
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 코드구현
- ViT
- 옵티마이저
- optimizer
- 인공지능
- opencv
- reinforcement
- 논문리뷰
- 파이썬
- pytorch
- VLM
- Vision
- Ai
- 논문구현
- 딥러닝
- 강화학습
- cnn
- 파이토치
- 머신러닝
- Python
- object detection
- Learning
- 알고리즘
- Computer Vision
- Segmentation
- transformer
- 코딩테스트
- programmers
- 프로그래머스
- llm
- Today
- Total
Attention please
[논문 리뷰] Follow the Rules: Reasoning for Video AnomalyDetection with Large Language Models(2024) 본문
[논문 리뷰] Follow the Rules: Reasoning for Video AnomalyDetection with Large Language Models(2024)
Seongmin.C 2025. 8. 20. 15:41이번에 리뷰할 논문은 Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models 입니다.
https://arxiv.org/abs/2407.10299
Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models
Video Anomaly Detection (VAD) is crucial for applications such as security surveillance and autonomous driving. However, existing VAD methods provide little rationale behind detection, hindering public trust in real-world deployments. In this paper, we app
arxiv.org
Problem Definition
기존 Video Anomaly Detection(VAD)는 감시 비디오에서 드물거나 예상치 못한 활동을 식별하는 문제입니다. 이 문제는 이상 데이터가 매우 희귀하고 부족하다는 특성 때문에, 대부분 정상 데이터만을 학습하여 사용하는 원 클래스(one-class) 패러다임을 따릅니다.
하지만 기존 방법론들은 다음과 같은 두 가지 한계점들을 가집니다.
- 설명력 부재:
모델이 이상활동을 탐지하여도 "왜 이것이 이상인가?" 에 대한 논리적인 근거를 제공하지 못하며, 단순히 anomaly score만을 출력합니다. - 유연성 부족:
LLM을 사용할 경우, LLM이 pre-train된 일반적인 지식에 의존하기 때문에, 특정 시나리오에 맞는 맞춤형 이상 정의를 반영하기 어렵습니다. 예를 들어, "스케이트 보드 타기"는 일반적인 맥락에서는 정상이지만, 특정 구역에서는 이상 활동이 될 수 있습니다. 이러한 특수 규칙을 적용하려면 값비싼 모델 finetuning이 필요합니다.
본 논문에서는 기존의 한계점들을 해결하기 위해, VAD를 단순한 패턴 분류가 아닌 추론(reasoning) 문제로 재정의합니다. AnomalyRuler는 "왜 이상인가?" 에 대한 명확한 근거를 제공하며, 특정 시나리오에 유연하게 적응하는 시스템을 구축하는 것을 목표로 합니다.
이를 위해 저자는 다음과 같은 접근 방식을 사용합니다.
- 귀납(Induction):
소수의 정상 샘플로부터 LLM을 활용하여 정상과 이상을 구분하는 규칙 세트를 귀납적으로 도출합니다. 이를 통해 사전 학습된 LLM의 일반 지식을 특정 VAD 시나리오에 맞게 조정합니다. - 연역(Deduction):
도출된 규칙을 기반으로 텍스트 비디오를 분석하여, 규칙에 부합하지 않는 활동을 논리적으로 추론하여 이상으로 탐지합니다.

위 이미지를 보면 기존 VAD 방법론(a)과 LLM에 직접적으로 질문하여 이상 여부를 도출(b)하는 것과 비교했을 때, 본 논문에서 제안한 AnomalyRuler(c)의 차이를 확인할 수 있습니다.
Main contribution
본 논문의 주요 기여점들은 다음과 같습니다.
1. 규칙 기반 추론 프레임워크 제안
본 논문은 AnomalyRuler라는 LLM을 활용한 새로운 규칙 기반 추론 프레임워크를 제안합니다. 이는 "왜 이상인가?"에 대한 논리적 근거를 제공하는, 원 클래스(one-class) 영상 이상 탐지(VAD)를 위한 최초의 추론 접근 방식입니다. 기존 VAD 방법론들이 단순히 이상 점수만을 출력하는 한계를 극복하고, 신뢰성 있는 시스템을 구축하였습니다.
2. 효율적인 "Few-Normal-Shot" 프롬프트 방식
AnomalyRuler는 값비싼 전체 데이터셋 학습(full-shot training)이나 미세 조정(fine-tuning) 없이, 몇 개의 정상 샘플만으로 VAD 규칙을 도출하는 "few-normal-shot" 프롬프트 방식을 도입하였습니다. 이는 다양한 VAD 시나리오에 빠르고 유연하게 적용할 수 있도록 합니다.
3. 견고성 향상 전략
AnomalyRuler의 견고성을 강화하기 위해 세 가지 핵심 전략을 제안하였습니다.
- 규칙 집계(Rule Aggregation): 규칙 생성 과정에서 발생할 수 있는 오류를 완화
- 인식 스무딩(Perception Smoothing): 시각적 인식 오류를 줄이고, 비디오의 시간적 일관성을 강화
- 견고한 추론(Robust Reasoning): 최종 추론의 정확도를 높이기 위해서, LLM이 규칙에 따라 탐지 결과 재확인
Method

위 이미지는 AnomalyRuler 파이프라인에 대해 보여주고 있습니다. 크게 두 가지 주요 단계인 귀납(Induction)과 연역(Deduction) 으로 구성됩니다.
귀납 단계는 다음과 같이 구성됩니다.
- 시각적 인식(Visual Perception): 정상 참조 프레임을 텍스트 설명으로 변환
- 규칙 생성(Rule Generation): 이 설명을 기반으로 정상 및 이상 여부를 판단하는 규칙 도출
- 규칙 집계(Rule Aggregation): 투표 메커니즘을 사용하여 규칙에 포함된 오류를 완화
연역 단계는 다음과 같이 구성됩니다.
- 시각적 인식(Visual Perception): 연속적인 프레임들을 설명으로 변환
- 인식 스무딩(Perception Smoothing): 시간적 일관성을 고려하여 인접한 프레임들이 유사한 특성을 공유하도록 설명 조정
- 견고한 추론(Robust Reasoning): 이전의 dummy 응답을 재확인하고 추론 결과 출력
Induction
귀납 단계에서는 몇 개의 정상 참조 프레임으로부터 VAD를 위한 규칙 세트를 도출하는 것을 목표로 하며, 크게 세 가지 모듈로 구성됩니다.

1. 시각적 인식(Visual Perception)
해당 모듈은 VLM을 활용하여 비디오 프레임을 텍스트 설명으로 변환합니다. Trainset에서 무작위로 선택된 각 프레임 $f_{\text{normal}_i }$가 포함된 소수의 정상 참조 프레임 $F_{\text{normal}} = \{f_{\text{normal}_0}, \dots, f_{\text{normal}_n}\}$를 정의합니다.
이후, 해당 모듈은 "사람들은 무엇을 하고 있나요?", "사람 외에 이미지에는 무엇이 있나요?" 와 같은 프롬프트 $p_v$와 함께 정상 참조 프레임의 텍스트 설명 $D_{\text{normal}} = \{VLM(f_{\text{normal}_i}, p_v) \mid f_{\text{normal}_i} \in F_{\text{normal}}\}$ 을 출력합니다.

이는 "이미지에 무엇이 있나요?" 라고 직접 묻는 대신 $p_v$를 설계하여 사람과 환경을 분리함으로써 다음과 같은 장점을 얻습니다.
- 모델의 주의를 장면의 특정 측면에 집중시켜 인식 정밀도를 높이고 세부 사항이 간과되지 않도록 함.
- 규칙을 인간 활동과 환경적 요소의 두 가지 하위 문제로 나누어 다음 규칙 생성 모듈을 단순화 함.
2. 규칙 생성(Rule Generation)
정상 참조 프레임의 텍스트 설명 $D^{\text{normal}}$을 사용하여, 고정된(frozen) LLM을 이용해 규칙($R$)을 생성하는 규칙 생성 모듈을 설계합니다($R = \{LLM(d_{\text{normal}_i}, p_g) \mid d_{\text{normal}_i} \in D_{\text{normal}}\}$). 여기서 프롬프트 $p_g$는 다음과 같습니다.


LLM이 관찰된 정상 패턴으로부터 규칙을 점진적으로 도출하도록 안내하기 위해 $p_g$를 세 가지 전략으로 구성합니다.
- 정상 및 이상 (Normal and Anomaly)
우선 $D_{\text{normal}}$을 기반으로 정상 규칙을 도출하고, 이후 정상 규칙과 대조하여 이상 규칙을 생성합니다. 예를 들어, "걷기"가 $D_{\text{normal}}$의 일반적인 패턴이라면 이는 정상 규칙이 되고, "걷지 않는 움직임" 은 이상 규칙에 포함됩니다. - 추상 및 구체 (Abstract and Concrete)
이는 추상적인 개념에서 더 구체적인 예시로 일반화합니다. 예를 들어, 동일한 "걷기" 가 "혼자든 다른 사람과 함께든 걷기"로 확장됩니다. 이는 이상 규칙이 "자전거 타기, 스쿠터 타기, 스케이트 보드 타기 등 걷지 않는 움직임"과 같은 구체적인 걷지 않는 움직임을 포함하도록 진화합니다. - 인간 및 환경 (Human and Environment)
해당 규칙은 시각적 인식 모듈에서 계승됩니다. 이는 프롬프트가 LLM이 환경 요소(차량 혹은 장면 요인)와 인간 활동에 각각 주의를 기울이도록 유도합니다.
3. 규칙 집계 (Rule Aggregation)
이는 LLM을 집계자(aggregator)로 사용하여 투표 메커니즘을 통해 무작위로 선택된 $n$개의 정상 참조 프레임으로부터 독립적으로 생성된 $n$개의 규칙 세트($R$)를 하나의 견고한 규칙 세트($R_{\text{robust}} = LLM(R, p_a)$)로 결합합니다. 이 모듈은 이전 단계의 오류를 완화하는 것을 목표로 합니다. 예를 들어, 시각적 인식 모듈이 "걷기"를 "스케이트 보드 타기"로 오인하여 부정확한 규칙을 생성하는 경우를 방지합니다.


해당 전략은 랜덤화 스무딩(randomize smoothing)의 가정을 기반으로 합니다. 이 가정에 따르면, 하나의 입력에서 오류가 발생할 수 있지만, 여러 무작위로 샘플링된 입력에 걸쳐 일관되게 오류가 발생할 가능성은 낮습니다. 따라서, 이 출력들을 집계함으로써 AnomalyRuler는 개별 오류에 더 잘 견디는 규칙을 생성합니다.
하이퍼파라미터 $n$은 배치 수로 간주하며, $m$은 배치당 정상 참조 프레임 수, 즉, 배치 크기로 정의합니다.
Deduction
귀납(Induction)단계에서 robust한 규칙 세트가 도출되면, 연역(Deduction) 단계에서는 이 규칙을 따라 VAD를 수행합니다. 아래 그림은 연역 단계를 보여줍니다.

이 단계에서는 비디오의 각 프레임을 정확하게 인지한 후, 규칙을 기반으로 LLM을 사용하여 정상 혹은 비정상 여부를 추론하는 것을 목표로 합니다. 연역 단계 역시 세 가지 모듈로 구성됩니다.
1. 시각적 인식(Visual Perception)


해당 모듈은 위의 귀납 단계의 모듈과 유사합니다. 다만, 귀납에서의 Visual Perception처럼 소수의 무작위 정상 참조 프레임을 사용하는 것이 아닌, 테스트 비디오의 연속적인 프레임을 모두 처리한 후 프레임 설명 $D = \{d_0, d_1, \cdots, d_t\}$ 을 출력합니다.
2. 인식 스무딩(Perception Smoothing)
Visual Perception 오류는 귀납 단계 뿐만 아니라 연역 단계에서도 발생할 수 있습니다. 이 문제를 해결하기 위해, 지수적 다수결 스무딩(Exponential Majority Smoothing)이라는 새로운 메커니즘을 제안합니다. 해당 메커니즘은 비디오의 시간적 일관성, 즉, 움직임이 연속적이고 시간이 지남에 따라 일관된 패턴을 보여야 한다는 점을 고려하여 오류를 완화합니다. 해당 메커니즘은 크게 4가지 단계로 구성됩니다.
2.1 초기 이상 매칭(Initial Anomaly Matching)
연속적인 프레임 설명 $D = \{d_0, d_1, \cdots, d_t\}$에 대해, AnomalyRuler는 귀납 단계의 이상 규칙에서 발견된 이상 키워드 $K$와 일치시킵니다.

이후 각 $d_i$에 예측 레이블 $y_i$를 할당합니다. 예를 들어, $d_i$에 "riding" 혹은 "running"과 같은 "~ing" 동사 키워드 $k \in K$ 가 존재하면 $y_i = 1$로 이상을 나타냅니다. 그렇지 않으면 $y_i = 0$은 정상을 나타냅니다. 이와 같은 초기 매칭 예측을 $Y = \{y_0, y_1, \cdots, y_t\}$으로 표기합니다.
2.2 지수적 다수결 스무딩(Exponential Majority Smoothing)
이는 지수 이동 평균(EMA)과 다수결 투표(Majority Vote)를 결합한 것입니다. 이는 지정된 윈도우 내에서 가장 일반적인 상태를 반영하도록 예측을 조정함으로써 사람이나 사물의 움직임에서 연속성을 강화하기 위해 설계되었습니다. 최종적으로 스무딩된 예측은 $\hat{Y} = \{\hat{y}_0, \hat{y}_1, ..., \hat{y}_t\}$ 으로 표기되며, 각 $\hat{y}_i$는 1 혹은 0 입니다.
- 1단계: EMA
원본 예측 $y_t$에 대해 EMA 값 $s_t$는 $s_t = \frac{\sum_{i=0}^{t}(1-\alpha)^{t-i} y_i}{\sum_{i=0}^{t}(1-\alpha)^i}$ 으로 계산됩니다.
$$s_0 = y_0$$
$$s_1 = \frac{(1-\alpha)^{1-1}y_1 + (1-\alpha)^{1-0}y_0}{(1-\alpha)^1 + (1-\alpha)^0} = \frac{y_1 + (1-\alpha)y_0}{(1-\alpha)+1}$$
$$s_2 = \frac{(1-\alpha)^{2-2}y_2 + (1-\alpha)^{2-1}y_1 + (1-\alpha)^{2-0}y_0}{(1-\alpha)^2 + (1-\alpha)^1 + (1-\alpha)^0} = \frac{y_2 + (1-\alpha)y_1 + (1-\alpha)^2y_0}{(1-\alpha)^2 + (1-\alpha)+1}$$
위와 같이 과거의 값일 수록 가중치가 줄어들며, 최신의 프레임에 집중한다는 것을 확인할 수 있습니다. - 2단계: Majority Vote
이는 각 EMA 값 $s_i$를 중심으로 패딩 크기 $p$를 가진 윈도우 내에서 예측을 부드럽게 만들기 위해 다수결 투표를 적용한 것입니다.
$$\hat{y}_i = \begin{cases} 1 & \text{if } \sum_{j=\max(1, i-p)}^{\min(i+p, t)} \mathbf{1} (s_j > \tau) > \frac{\min(i+p, t) - \max(1, i-p) + 1}{2} \\ 0 & \text{otherwise} \end{cases}$$
여기서 $\mathbf{1}$는 지시 함수(indicator function)을 나타내며, 윈도우 크기는 $\min(i + p, t) - \max(1, i-p)+1$으로 적응적으로 정의됩니다.
또한 threshold $\tau$는 모든 EMA값의 평균인 $\tau = \frac{1}{t}\sum_{i=1}^{t} s_i$로 정의하며, 해당 윈도우 내 프레임 중 임계치를 넘는 프레임의 개수가 윈도우 총 개수의 절반인 $ \frac{\min(i+p, t) - \max(1, i-p) + 1}{2} $을 넘었을 때, 해당 label 을 1로 정의합니다.
2.3 이상 점수(Anomaly Score)
$\hat{Y}$이 AnomalyRuler의 초기 탐지 결과를 나타내는 점을 고려하여, 추가로 2차 EMA를 통해 이상 점수를 평가할 수 있습니다. 이상 점수는 $A = \{a_0, a_1, \cdots, a_t\}$로 표기하며, 여기서 $a_t$는 다음과 같습니다.
$$a_t = \frac{\sum_{i=0}^{t} (1 - \tau)^{t-i} \hat{y}_i}{\sum_{i=0}^{t} (1 - \tau)^i}$$
위 절차를 본 method의 baseline인 AnomalyRuler-base라 부릅니다.
2.4 설명 수정(Description Modification)
이 단계에서 AnomalyRuler는 $Y$와 $\hat{Y}$를 비교하여 설명 $D$를 수정하여 수정된 $\hat{D}$를 출력합니다.
- 만약 $y_i = 0$인데 $\hat{y}_i = 1$인 경우, False negative을 나타내므로, 윈도우 크기 $w$ 내에서 가장 자주 등장하는 이상 키워드 $k \in K$를 추가하여 $d_i$를 "There is a person {k}." 와 같이 수정
- 반대로 $y_i = 1$인데 $\hat{y}_i = 0$ 인 경우, False positive를 나타내므로, 이상 키워드 $k$를 포함하는 설명의 일부를 제거하여 $d_i$를 수정
3. 견고한 추론(Robust Reasoning)
해당 모듈에서는 귀납 단계에서 도출된 robust rule인 $R_{\text{robust}}$를 문맥으로 삼아 LLM을 사용해 VAD추론 작업을 수행합니다. LLM에는 각 프레임의 수정된 설명 $\hat{d}_i$와 AnomalyRuler-base에서 생성된 "Anomaly" 혹은 "Normal" 이라는 dummy answer이 함께 입력됩니다. 이에 대한 결과는 $Y^* = \{LLM(\hat{d}_i, \hat{y}_i, R_{\text{robust}}, p_r) \mid \hat{d}_i \in \hat{D}, \hat{y}_i \in \hat{Y}\}$ 로 표기됩니다.

위와 같이 프롬프트 $p_r$은 LLM이 dummy answer $\hat{y}_i$가 규칙 $R_{\text{robust}}$에 따라 설명 $\hat{d}_i$와 일치하는지 재확인하도록 안내합니다.
Experiment
Datasets
- UCSD Ped2 (Ped2) : 보행자 통로 단일 장면 데이터셋(스케이트 보드와 자전거 타기 같은 이상 활동 포함)
- CUHK Avenue (Ave) : CUHK 캠퍼스 대로 단일 장면 데이터셋(달리기와 자전거 타기 같은 이상 활동 포함)
- ShanghaiTech (ShT) : 13개의 다양한 캠퍼스 장면 포함(자전거, 싸움, 보행자 구역 내 차량 등 이상 활동 포함)
- UBnormal (UB) : Cinema4D로 생성된 가상 데이터셋으로, 29개의 개방형 장면 포함
Metrics
- 탐지 성능
- AUC (Area Under the Curve)
- Accuracy, Precision, Recall
- 추론 능력
- Doubly-Right (RR, RW, WR, WW)
Implementation
- Visual Perception : CogVLM-17B인 VLM 모델 사용
- Induction step : GPT-4-1106-Preview인 LLM 모델 사용
- Deduction step : Mistral-7B-Instruct-v0.2인 LLM 모델 사용
- Hyperparameter
- Rule Aggregation
- 배치 수 $n$ = 10
- 배치당 정상 참조 프레임 수 $m$ = 1
- Perception Smoothing
- Majority vote 패딩 크기 $p$ = 5
- EMA(Exponential Moving Average) 가중치 매개변수 $\alpha$ = 0.33
- Rule Aggregation
1. LLM-based Baseline과 비교

- Ask LLM Directly: 프레임 설명을 LLM에 직접 입력
- Ask LLM with Elhafsi et al.: 사전 정의된 개념을 사용하여 LLM에 질문
- Ask Video-based LLM Directly: 비디오 기반 LLM에 클립 단위로 이상/정상 여부 질문
2. Reasoning Performance
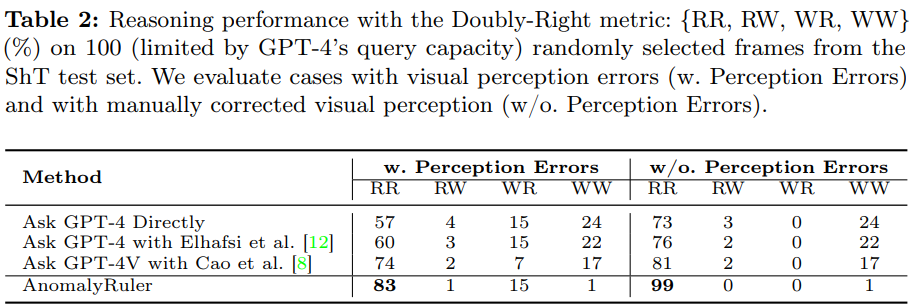
- 평가 방법
- Doubly-Right 지표: RR, RW, WR, WW
- 맞춤형 데이터셋: 추론 능력 평가를 위한 데이터 부족으로, ShanghaiTech 데이터셋에서 정상 50개, 이상 50개 프레임을 무작위로 추출해 데이터셋 구성
- 오류 분석: 시각적 인식 오류(VLM 성능 때문)가 추론에 미치는 영향을 분석하기 위해, 인식 오류가 있는 경우(w. Perception Errors)와 수동으로 인식 오류를 보정한 경우(w/o. Perception Errors)를 비교
3. State-of-the-Art Methods와 비교

- Image-Only 방법론보다 우수함
- 동등한 성능, 더 적은 비용
- 성능 향상(Robust reasoning 모듈 성능 향상 입증
4. Domain Adaptability




