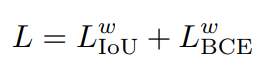| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- object detection
- 머신러닝
- 코드구현
- 논문
- 논문 리뷰
- Convolution
- Semantic Segmentation
- Ai
- 알고리즘
- Paper Review
- Computer Vision
- optimizer
- Segmentation
- 파이썬
- Self-supervised
- 딥러닝
- 옵티마이저
- 논문리뷰
- 파이토치
- opencv
- cnn
- programmers
- 코딩테스트
- transformer
- ViT
- 프로그래머스
- pytorch
- 논문구현
- Python
- 인공지능
- Today
- Total
Attention please
[논문 리뷰] ESFPNet: efficient deep learning architecture for real-time lesion segmentation in autofluorescence bronchoscopic video(2022) 본문
[논문 리뷰] ESFPNet: efficient deep learning architecture for real-time lesion segmentation in autofluorescence bronchoscopic video(2022)
Seongmin.C 2023. 7. 30. 01:15이번에 리뷰할 논문은 ESFPNet: efficient deep learning architecture for real-time lesion segmentation in autofluorescence bronchoscopic video 입니다.
https://paperswithcode.com/paper/esfpnet-efficient-deep-learning-architecture
Papers with Code - ESFPNet: efficient deep learning architecture for real-time lesion segmentation in autofluorescence bronchosc
#2 best model for Medical Image Segmentation on ETIS-LARIBPOLYPDB (mean Dice metric)
paperswithcode.com
본 논문의 목적은 폐암(Lung cancer)를 초기에 탐지하기 위해 autofluorescence bronchoscopy (AFB) 비디오 프레임에 대해 병변 영역을 segmentation 하는 것입니다. AFB 비디오 프레임의 예시는 다음과 같습니다.
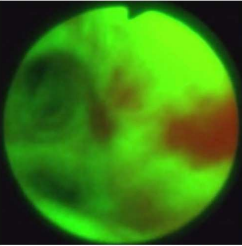
AFB 비디오 역시 기관지 영역을 정상과 비정상으로 구분한다고 합니다. 병변 영역은 붉은색, 정상 조직은 녹색으로 나타낸다고 하죠. 하지만 이 영상을 통해 수동으로 검사하기에는 시간 비용이 너무 많이 들며, 오류 역시 많다는 문제가 있었습니다. 이러한 문제를 해결하기 위해 Deep learning을 사용하여 segmentation을 수행하는 것으로 대체하고자 본 논문에서는 ESFPNet 모델을 제안합니다.
ESFPNet
ESFPNet 모델은 Encoder와 Decoder 로 구성됩니다. encoder의 경우 Mix transformer(MiT) 를 사용하였으며, decoder 부분에는 본 논문에서 제안하는 efficient stage-wise feature pyramid(ESFP) 구조를 사용합니다.
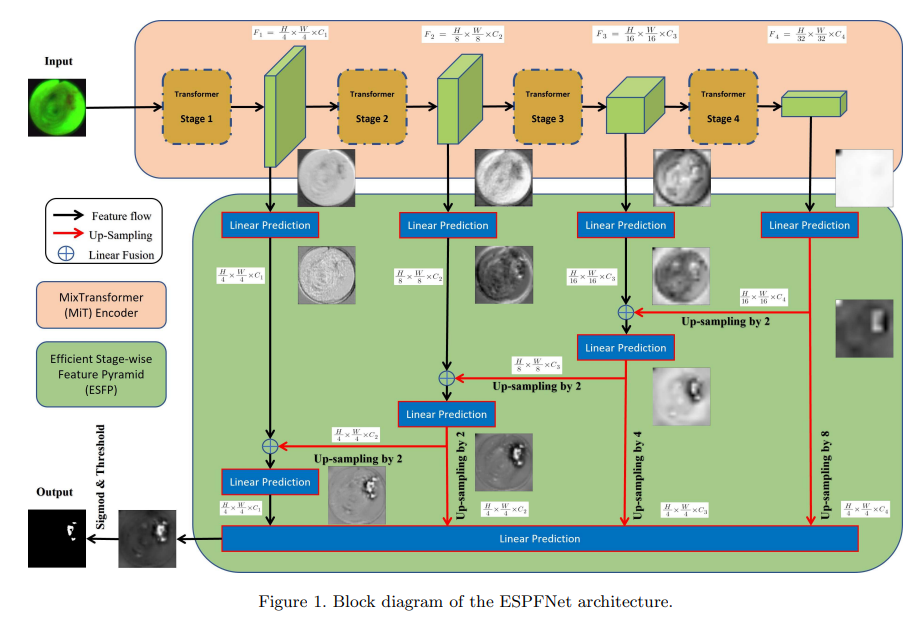
Backbone
CNN 기반 encoder는 모든 image pixel들이 그 주변 pixel에 의존한다는 아이디어에 기반을 두고 수행됩니다. filter를 사용하여 관련된 local feature를 추출하죠. 하지만 연구진들은 "filter에 고려되는 patch만을 고려하지 않고 모든 이미지 데이터를 사용하는 처리 모델이 나오면 더 좋은 성능을 보여주지 않을까?" 라는 생각을 하였으며, 이러한 컨셉을 도와주는 예시가 바로 Vision transformer(ViT) 입니다.
ViT는 대부분의 CNN module 보다 더 좋은 성능을 보여주었습니다. 이런 ViT를 기반으로 만들어진 Mix Transformer(MiT)는 4번의 overlapping path-merging module과 self attention prediction을 4번의 stage에서 수행되며, 이런 단계들은 high resolution의 coarse feature를 추출할 뿐만 아니라, low resolution의 fine-grained feature도 제공해줍니다. 게다가 이런 높고 낮은 해상도의 feature들은 semantic segmentation의 performance에 중요한 기여를 하죠.
하지만 transformer를 encoder로 사용하는 것에는 한계가 존재했습니다. 바로 이미지 픽셀들이 지역적으로 상관관계가 있으며, 그들의 상관관계 map이 불변하다는 개념을 내포한 local inductive bias가 부족하다는 것인데요. 이는 data hunger problem을 초래하게 됩니다. 즉, 소규모 데이터셋으로는 transformer encoder를 학습시키는데 한계가 존재했으나 transfer learning을 사용하여 해당 문제를 해결할 수 있었습니다. 본 논문 역시 encoder로 사용된 MiT를 pretrain하여 사용하였으며, 초기화된 decoder와 함께 다시 train 시켰다고 합니다.
Efficient stage-wise feature pyramid (ESFP)
이전 연구들은 transformer의 얕은 층에서 얻은 local feature 가 model의 performance에 영향을 준다는 것을 입증한 바가 있었습니다. 하지만 기존의 Segformer와 같은 경우 다단계 feature들을 모두 동등하게 결합하여 segmentation result를 예측하도록 설계하였죠. 이는 local feature를 충분하고 선택적으로 사용하는 능력이 부족해지는 결과를 초래합니다.
하지만 SSFormer의 경우 깊은 층에서 얕은 층으로 feature map들을 융합하여 local feature가 점차 모델의 주목을 중요한 영역으로 이동시키는데 성공했습니다. 하지만 이런 SSFormer 역시 low-level feature의 기여를 강화하지만, high-level feature의 사용이 약화된다는 문제가 있었습니다.
이런 문제들을 해결하기 위해 multi-stage feature들을 효율적으로 활용하는 ESFP 를 사용합니다. ESFP는 각 단계 출력의 linear prediction에서 시작하여 global에서 local 방향으로 feature들을 linear하게 융합합니다.
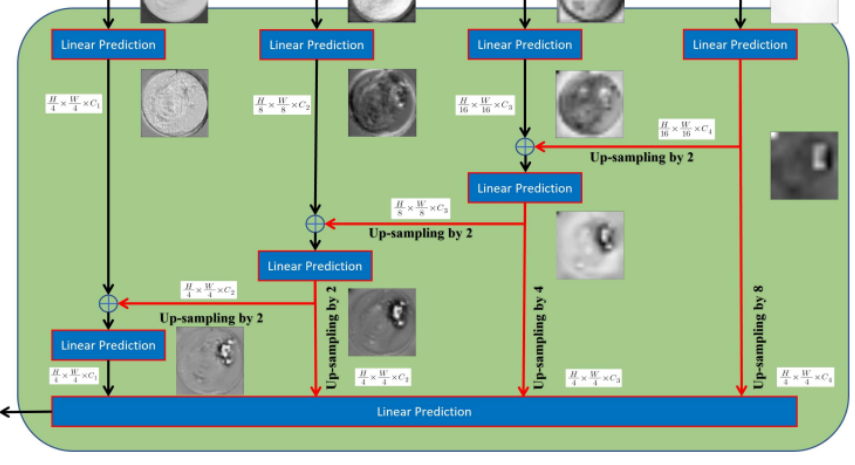
위 decoder 부분인 ESFP 부분을 보니 각 layer의 feature map들이 계속 융합되면서 high -> low 방향으로 linear prediction하는 모습을 확인할 수 있습니다.
Loss function
본 논문에서는 손실함수를 IoU loss와 BCE loss 를 결합하여 사용하였다고 합니다.