
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 논문 리뷰
- 논문구현
- programmers
- 인공지능
- pytorch
- Convolution
- 코딩테스트
- 파이썬
- Semantic Segmentation
- 머신러닝
- 논문
- opencv
- 파이토치
- Python
- 프로그래머스
- 딥러닝
- Ai
- ViT
- 강화학습
- Segmentation
- 옵티마이저
- cnn
- Computer Vision
- 알고리즘
- optimizer
- Self-supervised
- transformer
- 논문리뷰
- 코드구현
- object detection
- Today
- Total
Attention please
[논문 리뷰] DDQN: Deep Reinforcement Learning with Double Q-learning (2016) 본문
[논문 리뷰] DDQN: Deep Reinforcement Learning with Double Q-learning (2016)
Seongmin.C 2025. 4. 22. 01:44이번에 리뷰할 논문은 Deep Reinforcement Learning with Double Q-learning 입니다.
https://arxiv.org/abs/1509.06461
Deep Reinforcement Learning with Double Q-learning
The popular Q-learning algorithm is known to overestimate action values under certain conditions. It was not previously known whether, in practice, such overestimations are common, whether they harm performance, and whether they can generally be prevented.
arxiv.org
Problem Definition
YDQNt≡Rt+1+γmaxaQ(st+1,a;θ−t)
위 수식은 DQN에서 사용하는 TD target 입니다. 해당 식의 특징으로는 target sample을 뽑을 때, action에 대해서 가장 큰 Q값을 추출합니다. 하지만 본 논문에서는 해당 target sample을 뽑을 때 단순히 maximum값으로 추출하게 되면 overestimate 문제가 발생한다고 주장합니다.
DQN에 대한 설명은 다음 글을 참고하시기 바랍니다.
[논문 리뷰] DQN: Playing Atari with Deep Reinforcement Learning (2013, 2015)
이번에 리뷰할 논문은 Playing Atari with Deep Reinforcement Learning 입니다.https://arxiv.org/abs/1312.5602 Playing Atari with Deep Reinforcement LearningWe present the first deep learning model to successfully learn control policies directly fr
smcho1201.tistory.com
우선 간단하게 overestimate가 되는 문제에 대해 설명하자면, 다음과 같이 모든 action에 대해 항상 같은 Q값이 나오는 optimal 한 상태를 가정합니다. 해당 state에서는 어떤 action을 취하더라도 항상 같은 Q값이 나오게 된다는 의미이고, 이를 V∗(s) 라고 notation합니다.
Q∗(s,a)=V∗(s)
이후, 기존의 DQN에서 Q를 업데이트하는 방식과 optimal Q에 대한 수식은 다음과 같이 나타나게 됩니다.
maxaQt(s,a)≥V∗(s)+√cm−1
즉, maxaQt(s,a) 는 기존의 DQN의 업데이트 방식이며, V∗(s) 는 실제로 다가가야 하는 optimal 한 최적의 가치 함수를 의미하죠.
maxaQt(s,a)−V∗(s)≥√cm−1
위와 같이 수식을 정리하게 되었을 때, Q값을 max한 값으로 업데이트를 하게 되면 항상 optimal 한 값과의 차이가 발생, 즉, 항상 error가 발생한다는 것을 의미합니다. 본 논문에서는 이러한 점들을 기존 DQN의 문제로 정의하였고, 위와 같이 error가 발생함을 수학적으로 증명하였습니다.
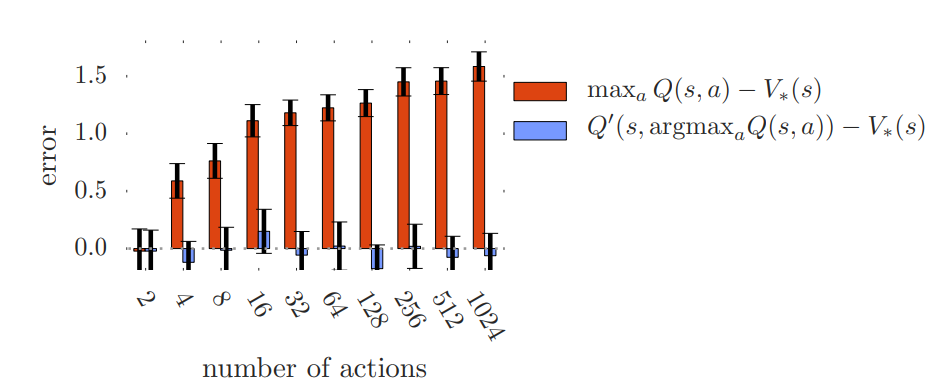
실제로 빨간색 bar는 기존 DQN의 방식으로 업데이트를 하였을 때의 optimal value와의 차이이고, 파란색 bar는 본 논문에서 제안한 방식으로 target sample을 추출하였을 때 optimal value와의 차이를 의미합니다. 위 그림과 같이 본 논문에서 제안한 방식으로 sampling을 하였을 때, error가 현저하게 떨어지는 것을 확인할 수 있습니다.
위 그래프를 보시면, action 수가 많아질수록 error 수치가 점점 커지는 것을 확인할 수 있습니다. 그 이유는 만약 기존 DQN의 방식대로 모든 action에 대해서 가장 큰 Q값을 가지는 target sample을 추출하게 되면, 다른 action들이 다채롭게 존재하지만 이를 무시하고, 가장 큰 Q값을 가지는 action에 대해서만 과도하게 평가, 즉, overestimate 될 수 있습니다. 이러한 이유로 action 수가 많아질수록 overestimate 의 문제가 더 커지게 되고 위와 같이 error 수치도 증가하게 되는 것이죠.
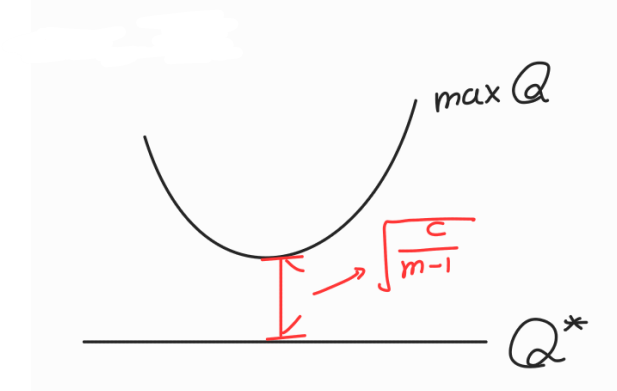
즉, 위 그림과 같이 maxQ 와 optimal Q∗ 사이에는 √cm−1만큼의 차이가 발생한다는 것을 본 논문에서 밝히게 됩니다.
Target Value
우선 본 논문에서 제안하는 target 수식은 다음과 같습니다.
Rt+γQw−(st+1,argmaxat+1Qw(st+1,at+1))
- w : main network의 파라미터
- w− : target network의 파라미터
원래 DQN의 target 수식은 Rt+γmaxat+1Qw−(st+1,at+1) 입니다. target을 구할 때 target network를 따로 분리하여 샘플링을 하였지만 여전히 target network로부터의 Q값을 기준으로 maximum값을 사용했기 때문에 overestimate가 존재했죠. 다시 말해, 기존 DQN은 max연산을 Q값에 직접 적용하였으며, 이는 Q가 과하게 큰 액션이 반복적으로 선택하도록 하였습니다.
하지만 DDQN에서는 선택은 main network, 평가는 target network 로 하여 분리된 신경망으로 명확하게 역할을 분담시켰습니다. 이를 통해 더 안정적인 업데이트를 이끌어냈다고 볼 수 있습니다.
Proof Theorem
증명해야 하는 theorem 수식은 다음과 같습니다.
Theorem:maxaQt(s,a)≥V∗(s)+√cm−1
우선 위 수식을 증명하기 위해 다음 3가지의 가정이 필요합니다.
1. 모든 액션에 대해 Q∗ 값이 동일
Given st,Q∗(st,at)=V∗(st)∀at
이는 말 그대로 어떠 상태 st에서 모든 action에 대해 Q값이 전부 같다는 의미입니다. 즉, 에이전트가 어떤 행동을 하든 그 상태에서는 기대되는 보상이 똑같습니다.
2. 평균 오차는 0
∑aεa=0,where εa≜Q(st,at)−V∗(st)
여기서 εa는 추정된 Q값과 실제 최적값의 차이를 의미합니다. 이 차이값들의 평균이 0이라는 의미는 Q함수가 편향은 없고 단순히 샘플링 노이즈만 있다는 가정으로 볼 수 있습니다.
3. 분산은 1m∑aε2a=Cwhere C>0
1m∑aε2a=Cwhere C>0, m=num of actions
Action 수 m개의 오차 제곱 평균이 일정한 값 C라는 뜻입니다. 즉, 각 action에 대한 Q값의 오차가 고르게 퍼져 있고, 그 강도는 C로 일정하다는 것을 의미합니다.
자 이제 위에서 주어진 3가지 조건을 두고 다음 수식을 증명해야 합니다.
maxaεa≥√Cm−1
위 수식에서 ε은 Q(st,at)−V∗(st) 입니다. 하지만 V∗(st) 에는 action이 파라미터로 없기 때문에 결론적으로는 다음과 같은 수식임을 증명하는 것이 됩니다.
maxaQ(s,a)−V∗(s)≥√Cm−1
이를 증명하기 위해 다음과 같이 notation을 하겠습니다.
- n : 양수 action의 개수 (εa > 0)
- m−n : 음수 action의 개수 (εa < 0)
우선 2번 조건인 ∑aεa=0을 만족시키기 위해서는 n 혹은 m−n이 0인 것은 불가능합니다. 즉, 모두 음수이거나 양수인 것은 불가능하죠.
또한 3번 조건인 1m∑aε2a=C을 만족하기 위해서는 εa가 모두 0인 것도 불가능합니다. 그리고 반드시 m−n≥1 이어야 합니다.
또한 다음 수식도 만족합니다.
∑aε+a≤nmaxaεa
- ε+a : 양수인 εa
- ε−a : 음수인 εa
이후 다음과 같이 가정을 하나 해봅니다.
nmaxaεa<n√cm−1
maxaεa<√cm−1
위 가정을 증명해볼건데 결론부터 말씀드리면 위 가정은 만족하지 않습니다. 그러면서 자연스럽게 maxaεa≥√cm−1 가 만족하면서 theorem을 증명하게 됩니다.
다음으로 위 가정을 만족한다면, ∑aε+a≤nmaxaεa<n√cm−1 와 같이 나타낼 수 있으며, ∑aεa=0 을 만족해야하므로 다음과 같습니다.
∑a|ε−a|<n√cm−1
또한 위 수식을 만족한다면, 다음과 같이 나타낼 수 있습니다.
maxa|ε−a|<n√cm−1
다음 수식을 보면,
∑a|ε−a|2≤∑a|ε−a|⋅maxa|ε−a|
위 수식이 만족하는 이유는 간단합니다. 예를 들어서 ε−a 가 -1, -2, -3 이 있다고 한다면, 각 수에 대해 절대값을 취하고, 각각 최대값과 곱하는 것이 당연히 각 값의 제곱보다 클 수 밖에 없습니다.
12+22+32≤(1⋅3)+(2⋅3)+(3⋅3)
앞서 정의하였던 두 가정 ( ∑a|ε−a|<n√cm−1 ) 과 ( maxa|ε−a|<n√cm−1 ) 이 만족한다면, 다음과 같이 수식을 전개해나갈 수 있습니다.
∑a|ϵ−a|2≤∑a|ϵ−a|⋅maxa|ϵ−a|
∑a|ϵ−a|2<n√cm−1⋅n√cm−1=n2cm−1
또한 m−n≥1 이므로 m−1≥n 으로 나타낼 수 있기 때문에 다음과 같이 전개가 가능합니다.
n2cm−1≤(m−1)⋅c
다음으로 ∑aε+a≤nmaxaεa<n√cm−1 이 수식이 만족한다고 가정하였었는데, 해당 수식에 각 항에 제곱을 해주면 다음과 같이 나타낼 수 있습니다.
∑a(ε+a)2<n⋅cm−1
또한 앞서 전개하였던 ∑a|ϵ−a|2≤∑a|ϵ−a|⋅maxa|ϵ−a| 수식에 (ε+a)2의 합을 더해주게 되면 다음과 같이 전개가 가능합니다.
∑aε2a≤∑a|ε−a|⋅maxa|ε−a|⏟음수 ε 제곱의 합+∑a(ε+a)2⏟양수 ε 제곱의 합
∑aε2a<n√cm−1⋅n√cm−1+ncm−1
∑aε2a<n2cm−1+ncm−1
여기서 m−1≥n 이므로 다음과 같이 전개됩니다.
∑aε2a<(m−1)⋅c+(m−1)cm−1
∑aε2a<mc
근데, 앞서 정의하였던 3번 조건인 (1m∑aε2a=C→∑aε2a=mC) 을 만족하지 못합니다. 고로 모순이 생겼다는 것을 의미합니다.
해당 모순은 maxaεa<√cm−1 에서 시작하였기 때문에, 결론적으로는 다음 수식을 만족하게 되는 것입니다.
maxaεa≥√cm−1
Result
위 증명하는 과정을 통해 maxaεa≥√cm−1 이 만족함을 알 수 있었습니다. 즉, 기존의 DQN 방식의 업데이트로는 항상 error가 발생한다는 것을 의미합니다.
본 논문에서는 TD target을 샘플링하는 새로운 방식을 소개하며, 이는 maxaεa≥√cm−1 를 만족하지 않아 더 최적화하는 데 알맞다고 합니다.
Rt+γQw−(st+1,argmaxat+1Qw(st+1,at+1))
위 식에서는 target을 maximum으로 잡지 않기 때문이죠.
'논문 리뷰 > Reinforcement Learning' 카테고리의 다른 글
| [논문 리뷰] Dueling DQN: Dueling Network Architectures for Deep Reinforcement Learning (2016) (1) | 2025.04.22 |
|---|---|
| [논문 리뷰] DQN: Playing Atari with Deep Reinforcement Learning (2013, 2015) (1) | 2025.04.20 |

