
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- cnn
- Paper Review
- 파이토치
- Ai
- Segmentation
- 논문리뷰
- object detection
- 옵티마이저
- 논문구현
- 논문 리뷰
- Semantic Segmentation
- 머신러닝
- Convolution
- optimizer
- pytorch
- Self-supervised
- 딥러닝
- ViT
- 논문
- Python
- 프로그래머스
- transformer
- 코드구현
- 알고리즘
- 코딩테스트
- 파이썬
- 인공지능
- opencv
- Computer Vision
- programmers
- Today
- Total
Attention please
[논문 리뷰] Xception(2017), 파이토치 구현 본문
이번에 리뷰할 논문은 "Xception: Deep Learning with Depthwise Separable Convolutions " 이다. 구글에서 2014년에 GoogLeNet이라는 모델을 제시하였고 이때 Inception module이라는 개념이 등장하였다. Xception은 이 Inception module을 기반으로 만들어진 모델이며, "Extreme Inception" 의 줄임말이다.
Inception Module
본 논문은 Inception v3 로부터 Xception 모델까지 가는 과정을 담고 있다. Inception v1 (GoogLeNet)과는 약간의 차이가 있는데 구조는 다음과 같다.
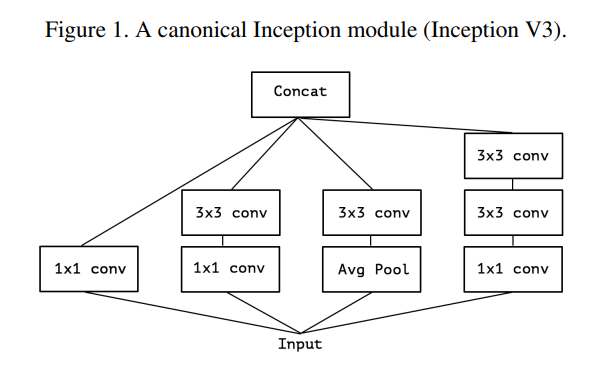
Inception v1 과 다른점은 5x5 Convolution 층을 3x3 Convolution 층 2개로 바꾸었다는 점이다. 5x5 하나를 사용하는 것보다 3x3 를 두번 사용하는 것이 더 효과적이기 때문이다.
기존 Convolution layer은 cross-channel correlation과 spatial correlation을 동시에 mapping하기 때문에 Height, Weight, Channel 모두를 학습한다. 하지만 Inception module은 기존의 Convolution과는 다르게 3~4개의 1x1 Convolution으로 channel correlation을 먼저 mapping한 후 3x3, 5x5 Convolution을 수행하여 spatial correlation을 mapping한다. 즉, Inception은 channel과 spacial 의 correlation을 분리하는데에 목적이 있다.
- cross-channel correlation : 입력 채널들 간의 관계 학습
- 1x1 convolution(pointwise convolution)을 통해 학습 가능
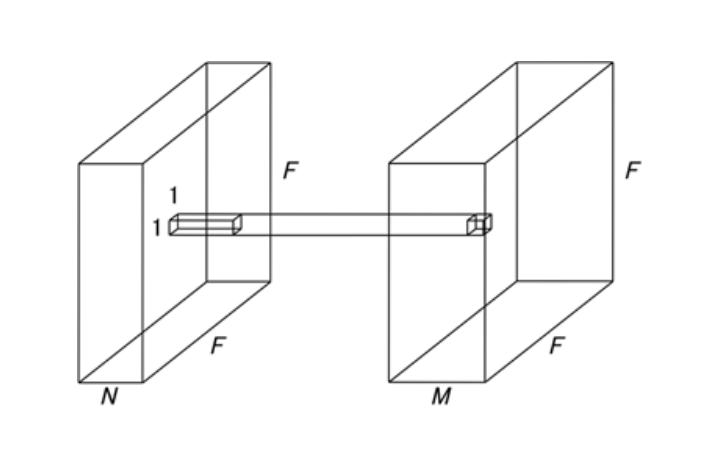
- spatial correlation : 필터와 특정 채널 사이의 관계 학습 (공간적인 특성 학습)
본 논문에서는 filter하나가 해야했던 것을 3x3, 5x5 Conv가 spatial correlation을 분석해주고, 1x1 Conv가 cross-channel correlation을 분석함으로써 두개의 역할로 분산을 잘 해주었기 때문에 Inception의 성능이 높았다고 설명한다. 이를 통해 cross-channel correlation과 spatial correlation의 mapping을 완전히 분리하는 것을 목적으로 한다.
먼저 Inception module을 단순화 시키는 것으로 시작한다.
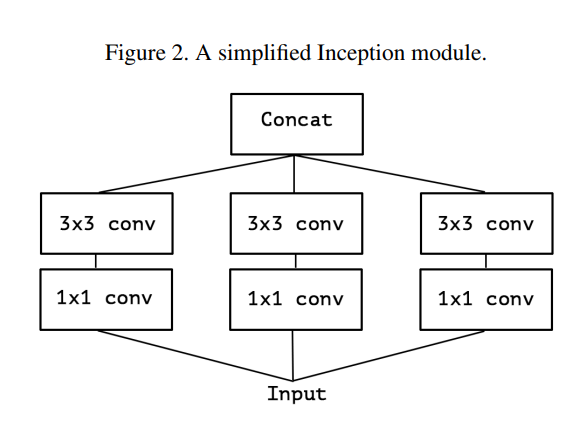
그다음 여러개의 1x1 Convolution을 대규모 1x1 Convolution으로 재구성한 후 output channel이 겹치지 않도록 spatial convolution(3x3) 이 오는 형태로 재구성하였다.
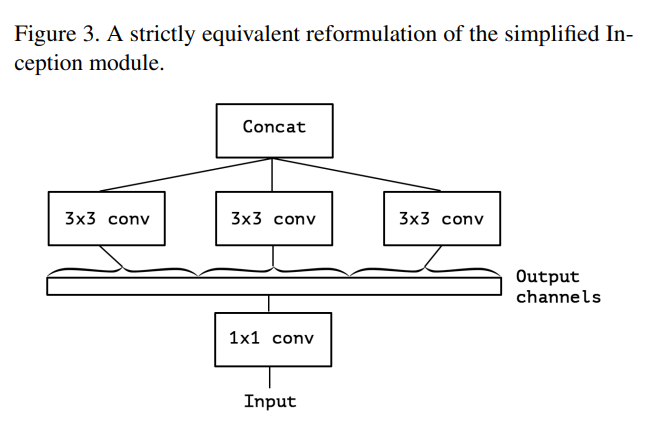
이를 통해 cross-channel correlation 과 spatial correlation 을 완전하게 분리하여 학습할 수 있다고 가설을 세웠다.
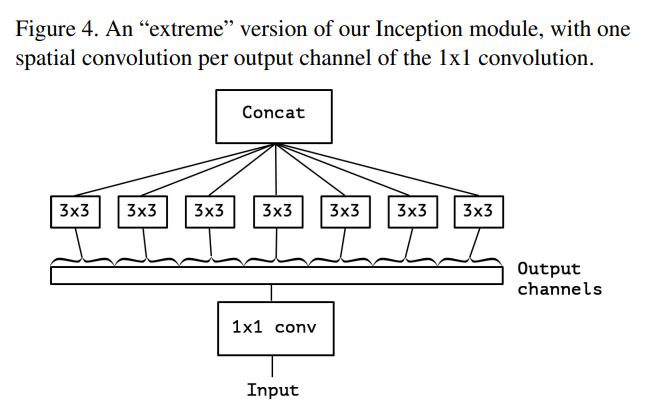
Depthwise Separable Convolution
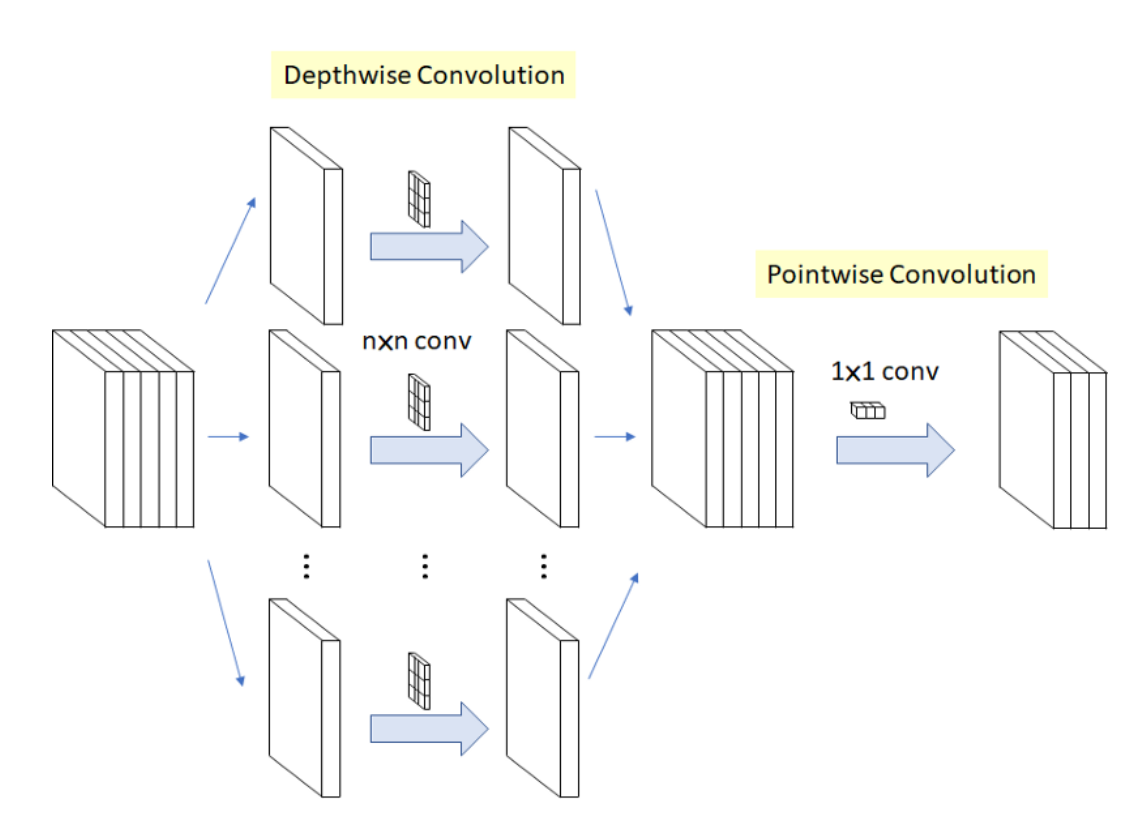
Xception은 1x1 conv를 통해 cross-channel correlation을 학습한 후 각 output channel에 대해 spatial correlation을 학습한다. 이는 Depthwise Separable Convolution 과 비슷하지만 약간의 차이가 존재한다.
Depthwise Separable Convolution은 3x3 conv를 먼저 수행한 후 1x1 conv(pointwise convolution)를 적용하지만 Xception은 순서가 반대이다.
- Xception : 1x1 -> 3x3
- Depthwise : 3x3 -> 1x1
또한 Xception은 1x1 conv 와 3x3 conv 사이에 ReLU와 같은 activation function이 존재하지만 Depthwise Separable Convolution의 경우 따로 존재하지 않는다.
- Xception : 1x1 -> ReLU -> 3x3
- Depthwise : 3x3 -> 1x1
Depthwise Convolution은 각 channel 마다 spatial feature를 추출하기 위해 고안되었다. 일반적인 Convolution은 1개의 kernel이 전체 channel에 대해 convolution을 하는 반면, depwise convolution은 1개의 kernel이 1개의 channel에 대해서만 convolution을 한다.
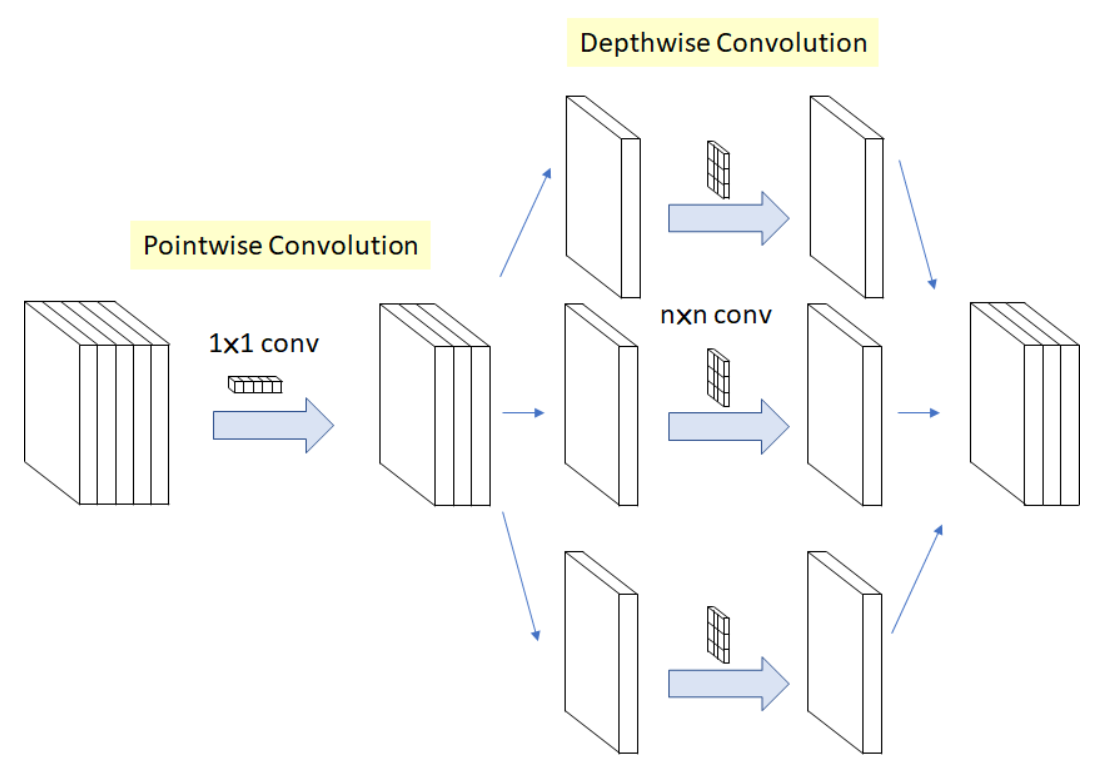
반대로 Xception의 경우 1x1 conv(pointwise convolution)을 통해 cross-channel correlation을 먼저 학습한 후 output channel에 대해 spatial convolution을 수행한다. 하지만 본 논문에서는 (depthwise -> pointwise) 의 순서대로 수행해도 크게 상관이 없다고 한다.
Architecture
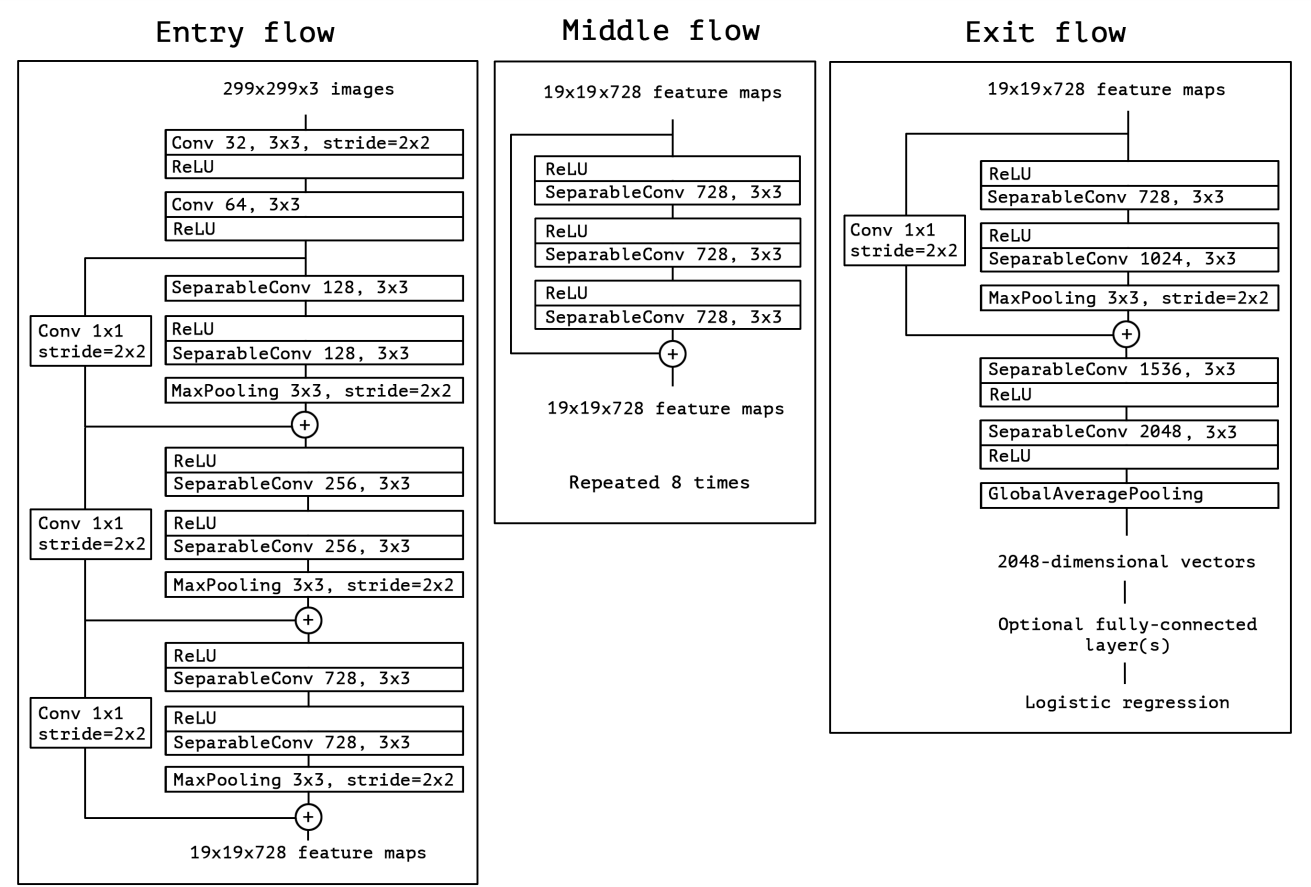
Xception의 구조는 Depthwise convolution과 max-pooling층으로 구성된 block으로 구성되어 있으며, 이들을 residual connection으로 연결한 모듈을 반복적으로 Stacking을 하는 구조이다.
코드 구현
우선 Depthwise Separable Convolution을 class로 구현하자.
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding =0, dilation=1, bias=False):
#nn.Module 을 상속받게 만들기
super(SeparableConv2d, self).__init__()
self.conv1 = nn.Conv2d(in_channels = in_channels,
out_channels = in_channels, # depthwise convolution 에서는
stride = stride, # in channel과 out channel의 수가 같다
kernel_size = kernel_size,
padding = padding,
dilation = 1,
bias = False,
groups = in_channels # Depthwise conv 이기 때문에 channel 별로 group
) # 즉, in_channel 수와 같게 적용
self.pointwise = nn.Conv2d(in_channels=in_channels,
out_channels = out_channels,
kernel_size = 1, stride = 1, padding=0, dilation=1, groups =1, bias=bias)
def forward(self, x):
x = self.conv1(x)
x = self.pointwise(x)
return x
위에서 구현한 Separable convolution을 통해 모델에서 계속 사용되는 Block을 만들자.
- reps : 블록 안 separable convolution 의 개수 ( Middle Flow : 3 , 나머지 : 2)
- start_with_relu : convolution 앞에 ReLU가 있는가 ( 첫 블럭 : False , 나머지 : True)
- grow_first : 필터의 개수가 해당 블럭의 첫 conv에서 증가하는가 마지막 conv에서 증가하는가 ( 마지막 블럭 : False, 나머지 : True)
class Block(nn.Module):
def __init__(self, in_filters, out_filters, reps,
strides=1, start_with_relu=True, grow_first=True):
super(Block, self).__init__()
# skip : Residual
# 인풋과 아웃풋의 필터의 개수가 다르다면 개수를 맞춰주기 위해
# 필터의 개수가 맞게 convolution 을 진행해야함 -> kernel의 크기는 1로
if out_filters != in_filters or strides!=1:
self.skip = nn.Conv2d(in_filters,out_filters,1,stride=strides, bias=False)
self.skipbn = nn.BatchNorm2d(out_filters)
else:
self.skip=None #인풋과 아웃풋 필터의 개수가 같다면 조정할 필요 없음
self.relu = nn.ReLU(inplace=True)
rep=[] #모든 computation 을 rep 에 저장하기
filters = in_filters
if grow_first: #필터의 개수를 늘리고 시작하는 블록이라면
rep.append(self.relu)
rep.append(SeparableConv2d(in_filters,out_filters,3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
filters = out_filters
for i in range(reps-1): # 블록에 Depthwise convolution이 몇번 있느냐?
rep.append(self.relu)
rep.append(SeparableConv2d(filters,filters,3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(filters))
if not grow_first: # 필터의 개수를 마지막에 늘리는 블록이라면
rep.append(self.relu)
rep.append(SeparableConv2d(in_filters,out_filters,3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
if not start_with_relu: #ReLU 로 시작하지 않으면 앞에 ReLU 하나 떼어내가
rep = rep[1:]
else:
rep[0] = nn.ReLU(inplace=False)
if strides != 1: # stride 가 1이 아니면 MaxPooling을 적용한다
rep.append(nn.MaxPool2d(3,strides,1))
self.rep = nn.Sequential(*rep)
def forward(self,inp):
x = self.rep(inp)
#Residual Network의 필터개수 맞춰주기
if self.skip is not None:
skip = self.skip(inp)
skip = self.skipbn(skip)
else:
skip = inp
#Residual 연결
x+=skip
return x
이제 마지막으로 Xception class를 생성하자.
class Xception(nn.Module):
def __init__(self, num_classes=1000):
super(Xception, self).__init__()
self.num_classes = num_classes
#Entry Flow 에서 쓸 함수 정의하기
#모든 convolution 다음에는 batch norm이 온다
self.conv1 = nn.Conv2d(3, 32, 3,2, 0, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32,64,3,bias=False)
self.bn2 = nn.BatchNorm2d(64)
#ReLU 적용
self.block1=Block(64,128,2,2,start_with_relu=False,grow_first=True)
self.block2=Block(128,256,2,2,start_with_relu=True,grow_first=True)
self.block3=Block(256,728,2,2,start_with_relu=True,grow_first=True)
#Entry Flow 의 아웃풋은 19x 19 x 728 feature maps
# Middle Flow 에서 쓸 함수: 같은거 8번 반복
self.block4=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block5=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block6=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block7=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block8=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block9=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block10=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block11=Block(728,728,3,1,start_with_relu=True,grow_first=True)
#Middle Flow 의 아웃풋은 19 x 19 x 728 feature maps-> 크기는 같음
#Exit Flow 에서 쓸 함수
self.block12=Block(728,1024,2,2,start_with_relu=True,grow_first=False)
self.conv3 = SeparableConv2d(1024,1536,3,1,1)
self.bn3 = nn.BatchNorm2d(1536)
#ReLU 적용
self.conv4 = SeparableConv2d(1536,2048,3,1,1)
self.bn4 = nn.BatchNorm2d(2048)
#ReLU 적용
#Optional FC Layer
self.fc = nn.Linear(2048, num_classes)
#------- init weights --------
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#-----------------------------
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = self.block7(x)
x = self.block8(x)
x = self.block9(x)
x = self.block10(x)
x = self.block11(x)
x = self.block12(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.relu(x)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] MobileNet V1(2017), 파이토치 구현 (0) | 2022.12.29 |
|---|---|
| [논문 리뷰] DenseNet(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] ResNet(2016), 파이토치 구현 (0) | 2022.12.28 |
| [논문 리뷰] Inception V1 - GoogLeNet(2014), 파이토치 구현 (0) | 2022.12.28 |
| [논문 리뷰] VGGNet(2015), 파이토치 구현 (0) | 2022.10.01 |



