language models have recently advanced into the realm of reasoning, yet it is through multimodal reasoning that we can fully unlock the potential to achieve more comprehensive, human-like cognitive capabilities. This survey provides a systematic overview o
arxiv.org
Survey of Multimodal Reasoning Approaches
최근, LLM(Large Language Model)은 언어 추론의 핵심 기술로 자리잡았습니다. 이 모델은 우수한 텍스트 생성 능력과 문맥 이해 능력을 활용하여 언어 기반 추론을 수행합니다. 최근 OpenAI-o1 이나 Deepseek-R1 과 같은 모델들은 수학적 연역, 논리 기반 질의응답, 코드 생성과 같은 과제에서 Chain-of-Thought(CoT) 프롬프트와 강화학습 전략을 통해 인간과 유사한 단계적 추론 능력을 입증하기도 하였습니다.
하지만 이런 텍스트 기반 추론의 한계도 점점 명확해지고 있습니다. 입력과 출력이 오직 텍스트라는 단일 모달리티에 제한되기 때문에, 이미지, 오디오 등 다양한 모달 간 상호작용이 필요한 실제 시나리오에는 한계를 보이고 있습니다.
이와 같은 한계의 솔루션으로 MLLM(Multimodal Large Language Model)이 등장하며, LLM의 추론 능력을 시각, 청각 등 다양한 모달리티와 통합하는 방법들을 시도하였습니다. 이중 초기에는 CoT 추론 패러다임을 Visual-Language 과제에 적용하고자 하였으며, 해당 프로세스는 일반적으로 다음과 같이 진행됩니다.
1. 텍스트 명령어 파싱
2. 이미지 특징 추출
3. 멀티모달 표현 융합
4. 추론 결과 생성
이런 MLLM은 비구조화된 멀티모달 데이터로부터 암묵적 상관관계를 학습하는데 강점이 있었으며, 우수한 일반화 성능을 보여주었습니다. 또한 강력한 텍스트 생성 능력은 보다 자연스러운 인간-인공지능 상호작용을 가능하게 하였습니다. 이러한 이유로, LLM을 멀티모달 추론의 핵심 엔진으로 사용하는 패러다임이 현재로선 주류로 자리잡고 있었습니다.
하지만 이런 LLM 기반 멀티모달 추론은 언어 전용 추론보다 더 많은 challenge들이 존재하며, 크게는 다음 두 가지가 있습니다.
1. 모달 간 의미 정렬(cross-modal semantic alignment) 보장
시각과 언어는 정보 밀도 및 추상 수준에서 크게 다릅니다. 이미지의 경우 세밀하고 저수준의 공간 정보를 전달하고, 텍스트는 고차원 개념적 의미를 담고 있습니다. 이런 간극을 해소하기 위해서는 강력한 특징 융합 메커니즘이 필요하죠.
2. 모달 간의 동적 상호작용과 협력 가능
현재로서 주류로 사용되고 있는 방식인 "시각-언어 특징 연결 + 텍스트 생성" 구조는 시각 정보의 생성 가능성을 제한하고, 모달 간의 동적 상호작용을 저해합니다.
결국 효과적인 멀티모달 추론을 위해서는 모델이 가장 관련 있는 모달리티에 적응적으로 집중하고, 정보 흐름을 능동적으로 조절할 수 있어야 합니다.

본 논문에서는 위 그림과 같이 최근의 멀티모달 추론 방법들과 벤치마크 데이터셋들에 대해 정리하여 보여줍니다. 또한 차세대 멀티모달 추론 시스템 개발을 위한 통찰을 언급하며 마무리됩니다.
Taxonomy of Multimodal Reasoning
멀티모달 추론은 단일 모달리티 내에서 고립적으로 이루어지는 활동이 아니며, 시각과 언어 모달리티가 협력하여 인지적 추론을 심화시키는 역동적인 상호작용 과정입니다.
기존 연구들의 경우, 거의 모든 방법들이 언어 공간 내에서 명시적으로 reasoning chain을 구성하고 있으며, 각 방법 간의 주요 차이는 시각 정보 처리의 전략적 계층 구조에 있다는 것을 확인할 수 있습니다.
본 논문에서는 시각 모달리티가 추론 과정에 어떻게 관여하는지에 따라, 접근법들을 두 개의 점진적 수준(progressive levels)으로 분류합니다.
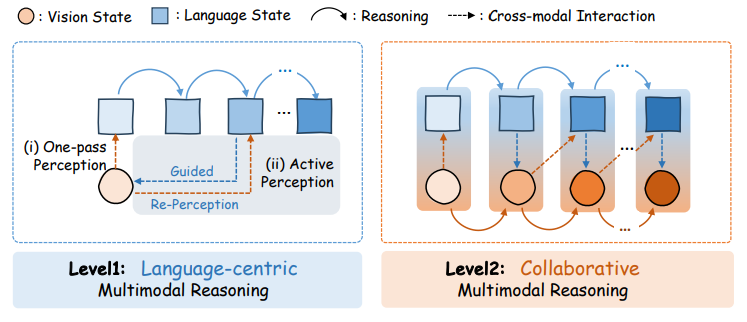
Level1: Language-centric Multimodal Reasoning
이 패러다임에서, visual modality는 주로 인식(perception)과 특징 추출(feature extraction)의 역할을 수행하며, 추론 전체는 language modality에 의해 주도됩니다.
(1) One-pass Visual Perception
- 이 방식은 시각 정보를 정적인 문맥 정보(static context)로 취급
- 모델은 입력 단계에서 이미지를 단 한 번만 인코딩(only look once)
- 이후의 정보 통합과 논리적 추론은 전적으로 언어 모달리티에 의존(ex. CLIP 기반의 전역 특징 추출 방식)
(2) Active Visual Perception
- 언어 모달리티가 생성된 중간 추론 단계들이 여러 차례의 시각 재인식(visual re-perception)을 유발
- ex) 동적 영역 cropping, zooming 등
- 모델은 텍스트 기반의 추론 단서를 활용하며, 필요한 시각 정보를 능동적으로 재탐색하며, 이를 통해 look-back 메커니즘을 형성
- One-pass 방식에 비해, 이 접근법은 추론 등 모달 간 정렬(multimodal alignment)의 신뢰도를 높이는 데 효과적임이 입증됨.
Level2: Collaborative Multimodal Reasoning
이 패러다임에서는 시각 기반의 행동 추론(visual action reasoning)과 시각 상태 업데이트(visual state update)가 함께 포함되기 때문에, 시각 모달리티는 단순한 수동적 인식자를 넘어서 언어 모달리티와 협력적 추론을 수행하는 주체로 확장됩니다.
(1) Visual action reasoning
- Visual modality는 언어 지시에 단순히 반응하는 것에 그치치 않고, 내부 추론 행동(internal reasoning action)을 자율적으로 생성
- ex) 이미지 편집을 위한 시각 도구 호출, 이미지 재구성을 위한 생성 능력 활용 등...
- 시각 특징 공간 내에서 명시적인 추론 경로(reasoning trajectory)가 드러나는 방식
(2) Visual state update
- 위와 같은 action을 실행함으로써, 모델은 시각 문맥 정보를 동적으로 업데이트
- ex) 보조선을 포함한 새로운 기하 도형 생성
- 업데이트된 시각 표현은 언어 모달리티에 새로운 제약 조건으로 피드백되어, 이후 중간 추론 단계들을 유도
One-pass Visual Perception
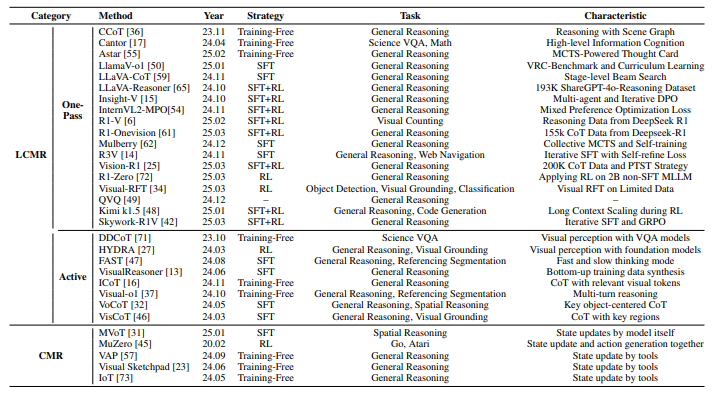
One-pass 시각 인식을 위해 크게 "프롬프트 기반 방식"과 "학습 기반 방식"으로 구분됩니다.
Prompt-based Solutions
이 방식의 연구들은 멀티모달 대형 모델에게 시스템 메세지를 통해 다양한 기능적 모듈의 역할을 부여하는 것으로 시작됩니다. 그 이후, 워크플로우 방식으로 중간 추론 결과나 전략을 생성하며, 이 결과들은 최종 정답을 도출하는 데 통합하여 사용됩니다. 해당 방식의 연구들은 다음과 같습니다.
- Cantor
: 시각 추론을 "결정 생성", "실행"의 두 단계로 나누어, 각 작업에 맞는 고수준 시각 특징을 생성하는 워크플로우 기반 모델 - CCoT
: 이미지 내 객체 간 관계를 scene graph로 구조화하여, 멀티모달 추론의 정확성과 해석 가능성을 높이는 방식 - AStar
: 인간 사고 방식에서 착안한 "사고 카드(thought cards)"를 활용해, MCTS 기반 다양한 추론 경로를 생성하고 이를 프롬프트로 사용하는 모델
Learning-based Solutions
이 방식의 연구들은 먼저 "chain of reasoning"이 포함된 멀티모달 학습 데이터셋을 구축한 뒤, 이후 SFT(Supervised Fine-Tuning)과 RL(Reinforcement Learning)을 MLLM에 적용한는 방식입니다.
1. Data Construction
가장 일반적인 접근은 GPT-4o, Deepseek-R1 같은 강력한 teacher 모델을 활용하여 knowledge distillation과 데이터 필터링을 수행하는 것입니다. 이는 일반적으로 "Chain-of-Thought 추론 생성" 과 "각 단계 또는 최종 추론 결과에 대한 점수 부여" 가 포함됩니다.
예를 들어, "Let's think step by step" 프롬프트를 사용해 VQA 데이터를 GPT-4o에 입력하고, CoT 출력 및 정답을 수집합니다.
- Llamav-o1: Rethinking step-by-step visual reasoning in llms
- Llava-cot: Let vision language models reason step-by-step
- Improve vision language model chain-of-thought reasoning
- Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning
또한 QwenVL, InternVL 같은 우수한 오픈소스 모델을 이용해 데이터 필터링을 수행하기도 합니다.
- Insight-v: Exploring long-chain visual reasoning with multimodal large language models
- Enhancing the reasoning ability of multimodal large language models via mixed preference optimization
한편, 언어 모델이 이미지를 처리하지 못하는 문제를 해결하기 위해 이미지를 캡션으로 변환하기도 하며,
음악 악보, 표, 이미지 등을 형식화된 텍스트 문법으로 기술하는 방식이 제안되기도 하였습니다.
이런 방식들은 언어 모델의 강력한 추론 능력을 활용할 수 있다는 장점이 있지만, 이미지를 텍스트로 변환하면서 정보 손실이 발생할 수 있다는 단점도 존재합니다.
또한, 정책 모델(MLLM)이 스스로 추론 경로 샘플을 생성하고, 이를 바탕으로 반복적 자기 학습(iterative self-training)을 수행하는 방식을 제안하기도 하였습니다. 두 연구 모두 부정 샘플을 활용하여 모델의 반성(reflection) 능력을 강화하는 학습 데이터를 생성합니다.
- Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search
- Visionlanguage models can self-improve reasoning via reflection
2. Training Paradigm
학습 패러다임으로는 크게 3가지로 나누어 볼 수 있습니다.
(1) SFT만 사용하는 방식(SFT Only)
- Llava-cot: Let vision language models reason step-by-step
- Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search
- Llamav-o1: Rethinking step-by-step visual reasoning in llms
- Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning
- Visionlanguage models can self-improve reasoning via reflection
(2) SFT + 강화학습 결합 (SFT + RL)
- Improve vision language model chain-of-thought reasoning
- Insight-v: Exploring long-chain visual reasoning with multimodal large language models
- R1-onevision: Open-source multimodal large language model with reasoning ability
- R1-v: Reinforcing super generalization ability in vision-language models with less than 3
- Enhancing the reasoning ability of multimodal large language models via mixed preference optimization
- Vision-r1: Incentivizing reasoning capability in multimodal large language models
(3) 강화학습만 적용 (RL Only)
- Visual-rft: Visual reinforcement fine-tuning
- R1-zero’s" aha moment" in visual reasoning on a 2b non-sft model
Active Visual Perception
멀티모달 추론 과제는 이미지에서 풍부하고 다층적인 시각 정보를 추출하는 것에 의존합니다. 하지만 현재의 MLLM은 시각적 이해 능력이 제한적이기 때문에, 문제 정의 단계에서 이미지를 한 번만 보는 One-pass 방식으로는 추론에 필요한 핵심 시각 정보를 충분히 획득하기 힘들 수 있습니다. 크게 다음 두 가지 문제가 발생할 가능성이 있습니다.
- One-pass 방식은 정밀한 시각 의미 이해(fine-grained visual semantic understanding)가 어려워 추론 중 hallucination이나 misunderstanding이 발생할 수 있음.
- One-pass 방식은 이미지에 존재하는 다양한 수준의 정보(granularity) 및 다양한 영역을 포괄적으로 포착하는 데 어려움을 겪어 핵심 정보를 놓치는 경우 발생할 수 있음.
이러한 단일 시각 인식 방식의 한계를 극복하기 위해, 일부 연구들은 멀티모달 추론 과정에 다중 회차의 시각 인식(multiple rounds of visual perception)을 도입하였습니다. 이는 인간이 이미지를 완전히 이해하기 위해 여러 번 바라보는 것처럼, 모델이 추론 과정 전반에 걸쳐 다양한 수준의 시각 정보를 반복적으로 추출함으로써, 추론 성능을 향상시키는 것을 목표로 합니다.
Self Iterative Perception
이 방식의 연구들은 MLLM 자체의 intrinsic visual capabilities를 활용하여 여러 차례의 시각 인식을 수행합니다.
- Interleaved-modal chain-of-thought
- Visual-o1: Understanding ambiguous instructions via multi-modal multi-turn chain-of-thoughts reasoning
또한, Visual-Language가 뒤섞인 다단계 추론 데이터(multimodal CoT data)의 부족은 MLLM 훈련을 하기 위해 극복해야 하는 필수 과제이며, 이를 위해 다음과 같은 연구들이 등장하였습니다.
- Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning
- Vocot: Unleashing visually grounded multi-step reasoning in large multi-modal models
Tool-assisted Iterative Perception
해당 패러다임은 MLLM의 시각 처리 능력에 한계가 존재하기 때문에, 특화된 시각 인식 도구를 활용하여 여러 차례의 시각 인식을 수행합니다.
- Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models
- Hydra: A hyper agent for dynamic compositional visual reasoning
- Visual agents as fast and slow thinkers
- From the least to the most: Building a plug-and-play visual reasoner via data synthesis
Collaborative Multimodal Reasoning
LLM은 강력한 추론 능력을 보여주지만, 일반적으로 시각 정보를 정적인 문맥(static context)으로 취급하며, 이를 추론 과정에 능동적으로 통합하지는 않습니다. 이 점을 보완하고자 추론 과정 중에 시각 정보가 실제로 변경되는 접근 방식인 Collaborative Multimodal Reasoning이라는 개념이 제안되었으며, 핵심은 다음과 같습니다.
언어 공간에서의 action generation 과
시각 공간에서의 state update를 동시에 수행하는 것
마치 이는 인간의 인지 과정과 비슷합니다. 예를 들어, 바둑 게임을 한다고 하였을 때, 사람은 다음 수를 선택하는 것뿐만 아니라 그 수에 따라 변화할 바둑판 상태도 미리 예측 및 이해를 하곤 하죠.
State Update without Action Reasoning
이 시나리오에서는 모델의 추론 과정이 next-state representation을 예측하는 방식으로 이루어집니다.
Joint Action Reasoning and State Update
이 시나리오에서는 모델이 먼저 명확히 정의된 추론 목표를 달성하기 위한 action을 생성하고, 이 행동을 기반으로 state를 업데이트합니다.
지금까지 정리하였던 multimodal reasoning method들은 다음과 같이 요약되어집니다.
Benchmark
Multimodal Reasoning을 위한 benchmark들은 주로 네 가지 주요 task에 중점을 두어 진행됩니다.
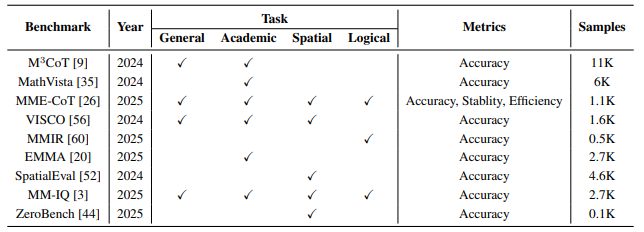
- General Reasoning
: 상식이나 일반적인 지식을 활용하여 질문에 적절히 응답하는 능력을 요구
( Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models )
( M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought ) - Academic-based Reasoning
: 과학, 수학, 코드 등 특정 분야의 지식을 적용하여 다단계 추론을 수행
( Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models )
( M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought )
( Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts )
( Mme-cot: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness, and efficiency )
( Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark )
( Visco: Benchmarking fine-grained critique and correction towards self-improvement in visual reasoning ) - Spatial Reasoning
: 모델이 객체 간의 공간적 관계를 인지하고 추론하는 능력을 평가
( Zerobench: An impossible visual benchmark for contemporary large multimodal models )
( Is a picture worth a thousand words? delving into spatial reasoning for vision language models ) - Logical Reasoning
: 논리 기호를 다루고 의미 기반 논리를 이해하는 능력을 측정
( Multimodal inconsistency reasoning (mmir): A new benchmark for multimodal reasoning models )
Metrics
Multimodal Reasoning 을 평가하기 위해 다양한 지표들이 제안되었으며, 크게 정확도(Accuracy), 안정성(Stability), 효율성(Efficiency) 로 구분됩니다.
정확도 (Accuracy)
멀티모달 추론에서는 최종 정답만 평가하는 것이 아닌 추론 과정에서 생성된 각 사고 단계의 정확성도 함께 평가하여야 합니다.
Accuracy=|Tmatched||T|
- T={t1,t2,…,tN}: 추론 사슬(Chain-of-Thought, CoT)을 구성하는 단계들
- N: 사고 단계의 길이 (즉, 단계 수)
- Tmatched: 정답과 일치하는 추론 단계들의 집합
안정성 (Stability)
CoT는 모델의 추론 능력을 향상시킬 수 있지만, 모델의 시각 인식 능력에 어떤 영향을 주는지는 명확하지 않습니다. 그렇기에 안정성은 CoT가 모델의 시각 인식 능력에 미치는 영향을 측정합니다.
Stability=AccPCOT−AccPDIR
- AccPCOT: CoT를 사용한 상태에서 시각 인식 과제를 수행했을 때의 정확도
- AccPDIR: CoT 없이 직접 정답을 응답했을 때의 정확도
효율성 (Efficiency)
효율성은 전체 추론 과정에서 실제로 유효한(reasoning에 기여한) 사고 단계의 비율을 의미합니다 .
- GPT-4o를 사용해 각 사고 단계가 최종 정답 생성에 기여했는지 여부를 평가
- 유효한 사고 단계의 비율을 기반으로 효율성 계산
Efficiency=r−α1−α,where r=|Trelevant||T|
- Trelevant: 정답과 관련된 추론 단계들의 집합
- T: 전체 추론 단계들의 집합
- α: 보정 상수 (baseline을 설정하기 위한 값)



