
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Computer Vision
- 논문구현
- Segmentation
- 논문리뷰
- 코딩테스트
- Self-supervised
- 파이토치
- 파이썬
- 옵티마이저
- programmers
- opencv
- pytorch
- Ai
- Python
- 딥러닝
- 논문
- 코드구현
- object detection
- cnn
- Convolution
- 논문 리뷰
- 알고리즘
- Paper Review
- Semantic Segmentation
- optimizer
- 머신러닝
- transformer
- 프로그래머스
- 인공지능
- ViT
- Today
- Total
Attention please
[논문 리뷰] ResNeXt(2017), 파이토치 구현 본문
이번에 리뷰할 논문은 "Aggregated Residual Transformations for Deep Neural Networks " 이다.
CNN의 성능을 높이기 위해 가장 먼저 드는 생각은 깊고(dimension) 넓게(scale) 만드는 것이다. 하지만 본 논문에서는 저 두가지가 아닌 cardinality를 키우는 것에 초점을 맞추었다.
- cardinality : the size of the set of transformations (똑같은 형태의 블록 개수)
Split - Transform - Merge
즉, 같은 block을 반복하여 구축하는 것이 모델의 깊이와 넓이를 크게 가져가는 것보다 정확도에 더 큰 영향을 미친다는 것인데 이는 Inception module과 비슷한 형태를 가진다. resnet에서 inception module을 적용한 모델은 Inception ResNet으로 이미 존재한다.
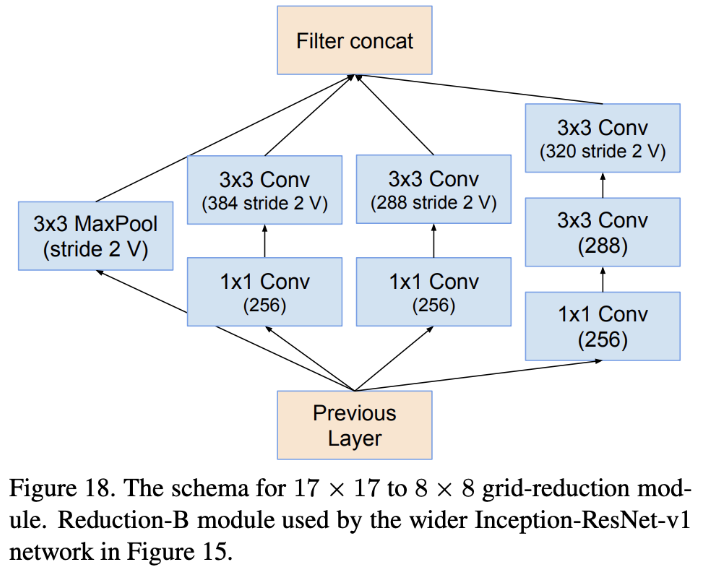
Inception module은 input을 저차원의 임베딩으로 split하고, 특정한 filter set에 대해 transform을 한 후 concatenation을 하여 merge한다. 이는 ResNeXt의 구조와 비슷하지만 각 path에 대해 같은 layer들을 가진다는 점과는 차이가 있다. Inception Module은 각 path에 대해 다른 구성을 가지는데에 반해 ResNeXt은 각 path에 대해 같은 layer 구성을 가지며 이를 grouped convolution이라 한다.
Grouped Convolution
지금까지 CNN 모델들은 보다 더 깊은 layer를 쌓는데 집중해왔다. 하지만 layer가 많아지면 그만큼 하이퍼 파라미터가 증가하는 문제가 있다. 하지만 grouped convolution의 경우 같은 layer를 가지기 때문에 그만큼 하이퍼 파라미터의 수가 줄어들게 된다.
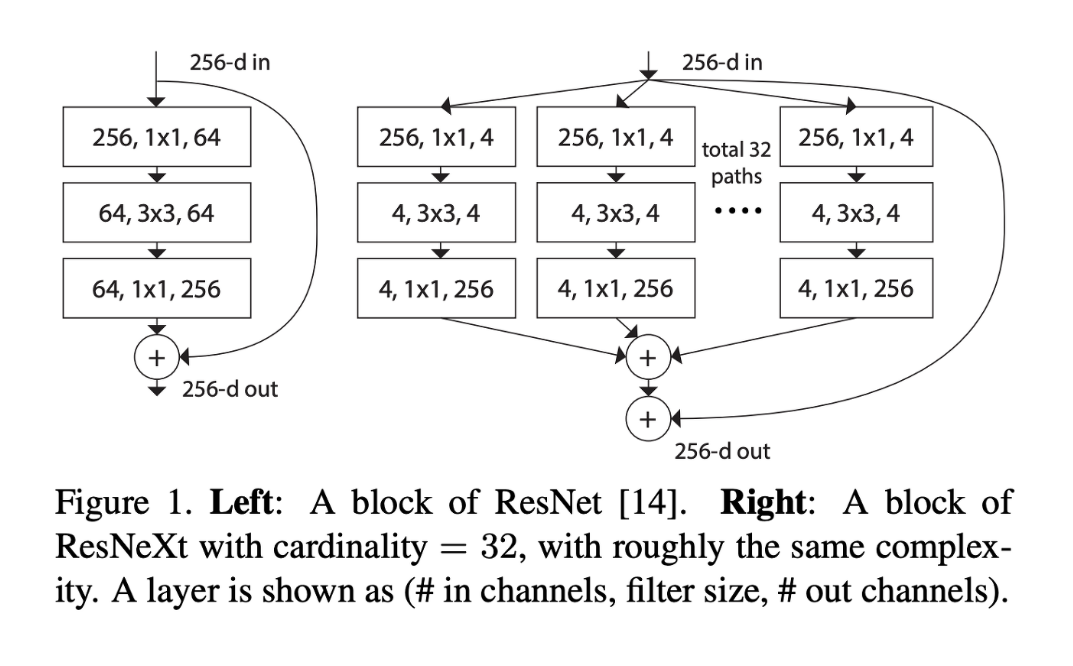
위 그림의 왼쪽은 ResNet의 block 구조이며, 오른쪽은 하이퍼 파라미터 cardinality를 32로 설정한 ResNeXt의 block 구조이다. ResNeXt는 ResNet200, Inception-ResNet-V2와 같은 다른 모델들에 비해 더 간단한 구조를 가졌지만 더 좋은 성능을 보였다.
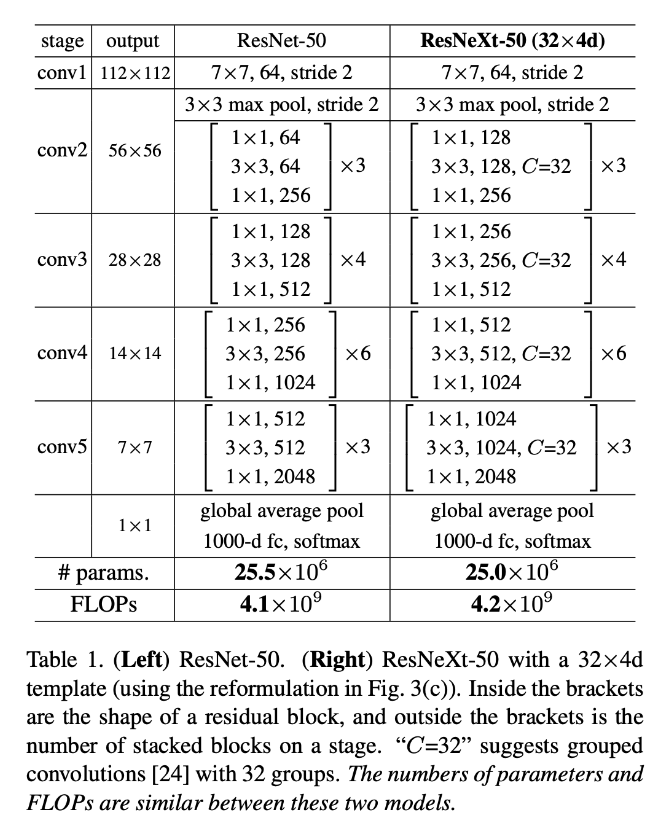
위 그림의 왼쪽은 ResNet-50이고, 오른쪽은 ResNeXt-50으로 매우 비슷한 구조를 보여주고 있다.
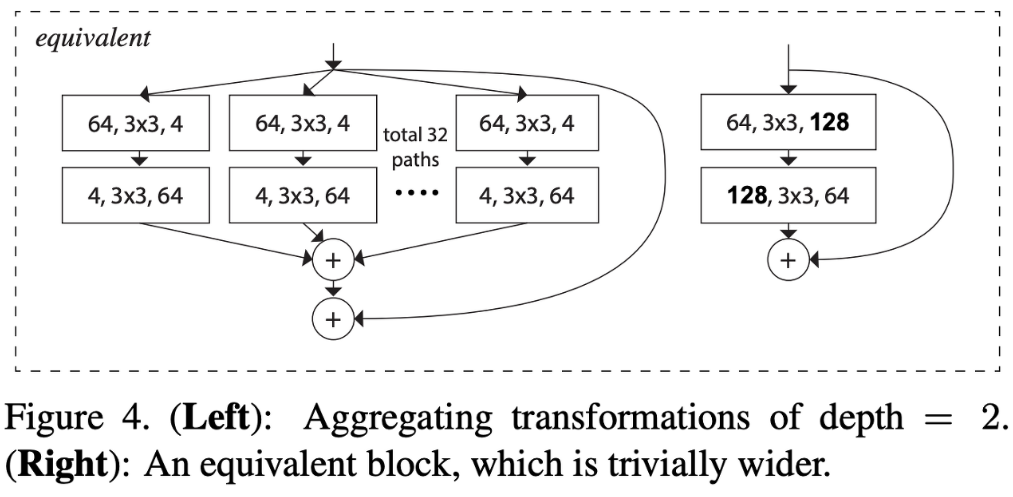
ResNet의 block안에는 2개의 convolution layer을 가져 depth가 2였다. 하지만 위 그림과 같이 ResNeXt에서 depth가 2가 되면 group convolution을 하는 의미가 없어지기 때문에 depth는 최소 3이상이어야 한다.
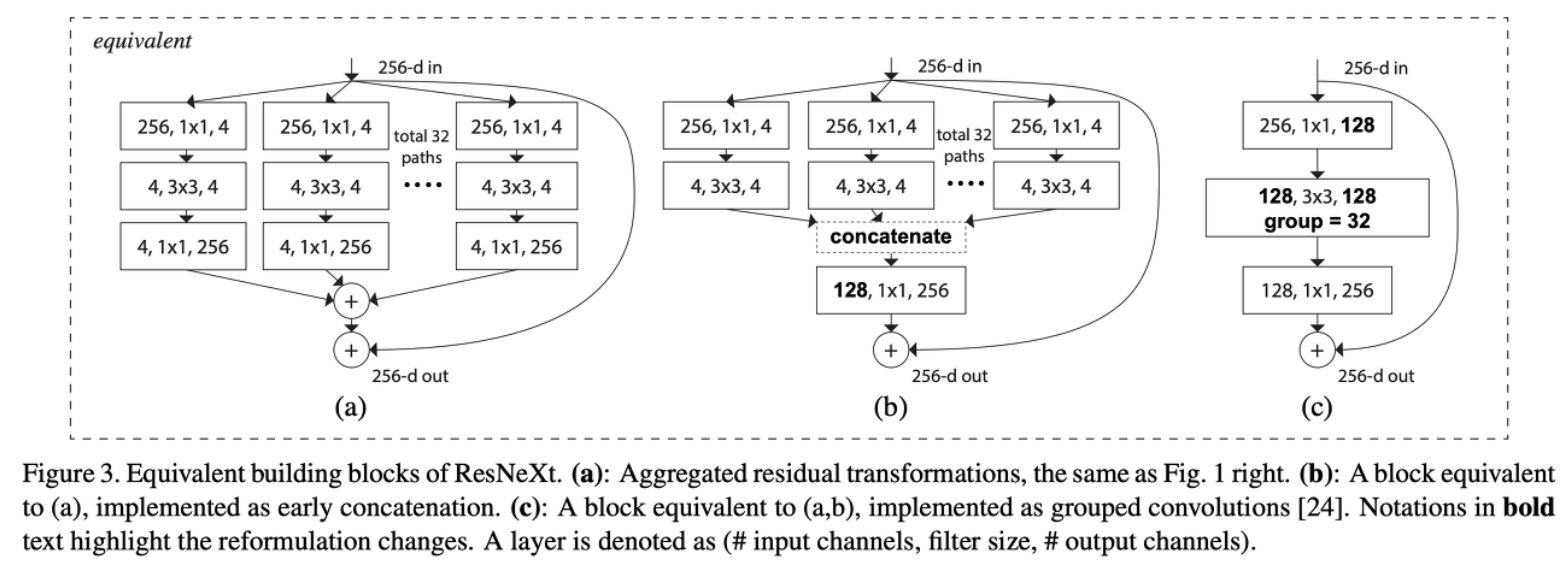
(a) (b) (c) block들은 모두 equivalent하다. 각각 살펴보자면
(a) channel 수가 4개인 32개의 path가 병렬로 실행된 후 다시 합해진다.
(b) channel 수가 4개인 32개의 path가 병렬로 실행되고, 1x1 convolution으로 channel을 늘리지 않고 concatenation을 한 후 1x1 convolution을 수행한다.
(c) group convolution 을 시행한다.
즉, ResNeXt 구조는 group convolution을 해줌으로써 표현할 수 있다.
Experiment
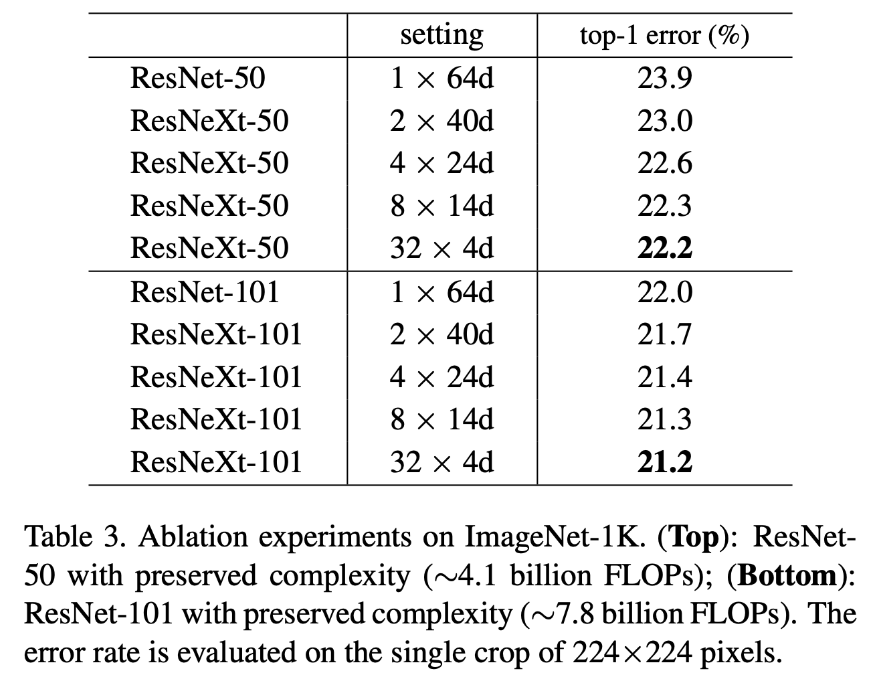
위 그림과 같이 cardinality를 1에서 32로 증가하면 할수록 error가 줄어드는 것을 볼 수 있다.
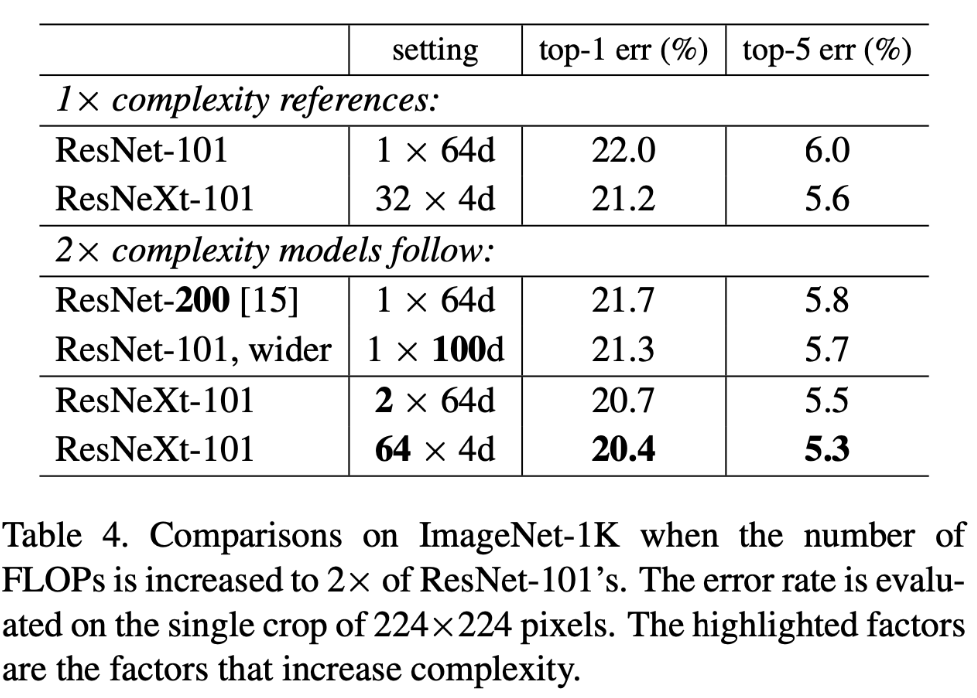
기본적으로 model의 성능을 높이기 위해서는 더 깊고 넓게 만들어야한다고 하였다. 하지만 위 그림을 보면 ResNet을 깊고 넓게 만드는 것에 비해 cardinality를 높이는 것이 error를 더 낮추는 것을 볼 수 있다.
코드 구현
먼저 Cardinality, Depth, Basewidth를 설정해준다.
CARDINALITY = 32
DEPTH = 4
BASEWIDTH = 64
다음으로 ResNext 모델의 BottleNeck를 class로 구현하자.
class ResNextBottleNeckC(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super().__init__()
C = CARDINALITY #How many groups a feature map was splitted into
#"""We note that the input/output width of the template is fixed as
#256-d (Fig. 3), We note that the input/output width of the template
#is fixed as 256-d (Fig. 3), and all widths are dou- bled each time
#when the feature map is subsampled (see Table 1)."""
D = int(DEPTH * out_channels / BASEWIDTH) #number of channels per group
self.split_transforms = nn.Sequential(
nn.Conv2d(in_channels, C * D, kernel_size=1, groups=C, bias=False),
nn.BatchNorm2d(C * D),
nn.ReLU(inplace=True),
nn.Conv2d(C * D, C * D, kernel_size=3, stride=stride, groups=C, padding=1, bias=False),
nn.BatchNorm2d(C * D),
nn.ReLU(inplace=True),
nn.Conv2d(C * D, out_channels * 4, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * 4),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * 4:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * 4, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * 4)
)
def forward(self, x):
return F.relu(self.split_transforms(x) + self.shortcut(x))
이제 ResNeXt 모델을 구현하자.
class ResNext(nn.Module):
def __init__(self, block, num_blocks, class_names=100):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.conv2 = self._make_layer(block, num_blocks[0], 64, 1)
self.conv3 = self._make_layer(block, num_blocks[1], 128, 2)
self.conv4 = self._make_layer(block, num_blocks[2], 256, 2)
self.conv5 = self._make_layer(block, num_blocks[3], 512, 2)
self.avg = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * 4, 100)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def _make_layer(self, block, num_block, out_channels, stride):
"""Building resnext block
Args:
block: block type(default resnext bottleneck c)
num_block: number of blocks per layer
out_channels: output channels per block
stride: block stride
Returns:
a resnext layer
"""
strides = [stride] + [1] * (num_block - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * 4
return nn.Sequential(*layers)
ResNeXt의 파라미터 중 num_blocks를 조절하여 다양한 층의 ResNeXt를 구현할 수 있다.
def resnext50():
""" return a resnext50(c32x4d) network
"""
return ResNext(ResNextBottleNeckC, [3, 4, 6, 3])
def resnext101():
""" return a resnext101(c32x4d) network
"""
return ResNext(ResNextBottleNeckC, [3, 4, 23, 3])
def resnext152():
""" return a resnext101(c32x4d) network
"""
return ResNext(ResNextBottleNeckC, [3, 4, 36, 3])
'논문 리뷰 > Image classification' 카테고리의 다른 글
| [논문 리뷰] EfficientNet(2019), 파이토치 구현 (2) | 2022.12.30 |
|---|---|
| [논문 리뷰] SENet(2018), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] MobileNet V1(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] DenseNet(2017), 파이토치 구현 (0) | 2022.12.29 |
| [논문 리뷰] Xception(2017), 파이토치 구현 (0) | 2022.12.29 |



