
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Paper Review
- 논문리뷰
- 프로그래머스
- 논문
- opencv
- transformer
- 옵티마이저
- Segmentation
- Computer Vision
- cnn
- 딥러닝
- pytorch
- object detection
- Python
- Ai
- Convolution
- 머신러닝
- ViT
- 코딩테스트
- 논문구현
- 인공지능
- 알고리즘
- 논문 리뷰
- optimizer
- 파이토치
- 코드구현
- Semantic Segmentation
- Self-supervised
- programmers
- 파이썬
- Today
- Total
Attention please
[논문 리뷰] ResNet(2016), 파이토치 구현 본문
이번에 리뷰할 논문은 "Deep Residual Learning for Image Recognition" 이다. 이 논문에서 소개하는 모델은 ResNet이라 불리며 이미지넷 이미지 인식 대회(ILSVRC)에서 1등을 차지하였다. 모델의 깊이가 깊어지게되면 모델의 성능 역시 상승하게 된다. 하지만 vanishing gradient와 같이 모델의 깊이가 깊어지게 되면 생기는 문제들 역시 존재하기에 아무런 대책없이 무작정 모델의 layer을 높이는 것은 정답이 아니다. 하지만 ResNet은 무려 152개의 layer을 쌓았으며 VGGNet보다 복잡도가 낮은 엄청난 성과를 보여주었다.
Residual Learning
앞서 말했던 것처럼 CNN은 모델의 깊이가 깊어질수록 학습할 수 있는 feature가 증가하게 되면서 모델의 성능은 좋아진다. 하지만 지금까지의 일반적인 CNN은 단순히 모델의 깊이를 늘리게되면 어느순간부터는 오히려 성능이 떨어지는 문제가 있었는데 이 논문에서는 잔여학습(residual learning) 을 사용하여 이를 해결하였다.
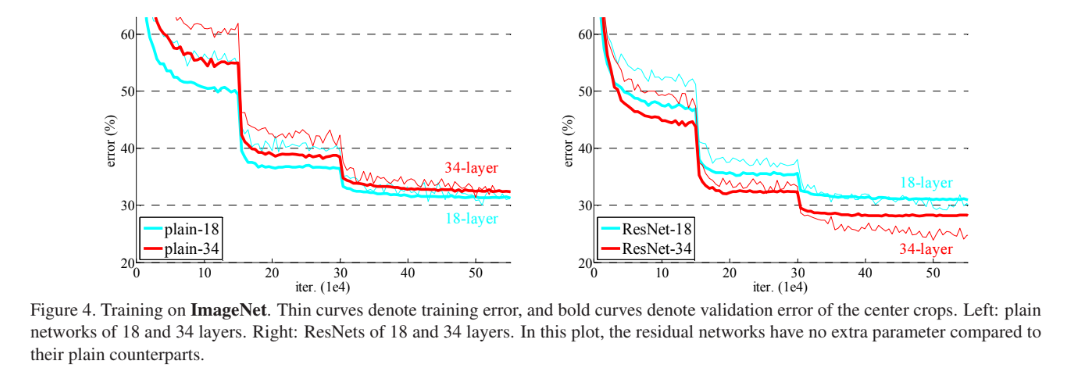
위 그림의 왼쪽은 일반적인 CNN 중 하나인 VGG-19를 학습하였을 때의 결과이며, 오른쪽은 잔여 학습을 적용한 VGG-19 학습하였을 때의 결과인데 보이는 것처럼 왼쪽 그림은 오히려 깊이가 낮은 모델의 성능이 우세했던 것에 비해 오른쪽 그림은 더 깊은 모델의 성능이 우세한 것을 확인할 수 있다.
즉, resnet을 사용했을 때 모델의 깊이가 깊어지면서 발생하는 문제를 해결할 수 있다고 보여진다.
Residual Block
본 논문에서는 단순히 네트워크의 layer가 깊어지기만 하면 모델의 성능은 오히려 떨어지게 되고 의도했던 대로 최적화(optimization)을 시키는 것이 어려워진다고 주장했다. 즉 VGGNet과 같이 단순히 Convolution 층을 깊게 쌓는 것은 이 문제를 해결할 수 있는 방안이 아니기 때문에 잔여 블록(residual block) 을 사용하여 해결할 수 있다고 주장하였다.
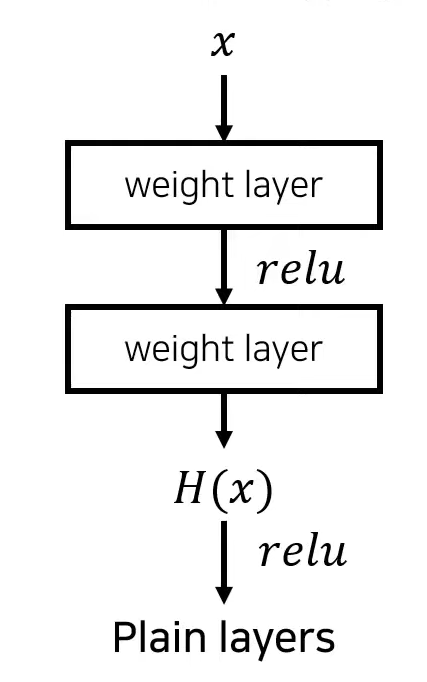
지금까지의 일반적인 층의 구조는 다음과 같았다. x(입력값)이 Convolution layer을 통과하면서 다양한 feature들을 추출한 후 ReLu와 같은 activation fuction을 거지게 되면서 네트워크가 non linear한 동작을 수행할 수 있도록 만들어준다. 이어서 다시 convolution layer을 반복하여 통과하는 방식을 사용해왔다.
하지만 입력데이터 x를 넣었을 때 이상적으로 동작하는 mapping을 H(x)라고 가정하였을 때 이상적으로 동작하는 함수 H를 학습하는 것은 난이도가 높다. 이러한 이유로 학습이 어려운 H(x) 대신 보다 학습이 잘 되는 형태인 F(x)를 이용하자는 것이 본 논문의 핵심이라 할 수 있다.

residual block의 구조는 앞서 보여주었던 Plain layers와 흡사하다. 그저 input 데이터인 x를 여러개의 weight layer를 거친 결과값에 더해주는 것만 추가되었다. 단순히 이 더해주는 작업만 했을 뿐인데 더 빠르고 정확하게 학습할 수 있었다.
residual block 에 대해 정확히 설명하자면 x가 weight layer를 거쳐 나온 결과값을 F(x)라고 한다. 이때 이 F(x)와 input값인 x를 더한 F(x) + x 가 Plain layers에서 우리가 의도했던 mapping인 H(x) 와 같은 형태가 되도록 유도를 해주는 것이다.
이렇게 input값인 x를 그대로 가져와 더하는 것은 앞서 학습된 정보를 그대로 가져오고 또 해당 Convolution에서 학습된 정보인 F(x) 즉 잔여한 정보인 F(x)를 추가적으로 학습할 수 있는 형태를 만들어주게 되면서 F(x) + x 전체를 학습하는 것보다 잔여 정보인 F(x)만을 학습하는 것이기에 훨씬 난이도가 쉬워진다는 것이다.
다시 말해 Plain layers의 경우 weight layer들이 모두 분리되어있기 때문에 H(x)를 학습하기 위해 각각의 가중치 값들을 개별적으로 학습시켜야하기에 층이 깊어지면 깊어질 수록 학습 난이도가 높아지는 반면 Residual Block의 경우 기존의 학습했던 정보 x는 그대로 가져오고 추가적으로 F(x)에 대해서만 학습을 진행하기 때문에 H(x)를 학습하는 것보다 F(x)를 학습하는 것이 더 쉽다.

다음은 F함수의 수식이다. 입력값 x에 첫 번째 가중치인 W1을 곱하고 activation function인 ReLu를 적용한 후 두 번째 가중치 W2를 곱하는 것으로 정의되는 것을 볼 수 있다.
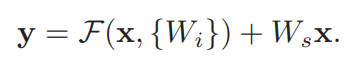
다음은 Residual Block의 수식이다. 본 논문에서는 잔여에 해당하는 weight layer의 개수가 꼭 2개가 아니라 그 이상이여도 된다 하였기에 W(i)라 표현하였고 F함수에 기존 데이터인 X를 더해주는 형태로 정의 된다. 하지만 F함수를 적용하여 나온 결과값과 기존 데이터인 X의 dimension이 같을 경우 그냥 더해주기만 하면 되지만 다를 경우에도 linear하게 projection을 적용하여 mapping을 할 수 있다고 한다.
Architecture

첫 번째 architecture는 VGG-19 모델이다. 두 번째는 VGG-19를 기반으로 설계한 34 layer의 Plain network이며, 세 번째는 VGG-19를 기반으로 설계한 34 layer의 residual network이다. 위 figure와 같이 VGG 네트워크와 전체적인 구조는 흡사하며 residual learning 기법만 추가된 형태임을 확인할 수 있다.
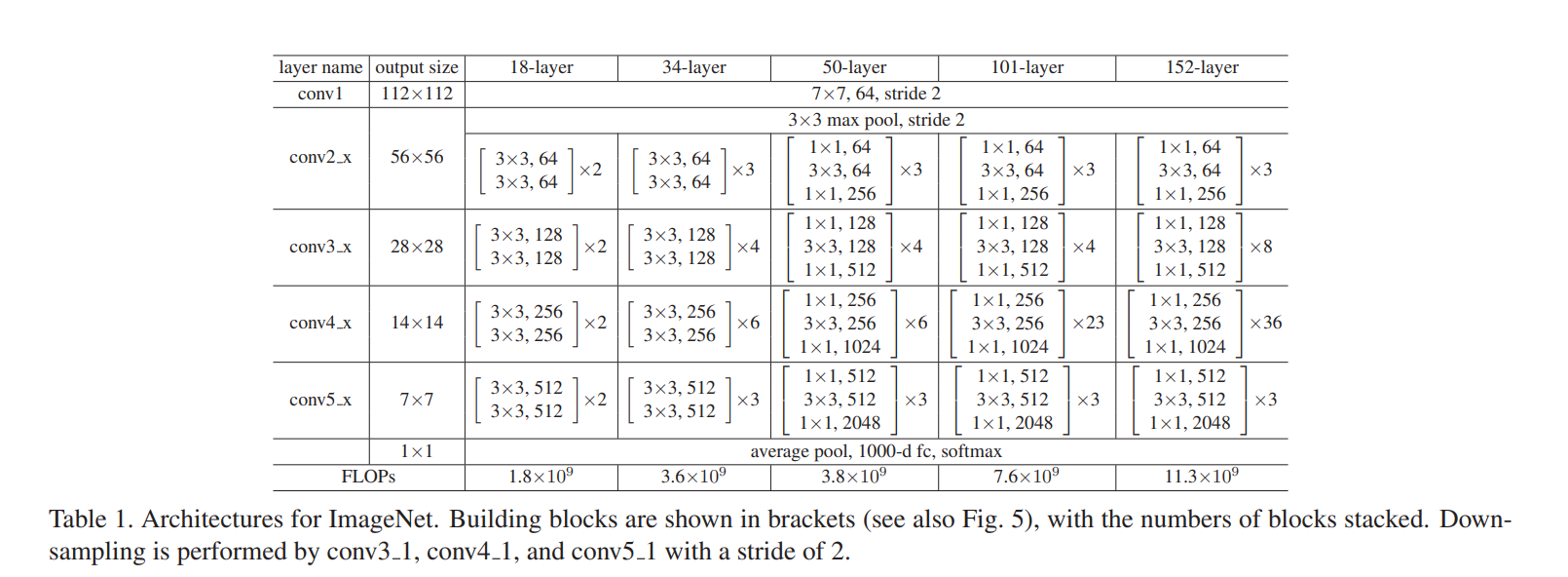
다음 figure에서 보시다시피 처음에는 18 layer으로 시작해서 점점 깊에 쌓아 152 layer까지 층을 쌓았다. 하지만 layer의 깊어질수록 dimension의 크기는 커지게 되고 이는 parameter 수가 증가해 연산량이 증가한다는 것이다.
Deeper Bottleneck
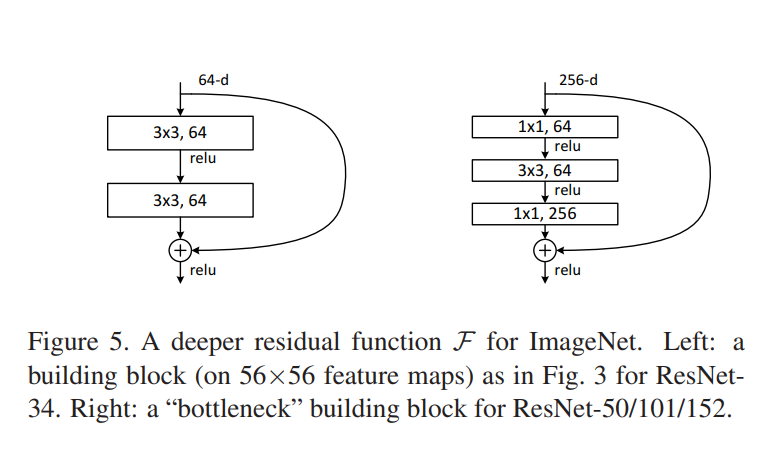
위에서 말했던 것처럼 모델의 층을 깊게 만들면 연산량이 많아지는 것이 문제이다. 이를 해결하기 위해 본 논문에서 제안한 것이 Bottleneck이다. 위 figure에서 왼쪽이 기존의 residual block의 형태였다면 각 residual fuction마다 1x1, 3x3, 1x1 Convolution으로 이루어진 3개의 layer를 사용하는 것으로 바꾼 것이 오른쪽 그림이다. 그렇다면 왜 1x1 Conv를 추가하여 새로운 형태의 layer으로 바꾼 것일까?
1x1 Convolution은 차원을 축소할 수도 확대할 수도 있다. 이를 통해 3x3 Convolution의 입력값과 출력값의 dimension을 작게 만들 수 있다. 또한 layer가 1개 더 추가되었음에도 불구하고 시간복잡도는 비슷하다.
코드 구현
지금까지 알아본 ResNet을 파이토치로 구현해 보겠다.
ResNet에는 Residual Block이 빈번하게 사용되기 때문에 따로 class를 정의한 후 ResNet을 구현할 필요가 있어 보인다.
class BasicBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) # (x - kernel_size + 2*padding)) / stride + 1 = x : size를 같게 해주기 위해 padding을 1로 한다.
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1: # stride가 1이 아니라는 것은 input과 output 채널의 개수가 달라짐을 의미한다.
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False), # 고로 identity x 의 채널의 개수를 output과 맞춰주기 위해 convolution 층을 이용한다.
nn.BatchNorm2d(planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # F(x) + x
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False) # kernel_size : 7 x 7 -> 3 x 3 (CIFAR-10 이미지 크기가 작기 때문)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # 사용하는 데이터의 종류가 변해도 보통 채널의 깊이는 바꾸지 않고 그대로 둔다.
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) # 처음 stride를 제외하고 나머지 층들의 stride는 1로 통일한다.
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes # planes 갱신
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
# out = F.max_pool2d(out, kernel_size=3, stride=2) # F.max_pool2d 추가 (논문에서 MaxPooling 사용)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4) # GoogLeNet에서 사용했던 Global Average Pooling(GAP) 를 사용하여 연산을 줄인다.
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
net = ResNet18().to(device)
print(net)
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] DenseNet(2017), 파이토치 구현 (0) | 2022.12.29 |
|---|---|
| [논문 리뷰] Xception(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] Inception V1 - GoogLeNet(2014), 파이토치 구현 (0) | 2022.12.28 |
| [논문 리뷰] VGGNet(2015), 파이토치 구현 (0) | 2022.10.01 |
| [논문 리뷰] AlexNet(2012), 파이토치 구현 (0) | 2022.09.29 |



