
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬
- 머신러닝
- optimizer
- 인공지능
- Convolution
- transformer
- pytorch
- Paper Review
- ViT
- 알고리즘
- 코드구현
- Ai
- 프로그래머스
- 논문리뷰
- 논문구현
- Python
- opencv
- 논문
- 옵티마이저
- Computer Vision
- programmers
- 파이토치
- Semantic Segmentation
- 논문 리뷰
- 코딩테스트
- 딥러닝
- cnn
- Self-supervised
- object detection
- Segmentation
- Today
- Total
Attention please
Instruct pix2pix 모델을 활용한 텍스트 기반 캐릭터 자동 채색 시스템 구축 본문
Why Did We Start This Project?
이번 프로젝트는 생성 모델 중 캡션을 기반으로 하여 이미지를 변환시키도록 학습된 instruct pix2pix 모델을 활용하여 채색이 되지 않은 캐릭터 사진을 단순히 텍스트만으로 색을 칠하도록 하는 시스템을 만들어보고자 시작하게 되었습니다.

위 사진과 같이 원래 캐릭터의 모습은 왼쪽 이미지와 같습니다. 전체적으로 푸른색을 띄고있는 캐릭터이죠. 하지만 본 프로젝트에서 개발한 시스템을 기반으로 다음과 같이 텍스트를 입력해주었습니다.
Turn it into a creature with a white belly and a red face and back.
간단하게 설명하자면 기존 캐릭터의 푸른색을 띄고 있는 부분을 붉은색으로 색을 칠하라고 캡션을 입력해주었고 그 결과 오른쪽 사진과 같이 입력한 텍스트에 맞는 캐릭터가 출력되었습니다.
이와 같이 캐릭터의 색을 텍스트를 활용하여 사용자의 입맛대로 자유롭게 칠함으로써 기존의 수동적인 채색 작업을 좀 더 자동화하고 편리하게 할 수 있지 않을까? 하는 생각에 해당 프로젝트를 진행하게 되었습니다.
Model
텍스트만을 활용하여 이미지를 변환시키기 위해서는 해당 task에 부합하는 모델을 활용할 필요가 있었습니다. 마침 2023년도에 텍스트를 기반으로 한 image translation 모델인 instruct pix2pix 모델이 소개되었습니다.
https://github.com/timothybrooks/instruct-pix2pix
GitHub - timothybrooks/instruct-pix2pix
Contribute to timothybrooks/instruct-pix2pix development by creating an account on GitHub.
github.com
해당 모델의 경우 diffusion 기반 모델이며 GPT-3 모델을 활용하여 많은 수의 데이터셋을 구축하였다고 합니다. 이로 인해 다양한 도메인에 준수한 성능을 보이며 zero-shot 성능이 우수하다고 논문에서 언급되기도 하죠. 비록 저희 프로젝트에서 추구하는 바는 단순히 이미지를 변환시키기보단 이미지 속 캐릭터 머리, 몸, 꼬리 와 같이 부분적인 위치 정보를 파악하고 색을 칠하는 것이기에 단순 이미지 변환과는 거리감이 있지만 상태 파악을 위해 추가 작업 없이 시도를 해보았습니다.

실험은 위 이미지로 진행하였습니다. 현재 어떤 채색도 되지 않은 이미지이며, 전체적으로 초록색을 띄게 하기 위해
"Color the character's body green and the eyes red."
와 같이 텍스트를 입력하여 이미지를 생성해보았습니다. 그 결과 다음과 같은 이미지가 출력되더군요...

그 어떤 사람이 봐도 좋은 결과다! 라고 하기에 어려운 이미지가 나왔습니다. 앞서 말했던 것과 같이 단순 이미지 변환과는 저희 프로젝트의 도메인과 거리가 멀어 나오는 결과라고 생각이 됩니다만...일단 문제에 대해 좀 더 구체화를 해보았습니다.
1. 배경과 객체의 구분을 하지 못한다.
저는 분명 캐릭터의 몸과 눈에 대해서만 색을 칠하라 텍스트를 입력하였지만 결과는 배경과 캐릭터 전부 색을 칠한 이미지가 출력되었습니다. 그래도 한가지 희망? 이라고 한다면 캐릭터의 눈의 색이 좀 더 진한 색으로 채색되었다는 점입니다. 최소한 텍스트의 eyes 라는 텍스트가 이미지의 어떤 위치에 해당하는 것인지 인지하고 있다는 것이죠.
2. 텍스트 내의 색 정보를 정확하게 인지하지 못한다.
텍스트를 보면 몸은 초록색, 눈은 붉은색으로 색을 칠하도록 입력하였지만 정작 칠해진 색은 초록색 뿐이었습니다. 위에서 언급했듯이 눈의 위치를 인지하고 다른 색으로 칠한 모습은 볼 수 있었지만 좀 더 진한 초록색으로 칠해졌을뿐 붉은색은 전혀 없죠.
위 문제를 해결하기 위해서는 단순히 image translation 도메인을 저희 프로젝트 도메인인 image coloring 으로 구체화를 시킬 필요가 있습니다. 이를 위해 해당 모델에 대해 fine-tuning 을 진행하였습니다.
Datasets
instruct pix2pix 모델을 학습하기 위해서 필요한 데이터의 구조는 "변환 전 이미지", "변환 후 이미지", "변환 정보를 담은 캡션" 이렇게 3가지가 묶여있어야합니다. 저희는 캐릭터의 색을 변환해야하기 때문에 포켓몬 데이터셋을 수집하였습니다.

약 800장 정도의 데이터셋을 수집하였으나 문제는 변환 정보를 담은 캡션에 있었습니다. 일단 이미지에 비해 캡션까지 있는 데이터는 300장 정도로 절반도 존재하지 않았으며, 캡션의 퀄리티가 저조하다는 문제가 있습니다. 심지어 일부 데이터의 경우 위 사진과 같이 분명 다른 캐릭터임에도 불구하고 캡션의 내용이 거의 비슷하였으며, 색에 대한 정보는 전혀 포함하고 있지 않았다는 문제가 존재했죠.
해당 문제를 해결하기 위해 단순히 존재하는 데이터셋을 사용하기보다 좀 더 가공하는 방향을 선택하였습니다. 캡션의 양을 늘리고 퀄리티를 높이기 위해 image captioning 모델을 활용하였습니다.
Image captioning
image captioning을 위해 사용한 모델은 총 2가지 입니다. 그 중 첫번째로는 CNN-LSTM 모델을 사용하였습니다.

아주 대표적인 image captioning 모델 중 하나로 이미지를 처리하는 CNN 인코더와 LSTM 디코더로 이루어진 모델입니다. 당연하게도 supervised-learning을 기반으로 학습되었기 때문에 캡션을 생성하기 위해서는 데이터가 필요하죠. 앞서 수집하였던 데이터셋 중 캡션이 포함된 300 정도의 데이터셋을 활용하여 학습을 진행하였습니다.
두번째로 사용한 모델은 CLIP(Contrastive-Language-Image-Pretrained) 입니다.
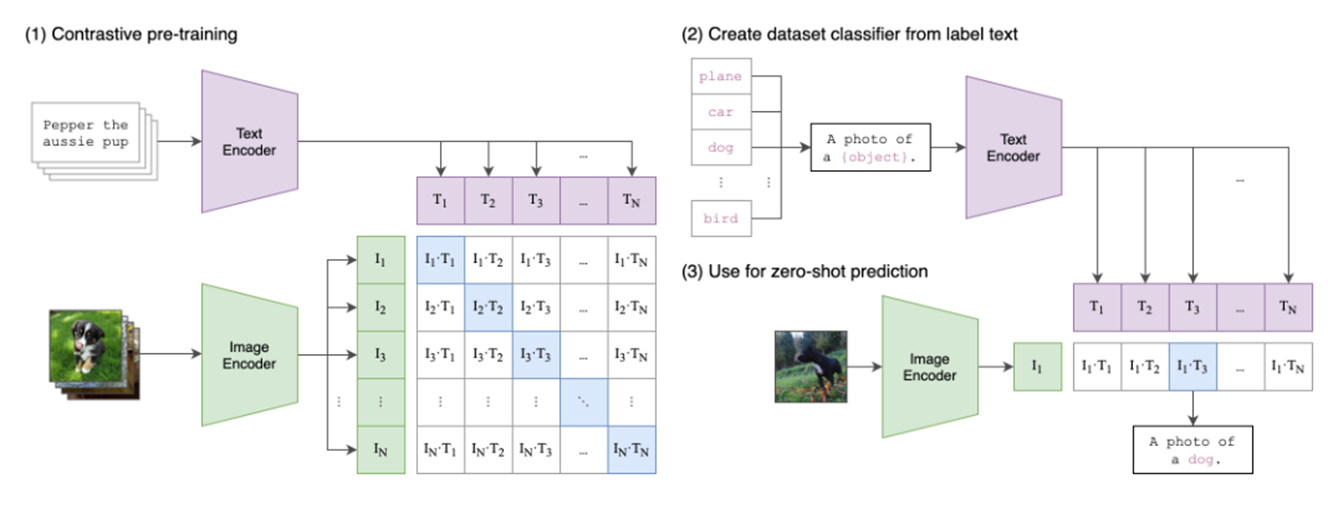
모델 이름에서 알 수 있듯이 Contrastive learning을 기반으로 한 모델입니다. 텍스트와 이미지의 정보를 줄이고자 contrastive learning 기법을 사용하였기에 unsupervised learning 기반 모델이라 할 수 있죠. 즉, 새로운 데이터셋에 대해 캡션을 생성할 때 추가로 학습이 필요하지 않다는 것이죠.
CNN-LSTM의 경우 지도 학습 기반 모델이기에 프로젝트의 도메인에 맞는 데이터셋으로 학습이 진행됩니다. 즉, 도메인에 최적화하기에 유리하다는 것을 의미합니다. 다만 위에서 말했듯 데이터셋의 퀄리티가 이미 떨어져있는 상태이기에 최적화를 하는 것 자체가 문제가 될 수도 있음을 의미하기도 하죠. 반면 CLIP의 경우 비지도 학습 기반 모델이기 때문에 최적화된 결과를 기대하기에는 어려울 수 있습니다. 하지만 전반적으로 우수한 정보 특히 이미지 내 캐릭터의 색 정보를 잘 추출할 수 있음을 기대할 수 있습니다.
학습이 완료된 CNN-LSTM과 CLIP의 결과를 다음 이미지에 대해 출력해보았습니다.

CNN-LSTM :
Turn it into a drawing with a <unk> body, <unk> face, and <unk> horns.
CLIP :
Turn it into a close up of a cartoon bird with a red head and white wings, style of pokemon, werecrow, ultra-high resolution, kid named finger, cleanest image, wildfire, metalhead, soaring, tuxedo, black white red, folklore
CNN-LSTM의 결과를 보면 텍스트 중간중간 <unk> 라고 적혀있는 것을 확인할 수 있습니다. 이는 unknown token을 의미하며, 모델이 이해하지 못하는 부분에 대해 출력되는 토큰입니다. 다만 문제는 <unk> 토큰이 있는 부분이 캐릭터의 색을 포함하는 핵심적인 부분이라는 점이죠. 즉, 색을 칠하기 위해 활용하기에는 부족한 데이터셋임을 확인할 수 있습니다.
CLIP의 결과를 보면 캐릭터의 각 부분에 대한 색 정보를 잘 출력하는 것을 확인할 수 있습니다. 다만 텍스트의 완성도가 떨어지죠. 이는 비지도 학습 모델이기에 감수해야하는 부분인 것 같습니다. 그래도 색 정보를 잘 텍스트에 담았기에 데이터셋으로 활용하기에 괜찮다고 생각됩니다.
총 800장 정도의 데이터셋 중 300장 정도의 이미지에 대해서만 캡션이 존재했습니다. 나머지 500장의 캡션에 대해 위 2개의 모델을 활용하여 각각 캡션을 생성하였고 최종적으로 CNN-LSTM을 활용한 데이터셋과 CLIP을 활용한 데이터셋을 구축하였습니다.
Fine-tuning
데이터셋을 구축하였으니 이제 instruct pix2pix 모델을 학습할 단계가 왔습니다. 위에서 데이터셋을 구축할 때 CNN-LSTM과 CLIP 모델에 대해 따로 구축하였으니 그 결과를 비교해보기 위해 따로 fine-tuning을 진행하였습니다.

결과를 확인하기 위해 test용으로 총 5가지의 캐릭터를 선정하였습니다. 첫번째 줄에 해당하는 이미지가 채색이 되지 않은 이미지이며, 두번째 줄에 해당하는 이미지들이 기존 캐릭터의 모습 즉, 라벨에 해당되는 이미지입니다. 이제 텍스트를 입력하여 위 캐릭터의 색을 기존과 다른 색으로 변환을 시켜보려고 합니다.

위 이미지의 1열과 2열은 채색되지 않은 이미지와 변환에 대한 정보를 담은 캡션으로 입력값에 해당됩니다. 그 결과 CNN-LSTM 모델로 구축한 데이터셋에 대해 학습된 instruct pix2pix 모델의 결과는 3열과 같습니다. 비록 색정보가 풍부하지 않았지만 기존 데이터셋 내에 300개 정도의 캡션 덕분인지 좋은 결과가 나왔습니다.
4열의 경우 CLIP 모델로 구축한 데이터셋에 대해 학습된 instruct pix2pix 모델의 결과입니다. 3열의 결과에 비해 좀 더 디테일하게 색을 칠한 것을 확인할 수 있으며, 전체적으로 이미지의 퀄리티가 올라간 것을 확인할 수 있었습니다.
github : https://github.com/WEBAI-IAMAI/TEXT2POKEMON-Instruct-pix2pix
GitHub - WEBAI-IAMAI/TEXT2POKEMON-Instruct-pix2pix: We have fine-tuned the Instruct Pix2Pix model to create a system that can co
We have fine-tuned the Instruct Pix2Pix model to create a system that can colorize characters in images using only text. - GitHub - WEBAI-IAMAI/TEXT2POKEMON-Instruct-pix2pix: We have fine-tuned the...
github.com
'프로젝트' 카테고리의 다른 글
| pyautogui로 카카오톡 예약 메세지 보내기 (0) | 2023.08.14 |
|---|---|
| [OpenCV] OpenCV를 이용한 얼굴 감지 CCTV 만들기 (0) | 2023.01.10 |
| [OpenCV] OpenCV를 이용한 스캐너 만들기 (0) | 2023.01.09 |
| [딥러닝] KLUE 데이터를 활용한 북마크 분류문제의 해결 (0) | 2023.01.06 |
| [딥러닝] 의료영상 종류에 따른 병변 영역 분할 딥러닝 모델 별 성능 비교 (0) | 2022.12.14 |



