
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 코드구현
- 인공지능
- 코딩테스트
- 프로그래머스
- 논문리뷰
- object detection
- Ai
- 옵티마이저
- Computer Vision
- 논문구현
- transformer
- cnn
- opencv
- pytorch
- ViT
- Segmentation
- Python
- Convolution
- Self-supervised
- 파이썬
- Semantic Segmentation
- optimizer
- 알고리즘
- 논문 리뷰
- programmers
- 논문
- 딥러닝
- 파이토치
- 머신러닝
- Paper Review
- Today
- Total
Attention please
[논문 리뷰] Boundary Unlearning: Rapid Forgetting of Deep Networks via Shifting theDecision Boundary(2023) 본문
[논문 리뷰] Boundary Unlearning: Rapid Forgetting of Deep Networks via Shifting theDecision Boundary(2023)
Seongmin.C 2024. 9. 8. 18:07이번에 리뷰할 논문은Boundary Unlearning: Rapid Forgetting of Deep Networks via Shifting theDecision Boundary 입니다.
https://arxiv.org/abs/2303.11570
Boundary Unlearning
The practical needs of the ``right to be forgotten'' and poisoned data removal call for efficient \textit{machine unlearning} techniques, which enable machine learning models to unlearn, or to forget a fraction of training data and its lineage. Recent stud
arxiv.org

최근 딥페이크(deepfake) 기술을 악용하는 사례들이 많아지면서 많은 피해들이 발생하고 있습니다. 인공지능의 기술이 발전함에 따라 자연스럽게 따라오는 양날의 검이라고 할 수 있죠. 이와 같은 이유로 인공지능 자체의 성능 향상을 위한 연구 뿐만 아니라 보완을 위해 연구되는 분야 역시 존재합니다. 그 중에서도 이번에 소개해드릴 분야는 "Machine Unlearning" 입니다.
Machine Unlearning
Machine Unlearning이란 머신러닝 모델이 일부 학습 데이터를 잊도록 하거나 그 계통을 삭제시키는 것을 의미합니다. 그렇다면 "왜" 모델에 학습되었던 데이터의 일부를 잊도록 하고, 삭제해야할까요? 본 논문에서는 크게 2가지 이유를 제시합니다.
1. Right to be forgotten
European Union(EU) 이 제정한 General Data Protect Regulation(GDPR)은 개인에게 "잊혀질 권리"를 부여해야 하며, 개인 데이터의 삭제를 요청한다면 기업은 반드시 이를 삭제해야한다 라고 명시합니다. 요즘같이 딥페이크를 활용한 기술들이 논란이 되는 이유 역시 무단으로 타인의 얼굴 혹은 목소리 등의 데이터들을 사용하여 이를 악용하기 때문이죠.
2. The benefits of machine learning
만약 학습 데이터가 데이터 중독 공격(data poisoning attacks)에 의해 조작되었거나, 시간이 흘러 일부 데이터의 특징이 유효하지 않게 되면, 머신러닝 모델의 성능이 하락될 수 있습니다. 이 같은 경우, 모델이 일부 학습 데이터를 잊도록 하거나 삭제하여 보다 더 효율적인 모델로 개선을 할 수 있다는 장점이 존재합니다.
그렇다면 "어떻게" 학습되었던 데이터의 일부를 모델이 잊도록 할 수 있을까요?
사실 아주 단순하게 생각하면 잊기 위한 데이터를 제외시키고 다시 재학습(re-train) 시키면 문제는 간단하게 해결됩니다. 애초에 학습에서 제외시켰기 때문에 모델은 해당 데이터에 대해 어떠한 정보도 가지고 있지 않은 상태가 되겠죠. 하지만 데이터를 삭제해야할 일이 발생할 때마다 계속 재학습을 하기에는 너무 많은 시간과 비용이 발생한다는 치명적인 문제가 존재합니다. 즉, 보다 효율적이고 견고하게 "Unlearning"을 할 수 있도록 해야하죠.

위 그림은 학습시킨 데이터 중 일부를 제외하여 다시 재학습한 DNN(Deep Neural Networks) 모델의 결정 공간(decision space)를 시각화한 것입니다. 본 논문에서는 해당 그림에 대해 두 가지 특징을 언급합니다.
- 잊혀질 샘플들이 다시 훈련된 DNN 모델의 결정 공간 주위에 퍼져있다는 것은 잊혀질 샘플들의 결정 경계가 깨졌다는 것을 의미한다.
- 대부분의 잊혀질 샘플들이 다른 클러스터(Cluster)의 경계로 이동하는 데, 이는 결정 공간에서 클러스터의 경계에 위치한 샘플들이 예측에서 큰 불확실설을 가질 가능성이 높다는 것을 상기시킨다.
위 두가지의 관찰 결과는 자연스럽게 Machine Unlearning을 위한 두 가지 핵심적인 목표와 연결됩니다.
1. Utility guarantee
Unlearning 후에도 모델의 성능은 기존의 성능과 최대한 가깝게 유지되어야 합니다. 즉, 잊혀질 데이터를 제외한 나머지 데이터에 대해서는 좋은 성능을 유지해야 한다는 것이죠. 본 논문에서는 잊혀진 클래스의 경계만을 파괴하고, 나머지 클래스의 경계는 유지하도록 하여 목표를 달성합니다.
2. Privacy guarantee
Unlearning 후 모델이 잊어야 할 데이터에 대한 정보를 완전히 잊어야 합니다. 즉, 어떤 정보도 유출하거나 사용할 수 없도록 만들어야 함을 의미합니다. 이에 본 논문은 잊혀진 데이터를 다른 클러스터의 경계로 밀어내는 방식으로 달성합니다.
결국 데이터를 잊도록 한다는 것은 결정 공간 속 클래스를 구분하는 결정 경계를 얼마나 잘 조정하는가에 달렸다는 것이죠. 본 논문에서는 결정 경계를 이동시켜 Unlearning 하는 것을 Boundary Unlearning이라 소개하며, 총 두 가지의 방법론을 제시합니다.
- Boundary Shrink
- Boundary Expanding
Boundary Unlearning
우선 방법론에 대한 설명 이전에, 사용되는 notation들에 대해 간단한 설명을 드리겠습니다.
DNN 모델에 대해 분류를 위한 지도 학습을 진행한다고 했을 때, 사용되는 학습 데이터셋은 다음과 같이 표현할 수 있습니다.
$$ D = \left\{ x_{i},y_{i}\right\}^{N}_{i=1}\subseteq X \times Y $$
이때 $ x_{i} \in X $ 는 $ N $ 개의 데이터 셋 중 한개의 input을 의미합니다. 또한 $ y_{i} \in Y, Y = \left\{ 1, ..., K\right\} $ 는 $ K $개의 클래스들 중 대응되는 클래스 라벨을 의미하죠. 이와 같이 정의된 학습 데이터셋들 중 forgetting data는 $ D_{f} \subseteq D $라고 표기하며, 나머지 데이터인 remaining data는 $ D_{r} = D / D_{f} $ 라 표기합니다.
기존에 훈련 데이터셋인 $ D $로 학습된 Original DNN Model을 $ f_{w_{o}} $ 라 표현하며, forgetting data인 $ D_{f} $에 대해 Unlearning을 수행하게 되면, 모델의 파라미터가 $ w_{o} \rightarrow w^{'} $ 로 업데이트 됩니다. 정리하자면 Unlearning된 모델 $ f_{w^{'}} $ 이 나머지 데이터 $ D_{r} $ 로 retraining된 최적의 unlearning 모델인 $ f_{w^{*}} $ 와 유사시키는 것을 목표로 하는 것이죠.
본 논문에서 제안하는 것이 Boundary Unlearning 인만큼 결정 경계에 대해 정의를 집고 넘어가겠습니다.

$ i, j $는 클래스의 레이블을 의미하며, $ \max_{k} f^{k}(x) $ 는 모든 클래스 $ k $에 대해 모델이 예측한 확률 중 가장 높은 값을 의미합니다. 즉, 클래스가 0, 1, 2 가 존재한다 가정하였을 때, softmax의 결과값이 [0.4, 0.4, 0.2] 이라면, 클래스 0과 1의 결정 경계에 해당되는 샘플이라 할 수 있습니다. 하지만 softmax의 결과값이 [0.2, 0.2, 0.6] 이라면, 클래스 2에 대한 확률값이 가장 크기 때문에 클래스 0과 1의 결정 경계에 해당되는 샘플이라 할 수 없습니다.
Boundary Shrink
Boundary shifting을 위한 가장 직관적인 방법은 학습된 DNN 모델 $ f_{w{o}} $ 을 잊혀질 데이터에 무작위로 레이블을 지정한 후 finetuning을 하는 것입니다. 하지만 이 같은 방법은 나머지 클래스의 경계도 이동시키기에 잊지 않아야하는 나머지 데이터에 대한 utility를 저하시킨다는 문제가 존재합니다.

이에 대해 본 논문에서는 Boundary Shrink라는 방법론을 제시합니다.

위 식은 original model의 최적 해인 파라미터 $ w_{o} $에 대한 정의입니다. 훈련 데이터셋의 각 데이터셋에 대해 손실함수가 정의되고 그 값이 최소가 되는 방향으로 업데이트가 이루어집니다.

훈련 데이터셋들 중 forgetting data인 $ x_{f} $ 데이터를 위와 같이 노이즈를 추가합니다. 노이즈를 추가하는 방식은 다음과 같습니다.
1. $ \bigtriangledown _{x_{f}}L(x_{f},y,w_{o}) $
original model의 손실 함수에 대한 입력 데이터 $ x_{f} $의 기울기를 구합니다. 이는 original model이 forgetting data에 대해 어떤 방향성으로 인식하고 있는 지에 대한 gradient 정보를 얻을 수 있습니다.
2. $ sign $
1번 과정에서 구한 gradient의 방향성만을 추출하기 위한 과정입니다. 기울기 값을 그대로 사용하게 되면 각 데이터 포인트에 추가되는 노이즈의 크기가 불균형해질 수 있기 때문에 sign함수를 통해 기울기의 크기(gradient magnitude)를 무시하고, 각 방향이 양수인지 음수인지에 대한 정보만을 남겨놓습니다.
3. $ \epsilon $
위에서 구한 gradient의 방향성에 일정한 크기의 노이즈 크기를 추가합니다.
위 3가지 단계를 거쳐 나온 노이즈를 forgetting data인 $ x_{f} $에 더하여 업데이트합니다.

노이즈를 추가한 forgetting data인 $ x^{'}_{f} $ 를 original model에 입력시켜 softmax값을 추출합니다. 이를 통해 기존 레이블인 $ y $와 가장 가까운 다른 레이블인 $ y_{nbi} $를 얻습니다.

마지막으로 $ x_{f} $에 $ y_{nbi} $ 레이블을 할당하여 finetuning을 하여, 잊혀야 할 데이터를 가장 유사한 다른 클래스로 이동시킵니다. 이는 모델이 학습한 데이터 간의 관계를 최대한 보존하면서 결정 경계를 조정할 수 있게 됩니다.
$$ B^{(i,t)} = \left\{ x_{f}|argmax_{k}f^{k}_{w^{'}}(x_{f})=y_{nbi}=i\right\} $$
boundary shrink를 거쳐 새롭게 조정된 forgetting data의 결정 경계는 위 식과 같이 표현됩니다. 위 식의 $ i $는 $ x_{f} $가 이동할 잘못된 클래스를 의미하며, $ t $는 원래의 잊혀야할 클래스를 의미합니다.
Boundary Expanding

앞서 소개했던 Boundary shrink 기법은 utility 와 privacy guarantee를 모두 만족시킵니다. 다만 forgetting data의 이웃한 클러스터를 검색하는데 어느정도의 시간이 소요된다는 특징이 있습니다. 이에 본 논문에서는 보다 빠르게 boundary unlearning을 수행할 수 있는 Boundary Expanding 기법을 소개합니다.
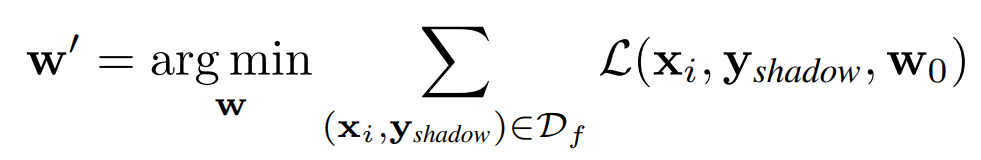
위 방법론은 다음과 같은 순서로 진행됩니다.
1. Shadow Class 추가 생성
기존 모델이 10개의 클래스를 분류하는 모델이라면, 11번째 뉴런을 추가하여, shadow class를 생성합니다.
2. forgetting data를 shadow class로 재할당
기존의 forgetting data가 클래스 A로 분류되었다면, 해당 데이터를 클래스 A가 아닌 새롭게 추가된 shadow class로 할당합니다.
3. Finetuning
추가된 새로운 shadow 뉴런에 대해 미세 조정을 합니다.
4. shadow 뉴런에 대해 pruning
추가하였던 shadow 뉴런을 제거하여 모델이 더이상 forgetting data를 처리하지 않도록 합니다.
Experiment
데이터셋의 경우 CIFAR-10 데이터셋과 VGGFace2 데이터셋을 사용합니다. 이를 통해 image classification과 face recognition 의 unlearning performance를 테스트 합니다.
비교를 위한 baseline으로는 다음과 같이 총 6가지의 방법론을 사용합니다.
- Retrain
- Finetuning
- Random Labels
- Negative Gradient
- Fisher Forgetting
- Amnesiac Unlearning
위 방법론 중 Retrain은 forgetting data를 제외시키고 나머지 데이터에 대해 재학습시키는 방법론입니다. 시간은 오래걸리지만, Unlearning 방법론 중 가장 performance가 높을 수 밖에 없죠. 이와 같은 이유로 Retrain의 결과를 Unlearning의 Ground Truth로 사용합니다.
Machine Unlearning을 평가하는 데 가장 중요한 두가지 요소는 위에서 소개했던 "Utility guarantee" 와 "Privacy guarantee" 입니다. 각각에 대해 다음과 같은 지표들을 통해 평가를 진행합니다.
<utility guarantee>
- $ D_{r} $ : accuracy on the remaining training data
- $ D_{f} $ : accuracy on the forgetting training data
- $ D_{rt} $ : accuracy on the remaining testing data
- $ D_{ft} $ : accuracy on the forgetting testing data
<privacy guarantee>
- Attack success rate(ASR)

위 표는 각 데이터셋에 대해 기존 베이스라인과 Boundary Shrink, Boundary Expanding 방법론들의 성능 비교를 보여줍니다. Utility guarantee에 대해 평가하기 위한 실험이며, Boundary Shrink를 사용하였을 때의 성능이 Retrain, Finetuning 다음으로 뛰어난 것을 확인할 수 있습니다. Boundary Expanding의 경우 Shrink에 비해 $ D_{f} $에 대한 잔여 정보가 존재하는 것을 확인할 수 있지만, 단순히 랜덤하게 레이블을 지정하여 학습하는 Random Labels 기법에 비해 적은 잔여 정보를 남기는 것을 확인할 수 있습니다. 이를 통해 Boundary Expanding을 성능과 시간 사이의 절충점을 제공하는 더 빠른 대안으로 사용할 수 있음을 의미합니다.

위 그림은 두 데이터셋에 Privacy guarantee 를 평가하기 위한 ASR(Attack Success Rate) 수치를 보여줍니다. 수치가 높을 수록 Privacy에 대한 보장이 없음을 의미하며, Utility guarantee 평가에서 우수한 성능을 보여주었던 Finetuning이 Privacy guarantee 평가에서는 처참한 모습을 보여줍니다. 이에 반해 Boundary Shrink와 Boundary Expanding 방법론 모두 준수한 성능을 보여주는 것을 확인할 수 있습니다.

위 그림은 각 베이스라인과 Boundary Unlearning 기법의 소요되는 시간을 보여줍니다. 성능이 뛰어놨던 Retrain의 경우 시간 비용이 아주 크게 나타나는 것을 확인할 수 있죠. 그에 반해 Boundary Unlearning 기법들은 시간 비용이 굉장히 적으며, 그 중에서도 Boundary Expanding 기법은 Shrink에 비해 더 적은 시간 비용을 가집니다.

위 이미지는 각 Unlearning 기법들의 Attention map을 출력한 그림입니다. Retrain 모델의 attention map을 통해 unlearning되었을 때 모델이 얼굴 영역에 집중하지 않는 다는 것을 확인할 수 있습니다. Boundary Shrink로 unlearning된 경우 모델의 주위를 오직 배경에만 집중시키도록 한 것을 확인할 수 있습니다. Boundary Expanding의 경우 주위를 완전히 배경으로 전환시키지 못했지만, 여전히 얼굴 외부 영역으로 집중을 전환시킨 것을 확인할 수 있습니다. 이러한 결과를 통해 unlearning된 모델의 출력에 잊혀야 할 데이터에 대한 정보가 거의 포함되지 않았음을 확인할 수 있죠.

위 그림은 forgetting data의 결정 경계가 어떻게 이동하는지를 더 명확히 확인하기 위해, unlearning 전후의 결정 경계를 시각화한 것입니다. Boundary Shrink를 적용한 후, forgetting data가 가장 가까운 클래스로 예측되는 것을 확인할 수 있습니다. 비록 클러스터가 완전히 퍼지지는 않았지만, retrained 모델처럼 forgetting data의 결정 공간이 근처의 클래스에 의해 나눠지는 것을 확인할 수 있습니다. 또한 Boundary Expanding의 경우 forgetting data의 클러스터가 중심에서 밀려나는 것을 확인할 수 있습니다. 이와 같이 Boundary Unlearning은 모델의 결정 경계를 Retrained 모델의 경계와 유사하게 만들어 Unlearning performance를 달성하게 됩니다.

위 그림의 경우 모델 출력의 엔트로피 분포를 보여줍니다. 엔트로피가 낮다는 것은 모델이 해당 데이터를 예측할 때 보다 더 확신을 가지고 예측함을 의미합니다. Original Model의 결과를 보면, $ D_{r} $과 $ D_{f} $에 대한 출력의 엔트로피는 테스트 데이터셋보다 낮은 수치를 가집니다. 이는 당연하게도 둘다 학습에 사용되었던 훈련 데이터셋이기 때문에 더 확신을 가지고 예측을 하는 것이죠. Retrained Model의 결과를 보면, $ D_{f} $의 엔트로피 수치가 크게 증가하는 것을 확인할 수 있습니다. forgetting data를 제외하고 학습을 진행하기 때문이죠. Boundary Shrink와 Expanding 의 결과 역시 Retrained의 결과와 유사한 것을 확인할 수 있습니다. 다만 Random Labels를 적용한 모델의 $ D_{f} $의 엔트로피 수치는 상당히 큰 것을 볼 수 있는데, 이는 Retrained model과 큰 차이를 보입니다. 이는 오히려 모델이 $ D_{f} $에 대해 지나치게 불확실한 상태가 되어, 공격자는 이를 기반으로 모델이 forgetting data를 처리하는 방식에 대해 더 많은 정보를 추출할 수 있습니다. 즉, 모델 내부의 불확실성을 이용해 공격자가 데이터를 추론할 가능성이 커지게 되는 문제가 발생하게 됩니다.