
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- cnn
- 파이썬
- 논문 리뷰
- 옵티마이저
- 머신러닝
- 논문구현
- Semantic Segmentation
- Paper Review
- transformer
- Python
- object detection
- 알고리즘
- ViT
- Self-supervised
- 논문
- Computer Vision
- 파이토치
- opencv
- pytorch
- 프로그래머스
- 논문리뷰
- 코딩테스트
- 딥러닝
- Convolution
- 코드구현
- 인공지능
- Ai
- programmers
- optimizer
- Segmentation
- Today
- Total
Attention please
[논문 리뷰] AlexNet(2012), 파이토치 구현 본문
이번에 구현할 논문은
"ImageNet Classification with Deep Convolutional Neural Networks" 입니다.
이번 논문 구현을 하기 위해 사용한 프레임워크는 Pytorch입니다.
The Dataset

논문에서 사용한 데이터셋은 ImageNet dataset 입니다.
22,000개의 범주로 구성되어 있으며, 총 1500만개의 이미지가 포함된 데이터셋입니다.
하지만 저 많은 데이터들을 학습시키기에는 소요되는 시간이 많아
논문에서 사용된 모델을 구현하는데 중점으로 두고
데이터셋은 CIFAR-10 으로 두고 학습을 시켜보도록 하겠습니다.

이 데이터셋은 32x32 픽셀의 이미지이며, 총 60000개의 컬러이미지로 구성되었습니다.
또한 위에 사진에 보이는 것과 같이 총 10개의 클래스로 라벨링이 되어있습니다.
Data augmentation
256x256 사이즈의 이미지에서 랜덤하게 224x224 만큼의 이미지들을 추출한 후
이 추출한 patch들로 훈련을 진행하였습니다.
Test 데이터의 경우 본 이미지에서 중앙과 모서리 4군데 부분, 총 5 부분에서
224x224 크기의 patch들을 추출한 후 이 이미지들을 horizontal reflection하여
도합 10개의 patch들을 추출한 후 prediction을 구하였으며,
그 후에 구한 prediction값들의 평균값을 averaging하였습니다.
Architecture
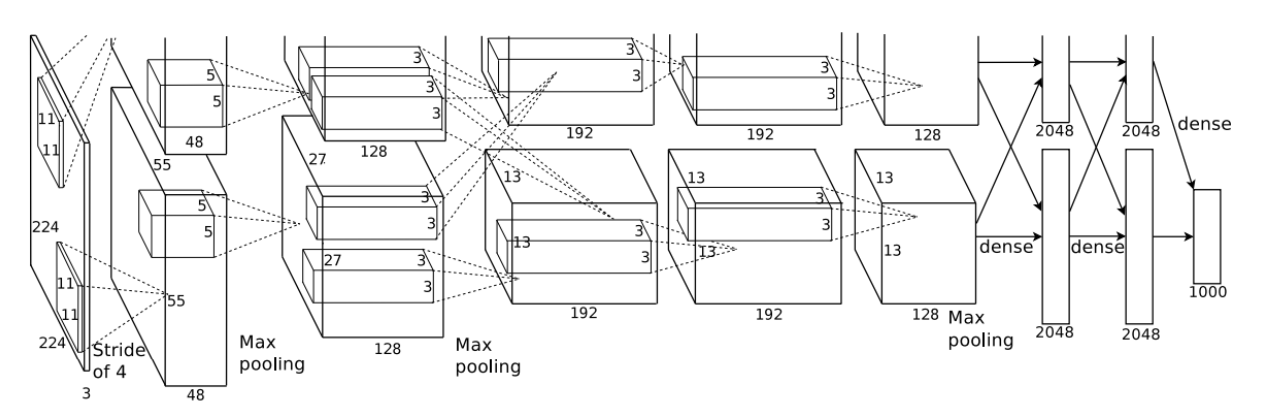
위에 사진은 AlexNet의 구조를 표현한 그림입니다.
그림과 같이 병렬구조로 모델을 만들어 gpu를 2개 사용하였고
그 당시의 부족했던 gpu의 한계를 극복하였다고 합니다.
AlexNet은
[Input layer - Conv1 - MaxPool1 - Norm1 - Conv2 - MaxPool2 - Norm2 - Conv3 - Conv4 - Conv5 - Maxpool3 - FC1- FC2 - Output layer]
으로 구성되어 있습니다.
INPUT = 227 × 227 × 3
Convolution Layer1 = 55 × 55 × 96
kernel_size = 11
stride = 4
padding = 0
Max Pooling Layer1 = 27 × 27 × 96
kernel_size = 3
stride = 2
padding = 0
Convolution Layer2 = 27 × 27 × 256
kernel_size = 5
stride = 1
padding = 2
Max Pooling Layer2 = 13 × 13 × 256
kernel_size = 3
stride = 2
padding = 0
Convolution Layer3 = 13 × 13 × 384
kernel_size = 3
stride = 1
padding = 1
Convolution Layer4 = 13 × 13 × 384
kernel_size = 3
stride = 1
padding = 1
Convolution Layer5 = 13 × 13 × 256
kernel_size = 3
stride = 1
padding = 1
Max Pooling Layer5 = 6 × 6 × 256
kernel_size = 3
stride = 2
padding = 0
Fully-Connected Layer6 = 4096
in_features = 256 × 6 × 6
out_features = 4096
Fully-Connected Layer7 = 4096
in_features = 4096
out_features = 4096
Fully-Connected Layer8 = 1000
in_features = 4096
out_features = 1000
OUTPUT = 1000
위에 보이는 것과 같이 각 층들 중 마지막 층인 Output layer가 총 1000개 나오는 것을
볼 수 있는데 제가 사용할 데이터는 class가 총 10개 있는 CIFAR-10이므로 그 부분만 수정하겠습니다.
코드구현
module 불러오기
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision
import torchvision.datasets
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import time
import os
파이토치는 gpu를 사용하기 위해 데이터나 모델들의 환경을 cuda로 넘겨줘야 합니다.
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
사용할 데이터인 CIFAR-10의 이미지 크기는 32X32이지만
논문을 최대한 따라하기 위해 227로 두었습니다.
(논문에서는 224만큼의 사이즈를 추출하였지만 size를 맞추기 위해서는 227로 resize해야함)
transform = transforms.Compose([transforms.ToTensor(), # 0~255의 값들을 0~1로 바꿔준다.
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), #편의상 평균과 표준편차는 0.5로 통일
transforms.Resize(227)])
이제 사용할 데이터를 다운받아 출력해보도록 하겠습니다.
trainset = torchvision.datasets.CIFAR10(root='/data',
train=True,
download=True,
transform=transform)
testset = torchvision.datasets.CIFAR10(root='/data',
train=False,
download=True,
transform=transform)
train_loader = DataLoader(trainset,
batch_size = 64,
shuffle=True,
num_workers=2) # CPU 작업을 몇 개의 코어를 사용해서 진행할지 설정(GPU역시 CPU의 컨트롤을 받기 때문에 설정을 해줘야함)
test_loader = DataLoader(testset,
batch_size = 64,
shuffle=True,
num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(images.shape)
AlexNet 신경망을 구현
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding = 0) #( 227 - 11 / 4 ) + 1 = 55
self.conv2 = nn.Conv2d(96, 256, 5, 1, padding = 2)
self.conv3 = nn.Conv2d(256, 384, 3, 1, 1)
self.conv4 = nn.Conv2d(384, 384, 3, 1, 1)
self.conv5 = nn.Conv2d(384, 256, 3, 1, 1)
self.fc1 = nn.Linear(256 * 6 * 6, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, kernel_size = 3, stride = 2)
x = F.local_response_norm(x, size=5, alpha=0.0001, beta=0.75, k=2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 3, 2)
x = F.local_response_norm(x, 5, 0.0001, 0.75, 2)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = F.max_pool2d(x, 3, 2)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.dropout(x, p = 0.5)
x = F.relu(self.fc2(x))
x = F.dropout(x, p = 0.5)
x = self.fc3(x) # loss인 CrossEntropyLoss에서 softmax를 포함하므로 따로 softmax를 위한 층은 생략한다.
return x
net = AlexNet().to(device)
print(net)
손실함수와 옵티마이저 설정
옵티마이저는 다른 모델들과 비교하기 위해 SGD로 통일하였습니다.
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
학습된 모델의 가중치들을 저장할 파일 이름 설정
file_name = 'alexnet_cifar10.pth'
모델 훈련함수
def train(epoch):
print('\n[ Train epoch: %d ]' % epoch)
net.train() # 훈련할 때는 train() 함수 사용
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device) # cuda 즉 gpu 환경으로 변경
optimizer.zero_grad() # 항상 역전파를 하기 전에 미분값을 0으로 만들어야 한다.
outputs = net(inputs)
loss = criterion(outputs, labels) # 신경망을 나온 결과와 라벨로 손실함수 값을 구한다.
loss.backward()
optimizer.step() # 파라미터를 업데이트 한다.
train_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0) # 라벨의 크기, 즉 학습한 데이터의 개수를 total에 반복적으로 더한다.(현재는 배치가 64이므로 64개씩 total에 더해진다.)
current_correct = (predicted == labels).sum().item() # tensor변수에서 값만 출력하기 위해 item() 함수 사용
correct += current_correct
if batch_idx % 100 == 0: # 배치수가 100개가 될 때마다 현재까지 배치 수 / 정확도 / 손실함수 를 출력
print('\nCurrent batch:', str(batch_idx))
print('Current batch average train accuracy:', current_correct / labels.size(0))
print('Current batch average train loss:', loss.item() / labels.size(0))
# 훈련이 모두 끝난 후 정확도 / 솔실함수 값을 출력
print('\nTotal average train accuarcy:', correct / total)
print('Total average train loss:', train_loss / total)
def test(epoch):
print('\n[ Test epoch: %d ]' % epoch)
net.eval() # 테스트 할 때는, eval() 함수 사용
loss = 0
correct = 0
total = 0
for batch_idx, (inputs, labels) in enumerate(test_loader):
inputs, labels = inputs.to(device), labels.to(device)
total += labels.size(0)
outputs = net(inputs)
loss += criterion(outputs, labels).item()
_, predicted = outputs.max(1)
correct += (predicted == labels).sum().item()
print('\nTotal average test accuarcy:', correct / total)
print('Total average test loss:', loss / total)
state = {
'net' : net.state_dict()
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/' + file_name)
print('Model Saved!')파이토치에서 모델을 저장하고 불러오기 위한 2가지 방법
<state_dict 를 저장하고 불러오는 것>
학습된 모델의 파라미터만을 저장하기에 모델을 불러올 때 유연함을 살릴 수 있다.
<전체 모델을 저장하는 것>
직관적인 문법을 사용하며 코드의 양도 적다.
단점 : 직렬화(serialized)된 데이터가 모델을 저장할 때 사용한 특정 클래스 및 디렉토리 구조에 종속(bind)됨
(why? : pickle이 모델 클래스 자체를 저장하지 않기 때문)
불러올 때 사용되는 클래스가 포함된 파일의 경로를 저장한다.
→ 작성한 코드가 다른 프로젝트에서 사용되거나 리팩토링을 거치는 등의 과정에서 동작하지 않을 수 있다.
Training
start_time = time.time()
for epoch in range(0, 10):
train(epoch)
test(epoch)
print('\nTime elapsed:', time.time() - start_time)
학습결과
Test Accuracy : 47.95%
Test Loss : 0.0221
걸린 시간 : 약 21분
정확도 47%... 처참한 수치입니다.
하지만 2012년도의 오래된 모델이라는 점과 학습을 10epoch밖에 돌리지 않았음을 생각하면
충분히 이해되는 수치이기도 합니다.
이번 논문의 AlexNet은 gpu의 한계를 보완하기 위해
층을 병렬구조로 쌓았다는 점이 크다고 볼 수 있습니다.
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] DenseNet(2017), 파이토치 구현 (0) | 2022.12.29 |
|---|---|
| [논문 리뷰] Xception(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] ResNet(2016), 파이토치 구현 (0) | 2022.12.28 |
| [논문 리뷰] Inception V1 - GoogLeNet(2014), 파이토치 구현 (0) | 2022.12.28 |
| [논문 리뷰] VGGNet(2015), 파이토치 구현 (0) | 2022.10.01 |



