
- 분류 전체보기 (128)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- object detection
- Ai
- optimizer
- 옵티마이저
- Self-supervised
- Segmentation
- Semantic Segmentation
- 강화학습
- 논문구현
- opencv
- 머신러닝
- ViT
- 알고리즘
- 인공지능
- 코딩테스트
- Python
- 논문
- 논문리뷰
- Computer Vision
- Convolution
- programmers
- 파이토치
- cnn
- 프로그래머스
- 파이썬
- pytorch
- 딥러닝
- 코드구현
- 논문 리뷰
- transformer
- Today
- Total
Attention please
[논문 리뷰] VadCLIP: Adapting Vision-Language Models for Weakly SupervisedVideo Anomaly Detection (2023) 본문
[논문 리뷰] VadCLIP: Adapting Vision-Language Models for Weakly SupervisedVideo Anomaly Detection (2023)
Seongmin.C 2025. 4. 4. 23:43이번에 리뷰할 논문은 VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection 입니다.
https://arxiv.org/abs/2308.11681
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
The recent contrastive language-image pre-training (CLIP) model has shown great success in a wide range of image-level tasks, revealing remarkable ability for learning powerful visual representations with rich semantics. An open and worthwhile problem is e
arxiv.org
WSVAD(Weakly Supervised Video Anomaly Detection)
약지도 영상 이상 탐지(WSVAD)에서는 비디오 단위의 라벨 정보만 제공된 상태에서, 프레임 단위로 anomaly confidence를 예측할 수 있는 탐지기를 학습해야 합니다. 이때, 비디오 단위의 라벨이란 비디오 내 모든 프레임이 정상인 경우만 normal로 분류하며, 한 프레임이라도 비정상인 경우 abnormal으로 분류합니다.
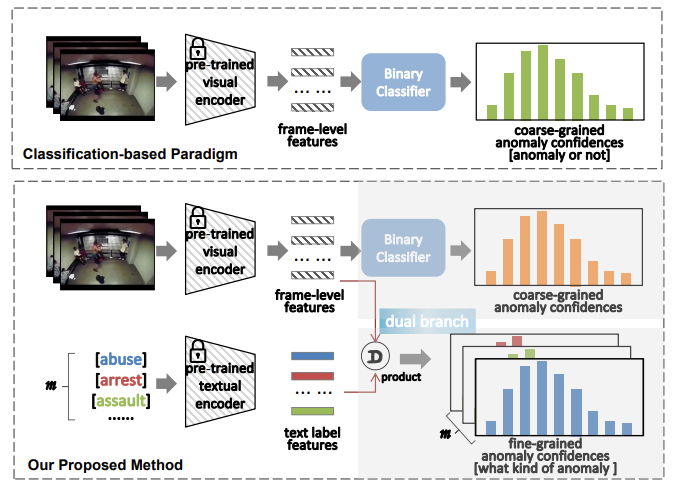
현재까지 WSVAD를 위한 연구는 다음과 같은 process를 따릅니다.
1. C3D, ViT 등과 같은 사전 학습된 visual model을 통해 frame-level의 feature를 추출
2. 추출한 feature들을 Multiple Instance Learning(MIL) 기반 이진 분류기에 입력하여 모델 학습
3. 예측된 anomaly confidence에 기반하여 abnormal event 탐지
위와 같이 분류 기반 접근을 사용할 경우 구조가 단순하고 좋은 성능을 보인다는 장점이 있지만, 시각-언어 간의 멀티모달 관계(cross-modal relationship)을 충분히 활용하지 못한다는 한계가 존재합니다.
CLIP(Contrastive Language-Image Pre-training)
CLIP을 포함한 VLP(Vision-Language Pre-training) 들은 의미적 개념을 반영한 일반화된 visual representation을 학습할 수 있게 하여, 다양한 비전 task에서 강력한 성능을 보여왔습니다.
[논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Language Supervision(2021)
이번에 리뷰할 논문은 Learning Transferable Visual Models From Natural Language Supervision 입니다. https://arxiv.org/abs/2103.00020 Learning Transferable Visual Models From Natural Language Supervision State-of-the-art computer vision systems a
smcho1201.tistory.com
CLIP은 contrastive learning을 통해, 이미지와 매칭된 텍스트는 가깝게, 매칭되지 않은 텍스트는 멀어지도록 embedding space에 정렬시키는 것입니다. 대규모 학습을 통해 학습된 CLIP은 representation learning 능력과 시각-언어 정렬 능력 모두에서 뛰어난 성능을 보여주었습니다. 이러한 CLIP을 기반으로 하는 task-specific model들이 다양하게 제안되어왔으며, 다양한 비전 과제에서 좋은 성능을 달성하였습니다.
하지만 이런 CLIP 기반 모델들은 주로 이미지 도메인에 초점이 맞춰져 있으며, image-text pair로 학습된 CLIP 을 약지도 환경의 복잡한 영상 이상 탐지로 효과적으로 transfer하는 방법에 대해서는 언급된 바가 부족합니다. 몇몇 연구들의 경우 CLIP의 visual encoder를 통해 추출한 feature를 활용하고 있으나, 이런 방법들은 visual 정보만을 사용하기 때문에, 시각-언어 간 의미 관계는 거의 활용하지 않습니다.
Challenge & Solution
본 논문에서는 WSVAD task에 CLIP의 범용 지식을 효과적으로 활용하기 위해서는 다음과 같은 3가지의 main challenge를 해결해야 한다고 합니다.
1. Temporal dependency를 어떻게 효과적으로 포착할 것인가?
2. CLIP이 학습한 시각-언어 지식을 어떻게 활용할 것인가?
3. 약지도 환경에서 CLIP의 성능을 어떻게 최적으로 유지할 것인가?
이에 대해, 본 논문에서는 CLIP을 기반으로 하는 새로운 WSVAD 패러다임인 VadCLIP을 제안합니다. 해당 모델은 다음과 같은 구성 요소들로 이루어져 있습니다.
1. LGT-Adapter (Local-Global Temporal Adapter)
- 시간 정보 모델링을 위한 경량 모듈
- Local Adapter : 인접 프레임 간의 지역적 시간 관계를 효율적으로 포착
- Global Adapter : 전체 시점에서의 전역적 흐름을 부드럽게 반영 (적은 파라미터 사용)
2. Dual Branch 구조
- C-Branch : 시각적 특징만으로 coarse-grained 이상 탐지 수행
- A-Branch : 시각-언어 정렬을 통해 fine-grained 이상 탐지까지 확장
- 두 분기를 연결함으로써 coarse + fine-grained 이상 탐지를 동시에 가능하게 함
3. Prompt 메커니즘
- Learnable Prompt : 사람이 직접 설계할 필요 없이, WSVAD에 CLIP 지식을 전이 가능
- Visual Prompt : C-Branch에서 얻은 이상 정보 기반으로, A-Branch의 텍스트 임베딩을 보완
4. MIL-Align
- A-Branch에서의 시각-언어 정렬 최적화를 위해, 가장 잘 일치하는 프레임을 선택하여 비디오 전체를 대표하도록 구성
Method
앞서 말씀드렸듯이, WSVAD의 목표는 비디오 수준의 라벨만으로 학습된 모델이 프레임 단위의 anomaly confidence를 예측할 수 있도록 하는 것입니다. 기존 연구들은 사전 학습된 3D 합성곱 모델을 사용하여 video feature를 추출한 뒤 MIL기반 이진 분류기에 입력하여 모델을 학습시켜왔습니다. 하지만 본 논문에서는 CLIP의 이미지 인코더를 백본으로 사용하여 비디오 특징을 추출함과 동시에, 텍스트 인코더도 함께 활용하여 시각적 콘텐츠와 텍스트 개념 간의 강력한 연관성을 활용하고자 합니다.

Local and Global Temporal Adapter
CLIP을 이미지 기반 모델에서 비디오 기반 과제(WSVAD) 로 확장하기 위해, temporal dependency를 모델링해야 합니다. 특히, WSVAD에서는 단기(short-range) 및 장기(long-range) 시각 의존성을 모두 효과적으로 학습하는 것이 매우 중요합니다. 이에 본 논문에서는 연산 효율성과 수용 영역(receptive field) 관점에서 local 과 global 시간 정보를 모두 반영할 수 있는 새로운 시간 모델링 방식을 설계하였습니다.

Local Moudle
우선 지역적인 시간 의존성을 포착하기 위해, CLIP의 이미지 인코더로부터 추출한 프레임 수준의 feature인 $ X_{clip} \in \mathbb{R}^{n \times d} $ 위에 Transforemr의 인코더 layer를 추가합니다.
- $ n $ : 비디오 프레임 수
- $ d $ : feature vector의 차원 수, 논문에서는 512로 설정
또한 이 레이어는 일반적인 Transformer 인코더와 다른 Swin Transformer의 attention 기법을 따릅니다.
[논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(2021)
이번에 리뷰할 논문은 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 입니다. https://paperswithcode.com/paper/swin-transformer-hierarchical-vision Papers with Code - Swin Transformer: Hierarchical Vision Transformer usin
smcho1201.tistory.com
위 방법론을 통해 self-attention 계산이 전역 범위가 아닌 지역적인 윈도우로 제한되는데, 간단하게 다음과 같이 연산됩니다.
- 프레임 특징 시퀀스를 시간 축을 기준으로 동일 길이로 겹치게(overlapping) 나눈 윈도우로 분할
- 각 윈도우 내부에서만 self-attention 계산을 수행
- 윈도우 간에는 정보 교환이 없음
이러한 방식을 통해 컨볼루션 연산과 유사하게 local receptive field를 형성하며, computational complexity도 더 낮아지는 장점을 얻을 수 있습니다.
Global Module
전역적인 시간 의존성(global temporal dependencies)을 추가로 포착하기 위해, GCN(Graph Convolutional Network) 모듈을 Local 모듈 뒤에 도입합니다. GCN을 VAD에 활용하기 위해, 특징 유사도(feature similarity)와 상대적 거리(relative distance) 관점에서 전역 시간 의존성을 모델링하기 위해 GCN을 사용합니다.
$$ X_g = \text{GELU} \left( \left[ \text{Softmax}(H_{\text{sim}}) \ ;\ \text{Softmax}(H_{\text{dis}}) \right] X_l W \right)
$$
- $ H_{sim} \in \mathbb{R}^{n \times n} $ : 프레임 간 시간적 유사도 기반 인접 행렬
- $ H_{dis} \in \mathbb{R}^{n \times n} $ : 프레임 간 시간 거리 기반 인접 행렬
- $ Softmax $ : 정규화를 통해 각 행의 합이 1이 되도록 조정
- $ X_{l} \in \mathbb{R}^{n \times d} $ : Local module에서 얻은 frame의 특징
- $ W \in \mathbb{R}^{d \times d} $ : 특징 공간 변환을 위한 유일한 학습 가능한 가중치 -> 모델의 경량화를 보여줌
위 식을 보면, 총 두 종류의 인접 행렬을 다루는 것을 확인할 수 있으며, Video를 시간 순서대로 보면, 각 frame을 node로 정의하고, "프레임끼리 얼마나 비슷한지", "시간적으로 얼마나 멀리 떨어져있는지"의 기준으로 노드 간 edge로 연결합니다.
또한 위에서 사용되는 Softmax 함수의 경우, 인접행렬을 각 row 별로 정규화를 함으로써 값들의 스케일에 의해 학습이 불안정해지는 것을 방지합니다. 각 행별로 정규화된 값들은 $ X_{l} $에 projection 되어 feature space를 바꿔줍니다.
그 후, $ W $ 가중치와 dot product를 수행하며, 이 연산에서 learnable한 요소는 $ W $뿐이라는 점에서 상당히 경량화에 초점을 맞추었음을 알 수 있습니다.
Feature Similarity Branch
위 Global Module 연산에서 사용되었던 $ H_{sim} $ 은 다음과 같이 연산됩니다.
$$ H_{\text{sim}} = \frac{X_l X_l^\top}{\|X_l\|_2 \cdot \|X_l\|_2} $$
Local module을 통해 얻은 frame feature인 $ x_{l} $에 대해 코사인 유사도를 구함으로써 프레임 간의 유사도 관계를 나타내는 인접 행렬을 구할 수 있습니다. 또한 threshold를 주어 너무 약한 유사도는 0으로 수렴하도록 수행합니다.
Position Distance Branch
또한, $ H_{dis} $은 다음과 같이 연산됩니다.
$$ H_{\text{dis}}(i, j) = \frac{-|i - j|}{\sigma} $$
- $ i, j $ : 프레임 인덱스
- $ \sigma $ : 거리의 영향 범위를 조절하는 하이퍼파라미터
프레임 간의 상대적 시간 위치 기반으로, 장기 시간 의존성을 포착하기 위해 위와 같이 거리 기반 인접 행렬을 정의합니다.
위 인접행렬의 이해를 돕기 위해, 간단하게 한가지 예시를 들어보자면, 4초짜리 비디오가 존재하고, 총 4개의 frame을 추출하였다고 가정해봅시다.
- F1 : 1초 frame
- F2 : 2초 frame
- F3 : 3초 frame
- F4 : 4초 frame
위와 같은 비디오에 대해 다음과 같이 연산이 수행됩니다.
- $ i=1, j=2 : - | 1-2 | = -1 $
- $ i=1, j=3 : -|1-3| = -2 $
- $ i=1, j=4 : -| 1-4 | = -3 $
최종적으로 아래와 같은 인접행렬 $ H_{dis} $ 가 나오게 되는 것이죠.
| F1 | F2 | F3 | F4 | |
| F1 | 0 | -1 | -2 | -3 |
| F2 | -1 | 0 | -1 | -2 |
| F3 | -2 | -1 | 0 | -1 |
| F4 | -3 | -2 | -1 | 0 |
위와 같은 인접행렬이 필요한 이유는 만약 1초 frame과 4초 frame의 내용 및 특징이 비슷하더라도, 시간 상 멀리 떨어져있다면, 그 중요도를 낮출 필요가 있습니다. 이때, 연결의 강도를 줄이기 위해 위와 같이 $ H_{dis} $에 -3 값을 매기는 것이죠.
Dual Branch and Prompt
기존의 WSVAD 연구들과 달리, 본 논문에서 제안하는 VadCLIP은 이중 분기 구조(Dual Branch)를 가지고 있습니다. 보통 이진 분류를 수행하는 C-Branch(Classification Branch)만 존재하는 반면, VadCLIP은 새롭게 비디오-텍스트 정렬 분기(video-text alignment branch)를 도입하였으며, 이를 A-Branch(Alignment Branch)라고 부릅니다.

C-Branch (Classification Branch)
C-Branch에서는, 특징 $ X $를 다음 구조의 이진 분류기에 입력합니다.
- FFN (Feed Forward Network) Layer
- FC (Fully-Connected) Layer
- Sigmoid 활성화 함수
이를 통해 프레임 단위의 이상 확률 $ A \in \mathbb{R}^{n \times 1} $을 예측하며, 수식은 다음과 같습니다.
$$ A = \text{Sigmoid} \left( \text{FC} \left( \text{FFN}(X) + X \right) \right) $$
여기서 Residual Connection을 함으로써 학습 안정성을 높입니다.
A-Branch (Alignment Branch)
A-Branch에서는 "abuse", "riot", "fighting" 등의 텍스트 라벨을 one-hot vector로 인코딩하지 않으며, 대신 CLIP의 텍스트 인코더를 통해 class embedding으로 변환합니다. 이때, CLIP의 pre-trained text encoder는 frozen된 상태로 사용됩니다.
그 후, 각 클래스 임베딩과 프레임 수준의 시각적 특징 사이의 유사도를 계산하여 alignment map $ M \in \mathbb{R}^{n \times m} $을 얻습니다. 여기서 $ m $은 텍스트 라벨(이상 클래스)의 개수입니다.
Learnable Prompt
위에서 텍스트 라벨로 사용되었던 "fighting", "shooting"과 같은 단어 및 짧은 구문들은 abnormal event를 충분히 요약하기에는 부족합니다. 본 논문에서는 텍스트 임베딩의 robust transferablility를 확보하기 위해, 기존의 클래스 임베딩에 학습 가능한 프롬프트(learnable prompt)를 추가합니다. 이는 다음과 같은 순서대로 진행됩니다.
1. 원래의 텍스트 라벨을 CLIP의 Tokenizer를 통해 클래스 토큰인 $ t_{init} $으로 변환합니다.
$$ t_{init} = Tokenizer(Label) $$
여기서 Label은 "fighting"과 같은 텍스트입니다.
2. $ l $개의 학습 가능한 context token들인 $ \{c_1, \dots, c_l\} $ 과 $ t_{init} $을 결합(concatenate)하여 하나의 문장 형태의 토큰 시퀀스를 만듭니다.
3. 해당 시퀀스는 다음과 같이 표현됩니다.
$$ t_p = \{c_1, \dots, t_{\text{init}}, \dots, c_l\} $$
Anomaly-Focus Visual Prompt
본 논문의 저자는 abnormal event에 대한 텍스트 라벨의 표현력을 향상시키기 위해, visual context를 활용하여 class embedding을 보완할 수 있는 방법을 탐구하였습니다.
1. 비디오 수준 시각 프롬프트 계산
우선, C-Branch에서 얻은 이상 확률 $ A $를 이상 주의로 사용하고, 이를 비디오 특징 $ X $와 dot product하여 비디오 수준 프롬프트 $ V $를 계산합니다.
$$ V = \text{Norm}(A^\top X) $$
- $ Norm $ : Regularization Function
- $ V \in \mathbb{R}^{d} $ : 이상 프레임 기반 시각 프롬프트
2. 텍스트 임베딩과 결합하여 최종 클래스 임베딩 생성
$$ T = \text{FFN}(\text{ADD}(V, t_{\text{out}})) + t_{\text{out}} $$
- $ ADD $ : 요소별 덧셈(element-wise addition)
- $ skip connection $ : 임베딩 정보 $ t_{out} $을 유지 및 보완
Objective Function
C-Branch: 이진 분류 손실 $ L_{bce} $
정상 및 이상 비디오 모두에서 이상 확률이 높은 K개의 프레임(top-K) 을 선택하여 이를 비디오 수준의 예측값으로 사용합니다. 이후, 예측값과 실제 비디오 라벨 간의 Binary Cross Entropy를 통해 분류 손실 $ L_{bce} $를 계산합니다.
A-Branch : MIL 기반 정렬 손실 $ L_{nce} $
A-Branch에는 다음 두가지 challenge가 존재합니다.
- anomaly confidence 없음
- 이진 분류가 아닌 다중 클래스 분류 문제
이를 해결하기 위해 기본 MIL 방식과 유사한 MIL-Align 메커니즘을 사용합니다. 이는 정렬 맵 $ M $을 이용해, 각 프레임 특징과 모든 클래스 임베딩 간의 유사도를 측정합니다. 각 프레임(행) 마다 Top-K 유사도 값을 선택하고 평균을 계산함으로써, 해당 비디오가 특정 클래스와 얼마나 잘 정렬되는지를 나타냅니다.
위 과정을 통해 $ S = {s_{1}, s_{2}, \dots, s_{m}} $ 벡터를 얻을 수 있으며, 이 벡터는 비디오가 각 $ m $개의 클래스(텍스트 라벨)와 얼마나 유사한지를 나타냅니다.
이후, 정답 클래스와 가장 높은 유사도를 갖도록 학습되길 기대하면서, 다중 클래스 확률 $ p_{i} $는 다음과 같이 softmax를 통해 계산됩니다.
$$ p_i = \frac{\exp(s_i / \tau)}{\sum_j \exp(s_j / \tau)} $$
마지막으로, 이 확률 $ p $와 실제 라벨 간의 Cross Entropy Loss를 통해 정렬 손실 $ L_{nce} $를 계산합니다.
Contrastive Loss: $ L_{cts} $
정상 클래스 임베딩과 이상 클래스 임베딩들 사이의 거리를 벌리기 위해, 추가적인 contrastive loss도 도입합니다.
$$ \mathcal{L}_{\text{cts}} = \sum_j \max \left( 0, \frac{t_n^\top t_a^j}{\|t_n\|_2 \cdot \|t_a^j\|_2} \right) $$
Loss Function
최종적으로 VadCLIP 학습을 위한 전체 손실 함수는 다음과 같습니다.
$$ \mathcal{L} = \mathcal{L}_{\text{bce}} + \mathcal{L}_{\text{nce}} + \lambda \mathcal{L}_{\text{cts}} $$
'논문 리뷰 > Anomaly Detection' 카테고리의 다른 글
| [논문 리뷰] Real-world Anomaly Detection in Surveillance Videos(2019) (0) | 2023.07.02 |
|---|
