
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Python
- programmers
- 옵티마이저
- 논문구현
- 알고리즘
- object detection
- Self-supervised
- 인공지능
- Semantic Segmentation
- 머신러닝
- 논문 리뷰
- 코드구현
- optimizer
- 강화학습
- 프로그래머스
- 딥러닝
- 논문리뷰
- 파이썬
- Convolution
- 파이토치
- 코딩테스트
- Ai
- Computer Vision
- pytorch
- ViT
- Segmentation
- opencv
- 논문
- cnn
- transformer
- Today
- Total
Attention please
[논문 리뷰] simCLR : A Simple Framework for Contrastive Learning of Visual Representations(2020) 본문
[논문 리뷰] simCLR : A Simple Framework for Contrastive Learning of Visual Representations(2020)
Seongmin.C 2023. 7. 31. 04:50이번에 리뷰할 논문은 A Simple Framework for Contrastive Learning of Visual Representations 입니다.
https://paperswithcode.com/paper/a-simple-framework-for-contrastive-learning
Papers with Code - A Simple Framework for Contrastive Learning of Visual Representations
#4 best model for Contrastive Learning on imagenet-1k (ImageNet Top-1 Accuracy metric)
paperswithcode.com
일반적으로 딥러닝 모델은 라벨링된 데이터에 의해 학습을 진행하며, 이를 supervised learning 이라 부릅니다. 즉, 지도 하에 학습이 이루어진다는 것인데 만약 라벨링 없이 image와 같은 데이터만이 존재할 경우 unsupervised learning 을 수행할 수 있습니다. 정확히 말하자면 본 논문에서 제안하는 기법은 self-supervised learning 의 기법이며, 스스로 감독을 하여 학습을 한다 하여 self-supervised 라고 불립니다.
인간의 감독 없이(unsupervised) visual representation을 학습하는 방법에는 크게 2가지 접근법이 존재합니다.
- generative approach : 데이터의 분포를 직접 학습
- discriminative approach : class label 간의 경계를 찾는데 특화
하지만 generative approach 의 경우 input space의 pixel을 생성하거나 모델링 하는 방법을 학습하도록 진행되기 때문에 pixel 수준의 생성은 계산 비용이 많이 들고, representation learning에 필요하지 않을 수 있다는 점이 존재합니다. 반대로 discriminative learning의 경우 supervised learning에 사용되는 objective function과 유사한 objective function을 사용하여 representation을 학습합니다. 물론 discriminative learning 역시 input 과 label이 없는 데이터셋에서 파생된 pretext task를 수행하도록 network를 학습시키며, 이는 학습된 representation의 일반성을 제한시킬 수 있습니다.
The Contrastive Learning Framework
본 논문에서는 visual representation을 위해 simple하게 수행될 수 있는 framework인 simCLR을 소개합니다.
simCLR은 latent space에서의 contrastive loss를 통해 각각 독립적으로 augmentation된 같은 data example 간의 일치성을 maximize 함으로써 표현을 학습합니다.
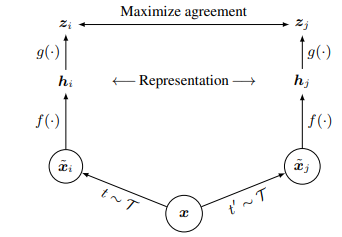
진행 방식은 다음과 같습니다.
- 같은 data example 인 $ x $에 대해 각각 두번 독립적으로 랜덤하게 stochastic data augmentation을 진행하여 $ \tilde{x_{i}} $ 와 $ \tilde{x_{j}} $ 를 생성합니다. 이 2개의 쌍에 대해 positive pair라 정의합니다.
- neural network 기반 encoder $ f(\cdot) $을 사용하여 augmented data 로부터 representation vector를 추출합니다. 본 논문에서는 $ f $ 함수로 ResNet을 채택합니다. 참고로 output에 average pooling layer를 통해 d차원의 vector를 추출하게 됩니다.

- representation을 contrastive loss가 적용되는 space로 mapping하는 작은 neural network projection head인 $ g(\cdot) $을 사용하며, 이때 $ g $함수는 1개의 hidden layer를 가지는 MLP로 구성되며 activation function으로 ReLU function을 사용하여 비선형성을 학습합니다.
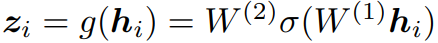
- 서로 같은 data로부터 독립적인 augmentation이 적용된 positive pair들을 포함하는 집합 $ \left\{ \tilde{x_{k}} \right\} $ 에서 $ \tilde{x_{i}} $에 대해 $ \tilde{x_{j}} $를 식별하는 것을 contrastive prediction task의 목표로 하여 진행됩니다.
우선 랜덤하게 N개의 example를 가지는 minibatch를 sampling 한 후 각 example에 대해 두번씩 augmentation을 진행하여 2N의 data point를 가지도록 합니다. 여기서 한가지 중요한 사실은 negative example을 sampling 하지 않았다는 것이죠. 본 논문에서는 negative example을 따로 준비하는 대신 positive pair가 주어졌을 때 이를 제외한 나머지 2(N - 1) 개의 augmented example들을 negative example로 정의했습니다.
positive pair(i, j) 에 대해 loss function은 다음과 같습니다.
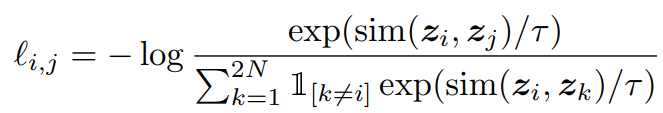
- $ sim(u, v)=u^{T}v/\left\| u \right\|\left\|v \right\| $ (cosine similarity)
- $ \mathbb{I}_{\left [ k\neq i \right ]} $ : indicator function으로 $ k\neq i $ 일때만 1로 지정
- T : temperature parameter로 분포의 entropy를 조정(모델 확률분포의 부드러움 제어)
- (i, j) or (j, i) : mini-batch안의 모든 positive pairs
temperature parameter는 loss function 내에서 positive pair 와 negative pair 사이의 관계를 조절하는 역할을 수행합니다.
- 1보다 큰 T : 모델은 positive pair와 negative pair 사이의 차이를 덜 구별하게 하여 similarity score가 더 평탄하게 분포되도록 합니다. 이는 더 많은 불확실성을 가지며, 모든 가능한 쌍을 고려하도록 하죠.
- 1보다 작은 T : 모델은 positive pair와 negative pair 사이의 차이를 더욱 명확하게 구분하게 하여 similarity score가 더욱 뾰족하게 분포됩니다. 이는 모델이 확신에 찬 예측을 하게 하지만 데이터의 다양성을 덜 포착시킵니다.
simCLR의 전체적인 학습 알고리즘은 다음과 같습니다.

Training with Large Batch Size
simCLR은 contrastive learning을 간단하게 하는 것을 목표로 하고 있습니다. 학습을 보다 단순하게 구성하기 위해 따로 memory back를 사용하는 대신 size가 큰 batch를 사용합니다. 하지만 큰 batch size는 SGD, Momentum으로 학습할 때 불안정할 수 있기 때문에 LARS optimizer를 사용합니다.
Data Augmentation for Contrastive Representation Learning
본 논문에서는 augmentation으로 random crop, resize(with random field), color distortions, Gaussian blur 를 사용합니다.

위와 같은 여러 종류의 augmentation 기법들에 대해 개별 효과와 구성의 중요성을 파악하기 위해 augmentation을 개별적 혹은 쌍으로 적용할 때의 성능을 조사해야합니다.
하지만 한가지 문제가 있는데 본 논문에서 사용한 데이터셋인 ImageNet dataset의 경우 각 image들의 크기가 제각각입니다. 학습을 위해서는 항상 crop과 resize를 적용해야하죠. 이는 개별적으로 augmentation의 효과를 파악하기에 방해가 됩니다.
이를 해결하기 위해 본 논문은 모든 이미지에 대해 기본적으로 random crop과 resize를 적용한 후 pair 중 한 branch에 대해서만 augmentation을 수행하고 나머지 branch는 정체성으로 두어($ t(x_{i}=x_{i}) $ asymmetric data augmentation(비대칭 데이터 증강)을 수행합니다. 이를 통해 추가적인 data augmentation의 영향을 판별할 수 있게 되죠.
그렇다면 augmentation을 1개만 적용했을 때와 쌍으로 적용했을 때 어떤 것이 더 representation을 잘 학습할 수 있을까요? 이에 대해서도 위에 언급했던 augmentation 기법들을 적용하여 실험을 진행한 결과 다음과 같은 결과를 볼 수 있었습니다.

single transformation 만으로는 좋은 성능을 보여주지 않음을 확인할 수 있습니다. 즉, augmentation을 조합하여 contrastive learning을 했을 때 더 좋은 성능을 보여준다는 것이죠. 사실 이는 당연한 결과입니다. 단순하게 한가지 augmentation을 적용하는 것보다 조합하여 augmentation을 진행하는 것이 contranstive 작업을 진행할 때 더 어렵게 예측하도록 하겠죠. 이는 보다 더 데이터의 본질적인 representation을 학습할 수 있게 할 수 있음을 의미합니다.
또한 random cropping과 random color distortion 을 조합했을 때 가장 좋은 성능이 나오는 것을 확인할 수 있습니다. 그렇다면 왜 단순히 random cropping 만을 사용했을 때에 비해 color distortion을 조합했을 때 성능이 향상되는 걸까요?
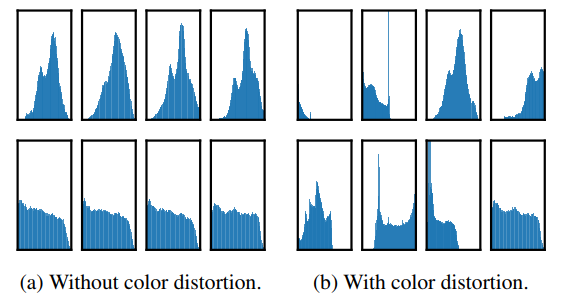
(a) 는 color distortion이 적용되지 않았을 때 각 branch에 대해 cropping 한 patch들의 pixel 분포입니다. 거의 비슷한 형태의 분포를 띄는 것을 확인할 수 있습니다. 즉, 모델은 단순히 색상 조합만으로 이미지를 구별하는 것이 충분함을 의미하게 되죠. 결국 본질적인 representation을 학습하기 힘들다는 것을 의미합니다.
반대로 (b) 와 같이 color distortion을 적용하게 되면 각 patch의 분포가 제각각의 형태를 띄는 것을 확인할 수 있습니다. 이는 보다 더 본질적인 representation을 학습할 수 있도록 합니다.
Contrastive learning needs stronger data augmentation than supervised learning
밑의 table 표는 unsupervised ResNet-50을 linear evaluation을 사용한 것과 supervised ResNet-50의 accuracy를 color distortion의 정도에 따라 보여줍니다.

위 표와 같이 color distortion을 강하게 줄 수록 unsupervised learning 된 linear evaluation의 성능이 점점 좋아지는 것을 확인할 수 있습니다. 하지만 supervised의 경우 오히려 성능이 유지되거나 떨어지는 모습을 확인할 수 있죠. 이는 unsupervised contrast learning이 supervised learning 보다 강력한(색상) 데이터 augmentation에 이득을 얻는 것을 의미합니다. 지도 학습에 정확성 향상을 불러오지 않는 data augmentation이 contrast learning에는 큰 도움이 될 수 있음을 보여준다고 할 수 있죠.
Architecture for Encoder and Head
지도학습과 마찬가지로 모델의 깊이와 너비를 증가시키는 것은 performance 향상에 도움이 됩니다. 이는 다음 그림을 보면 알 수 있습니다.
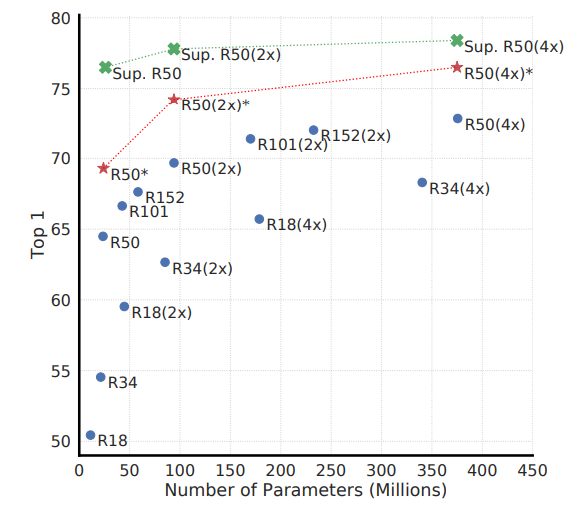
사실 모델의 크기가 커질 수록 성능이 좋아지는 것은 당연한 얘기입니다. 여기에서 중요하게 봐야할 것은 지도 학습과 비지도 학습의 관계를 봐야합니다.
위 figure의 파란색은 100 epochs 로 빨간색은 1000 epochs 로 contrastive learing을 진행하여 linear evaluation을 한 결과이며, 초록색은 90 epochs 만큼 supervised learning을 진행한 결과입니다.
모델의 크기가 커짐에 따라 supervised와 unsupervised의 성능 차이가 줄어드는 것을 확인할 수 있습니다. supervised의 경우 점점 성능 향상의 정도가 줄어들지만 이에 비해 unsupervised의 경우 어느 정도 계속 성능적으로 향상되는 것을 확인할 수 있죠. 이는 unsupervised가 supervised 보다 큰 모델에 대해 이점을 더 가진다는 것을 알 수 있습니다.
simCLR은 $ f $함수를 통해 데이터의 representation vector를 반환한 후 다시 $ g $ 함수를 적용하여 contrastive learning을 하기 위해 projection을 진행합니다. 여기에서도 한가지 생각해볼 부분이 존재합니다. 바로 선형성을 학습하도록 하는 것과 비선형성을 학습하도록 하는 것이죠.

결과를 보면 우선 projection하는 차원의 수는 성능적으로 큰 영향을 주진 않는다는 것을 확인할 수 있습니다. 하지만 전체적으로 linear보다는 non-linear하게 학습하는 것이 더 좋은 성능을 보여주는 것을 볼 수 있죠.
$ z=g(h) $ 는 data translation에 대해 invariant를 학습합니다. 즉 $ g $ 는 객체의 색상이나 방향 등을 제거합니다. 이는 $ h $ 에서 더 많은 정보를 형성하거나 유지할 수 있도록 유도하는 것으로 볼 수 있습니다. 만약 객체의 비선형성을 제거하지 않는다면 생상이나 방향 등을 참고하여 contrastive learning을 보다 더 쉽게 진행할 수 있겠죠.



