
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 인공지능
- Self-supervised
- Python
- optimizer
- ViT
- Ai
- Semantic Segmentation
- opencv
- Paper Review
- 파이토치
- Computer Vision
- 논문
- programmers
- 논문구현
- 논문리뷰
- 머신러닝
- 옵티마이저
- 알고리즘
- 딥러닝
- Convolution
- 파이썬
- object detection
- 논문 리뷰
- transformer
- Segmentation
- 프로그래머스
- 코딩테스트
- pytorch
- cnn
- 코드구현
- Today
- Total
Attention please
[논문 리뷰] MobileNet V1(2017), 파이토치 구현 본문
이번에 리뷰할 논문은 "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications" 이다. MobileNet은 말 그대로 모바일 기기에서 동작할 수 있도록 성능 저하를 최소화하면서 모델을 크게 경량화하는 것을 목표로 하였다.

2017년도 당시 사용되는 CNN 모델들은 분명 성능은 좋았지만 모델의 size가 너무 커진다는 단점이 있었다. 물론 데이터 센터와 같이 고성능의 환경에서는 무리없이 돌아가겠지만 문제는 모바일과 같이 고성능이 아닌 환경에서는 돌아가지도 않는다는 것이다. 즉 본 논문의 핵심은 파라미터를 줄이는데에 있었고 이를 위해 사용한 기법이 크게 3가지가 있다.
- Depthwise Separable Convolution
- Width multiplier
- Resolution multiplier
이 3가지 중에서도 Depthwise Separable Convolution 이 본 논문의 핵심이라 할 수 있다.
Depthwise Separable Convolution
Depthwise Separable Convolution은 여러 합성곱 기법들 중 하나이며, depthwise convolution과 pointwise convolution을 결합한 형태이다. 이 기법은 convolution 연산량을 크게 줄이기 때문에 모델의 크기 역시 줄어들게 된다.
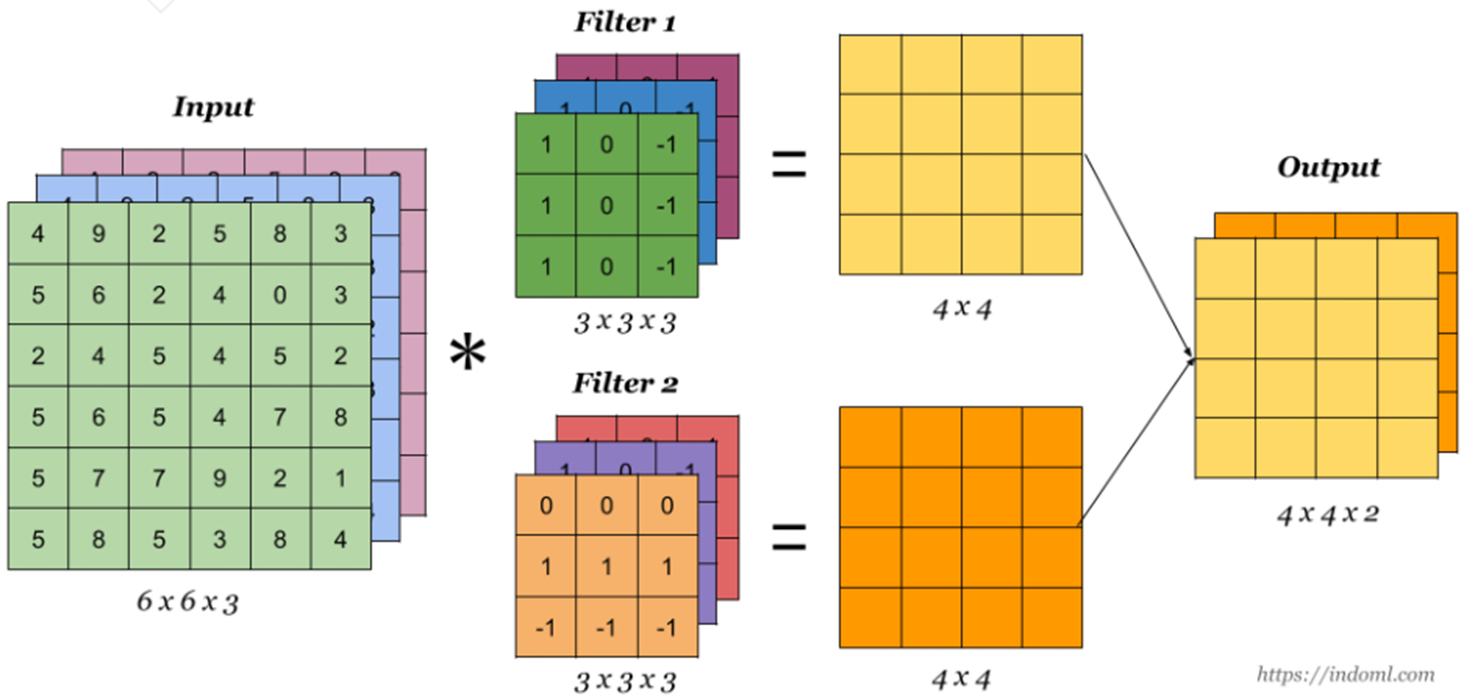
일반적인 convolution의 형태는 다음 그림과 같다. filter 하나는 input data의 channel 수만큼 존재하며 모든 channel에 대해 합성곱을 한다.
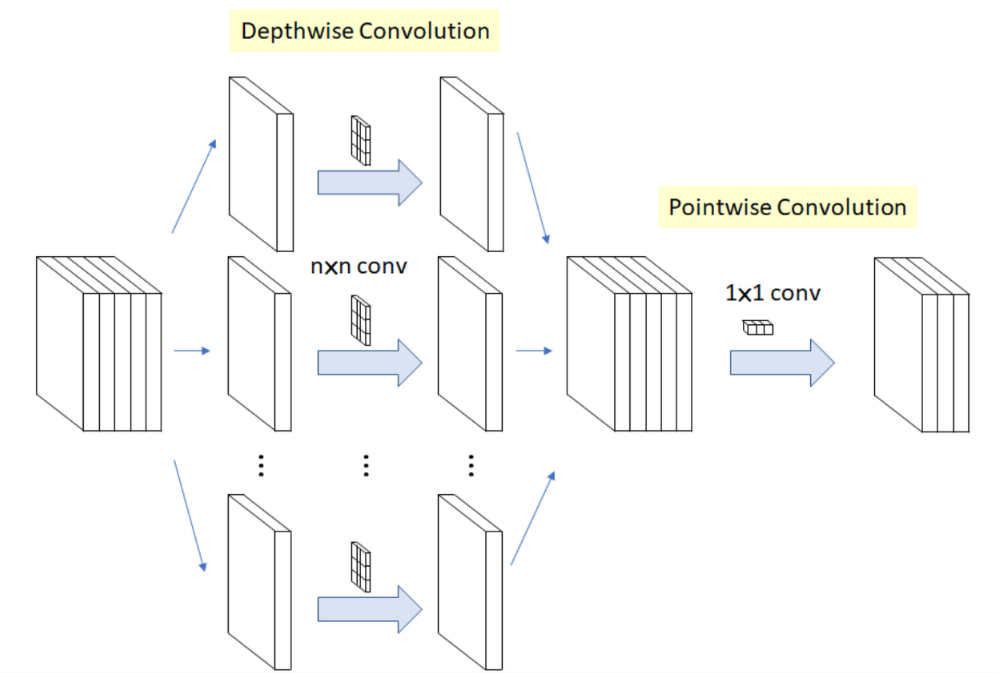
하지만 Depthwise Separable convolution은 기존의 convolution과는 차이가 있다. 위에서 언급했던 것처럼 Depthwise Separable Convolution은 Depthwise convolution과 pointwise convolution으로 나누어진다.
Depthwise convolution은 input data를 channel별로 분리를 한 후 각각의 filter로 convolution을 한다. 즉, Depthwise Convolution을 진행하게 되면 input data와 output data의 channel 수는 항상 같다.
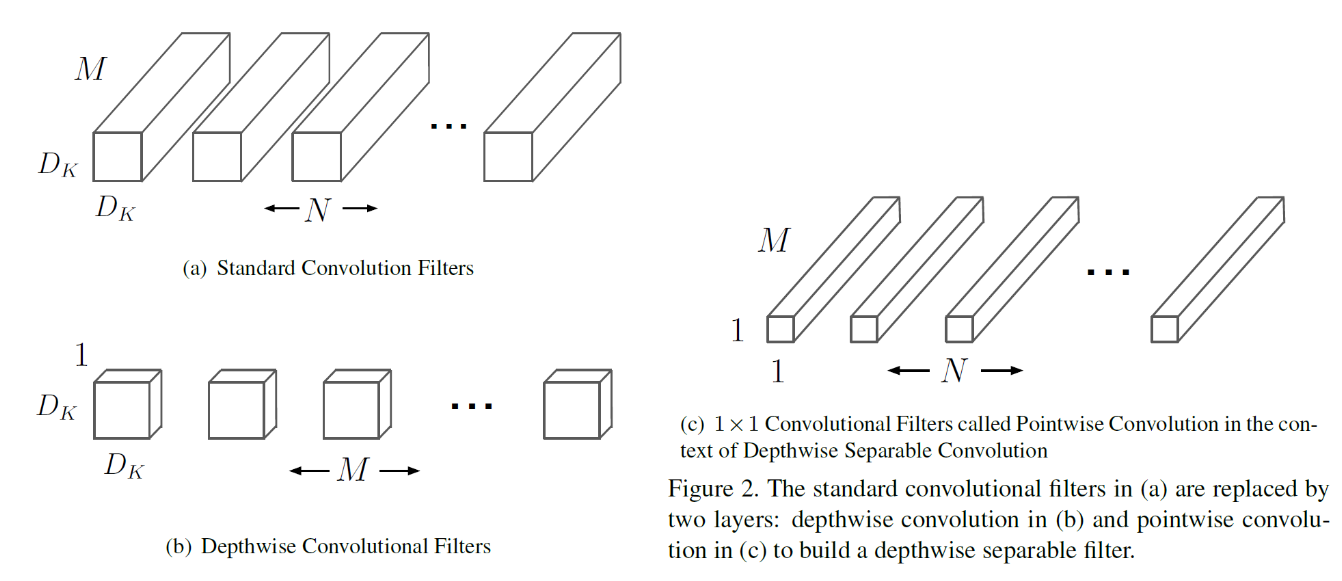
다음은 (a)일반적인 convolution, (b)Depthwise Convolution 필터, (c)pointwise convolution에 사용되는 필터 들을 시각화한 것이다. 쉽게 생각해보면 기존의 convolution은 3차원적인 계산을 한번에 수행하지만 Depthwise Separable Convolution은 두 방향의 차원을 먼저 계산한 후 나머지 한 차원에 대해 계산하는 방식이라고 생각하면 된다.

위 그림의 왼쪽은 일반적인 convolution의 구조를 보여주고 있으며, 오른쪽은 Depthwise Separable Convolution의 구조를 보여주고 있다.
예를 들어 5x5x3 input data가 들어왔다고 하자. 이 input data에 대해 convolution 계산을 하여 5x5x3 output data를 출력해야할 때 기존의 convolution기법과 Depthwise Separable Convolution기법을 사용했을 때를 비교해보자.
- 일반적인 Convolution
input data인 5x5x3가 5x5x3의 크기로 출력되기 위해서는 filter의 개수가 3개 있어야 한다. 즉, 일반적인 convolution으로 연산을 하게되면 파라미터 수는 5x5x3x3=225개가 된다.
- Depthwise Separable Convolution
depthwise convolution에 사용되는 filter는 5x5x1의 크기를 가지며 총 3개이다. pointwise convolution에 사용되는 filter는 1x1x3의 크기를 가지며 총 3개이다. 즉, 사용되는 파라미터 수는 (5x5x1x3) + (1x1x3x3) = 84개가 된다.
위와 같이 파라미터의 양이 크게 줄어드는 것을 볼 수 있다.
Width Multiplier
이미 위에서 모델의 size는 충분이 작게 만들었다. 하지만 더 작고 빠르게 만들기 위해 사용하는 것이 Width Multiplier라고 불리는 하이퍼 파라미터 α 이다. 쉽게 말해 입력과 출력의 channel을 α배 만큼 축소하는 것이다.
예를 들어, 출력 channel이 64개 였는데 α=0.25 라면 축소된 출력 channel 개수는 16개가 된다.
Resolution Multiplier
width multiplier가 channel 수를 축소하였다면 이번에 알아볼 resolution multiplier는 해상도를 줄이는 하이퍼 파라미터 ρ 이다. 즉, 입력 영상 및 중간 layer들의 해상도를 ρ배 만큼 축소하는 것이다.
예를 들어, 입력 영상의 해상도가 224x224 였을 때 ρ=0.571 이었다면, 축소된 해상도는 128x128 이 된다.
Architecture

MobileNet의 구조는 다음과 같다.
코드 구현
import torch.nn as nn
from torchsummary import summary
class MobileNetV1(nn.Module):
def __init__(self, ch_in, n_classes):
super(MobileNetV1, self).__init__()
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
# Depthwise Separable Convolution
def conv_dw(inp, oup, stride):
return nn.Sequential(
# dw
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# pw
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn(ch_in, 32, 2),
conv_dw(32, 64, 1),
conv_dw(64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AdaptiveAvgPool2d(1)
)
self.fc = nn.Linear(1024, n_classes)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
if __name__=='__main__':
# model check
model = MobileNetV1(ch_in=3, n_classes=1000)
summary(model, input_size=(3, 224, 224), device=DEVICE)
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] SENet(2018), 파이토치 구현 (0) | 2022.12.29 |
|---|---|
| [논문 리뷰] ResNeXt(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] DenseNet(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] Xception(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] ResNet(2016), 파이토치 구현 (0) | 2022.12.28 |



