
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 머신러닝
- 프로그래머스
- Python
- Computer Vision
- 딥러닝
- 논문리뷰
- 파이토치
- pytorch
- 논문
- 인공지능
- object detection
- Segmentation
- transformer
- cnn
- Convolution
- opencv
- ViT
- 논문 리뷰
- 파이썬
- optimizer
- 옵티마이저
- 코드구현
- 알고리즘
- 코딩테스트
- Ai
- programmers
- 논문구현
- Paper Review
- Self-supervised
- Semantic Segmentation
- Today
- Total
Attention please
[논문 리뷰] SSformer: A Lightweight Transformer for Semantic Segmentation(2022) 본문
[논문 리뷰] SSformer: A Lightweight Transformer for Semantic Segmentation(2022)
Seongmin.C 2023. 7. 28. 22:10이번에 리뷰할 논문은 SSformer: A Lightweight Transformer for Semantic Segmentation 입니다.
https://paperswithcode.com/paper/ssformer-a-lightweight-transformer-for
Papers with Code - SSformer: A Lightweight Transformer for Semantic Segmentation
Implemented in one code library.
paperswithcode.com
2017년도에 NLP분야에서 transformer 모델이 출시된 이후 많은 변화가 있었습니다. computer vision 역시 마찬가지였으며, 자연어에 특화된 transformer를 변형하여 CV에서 사용할 수 있는 ViT 역시 제안되었었죠. 하지만 ViT 모델의 경우 local neighborhood에 대한 inductive bias가 부족했습니다. 아무래도 이미지를 강제로 patch로 나눈 후 sequence하게 처리하다보니 공간적 위치가 중요한 이미지에 대해서는 맞지 않았던 것이죠. 물론 대량의 데이터셋으로 학습할 경우 inductive bias를 해결하여 기존의 CNN기반 모델보다 좋은 performance를 보여주긴 했습니다. 또 ViT는 높은 시간 복잡도를 가지고 있었기 때문에 모델 구조가 복잡한 semantic segmentation과 같은 다른 비전 분야에서는 적합하다고 할 수 없었습니다.
하지만 이런 ViT의 inductive bias 부족을 해결한 Swin transformer 가 등장합니다. 해당 모델의 자세한 내용은 밑의 링크를 참고해주시기 바랍니다.
Swin transformer의 경우 window 내의 patch에 대해서만 self-attention을 수행함으로써 기존 transformer 기반 모델의 계산 복잡도가 높았던 문제를 해결합니다. 또한 층이 깊어지면 깊어질수록 patch들을 merge하여 마치 CNN기반 모델의 pooling layer의 역할을 수행하죠. 즉, 단순히 전역적인 정보만을 학습할 수 있었던 기존의 transformer 기반 모델과 달리 local 한 정보 역시 학습할 수 있어 inductive bias를 크게 가져갈 수 있었습니다.
하지만 이런 Swin-transformer도 한가지 문제가 있었는데 바로 classification을 위해 설계된 모델이기에 segmentation과 같은 dense한 prediction을 수행할 때 최적의 성능이 나오지 않을 수 있다는 것입니다. 단순히 swin-transformer에 다른 model을 결합하는 것은 모델의 크기와 파라미터 수가 증가하는 결과를 초래했던 것이죠.
본 논문에서는 Swin-transformer의 semantic segmentation을 재해석하여 효과적이고 경량화한 SSFormer 모델을 제안하게 됩니다.
SSFormer
SSFormer 모델은 2가지 module로 구성됩니다.
1. Swin transformer
각 층에 대해 patch merging을 적용하여 multi-level의 feature를 추출합니다.
2. Lightweight ALL-MLP decoder
앞서 Swin transformer에서 추출한 각 계층의 feature들을 융합하며, 모든 계층이 MLP로 구성됩니다.
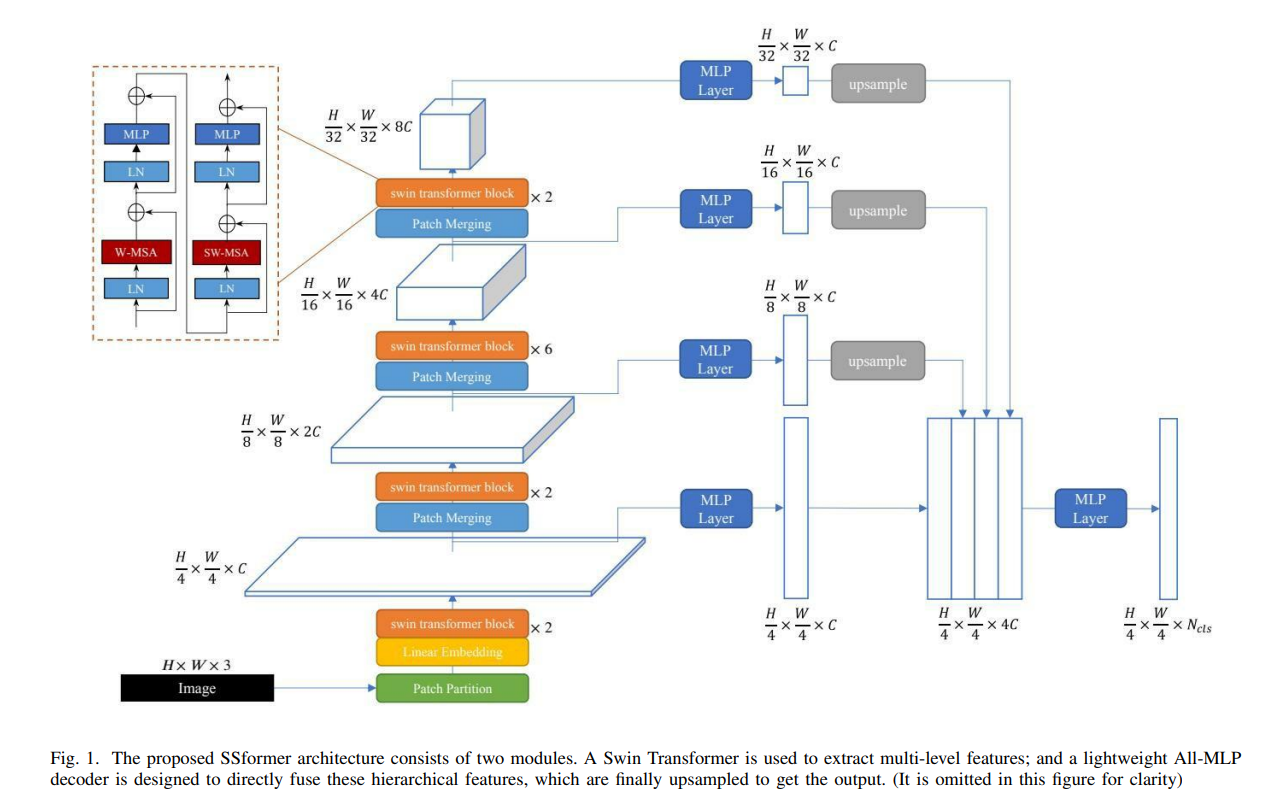
SSFormer의 전체적인 architecture는 위 figure와 같이 구성됩니다. input으로는 아주 기본적인 HxWx3 shape의 이미지가 들어오게 되죠. SSFormer의 encoder는 swin transformer와 완전히 동일합니다. 우선 이미지를 사이즈가 4인 patch로 split하며 해상도가 4배만큼 감소하여 $ \frac{H} {4} \times \frac{W} {4} \times C $의 크기를 가지게 됩니다. 다음으로는 linear embedding을 통해 임의의 차원인 C로 projection을 수행하며, swin transformer block을 거쳐 feature map을 반환합니다. 기본적으로 self-attention은 shape에 대해 멱등(Idempotent)하기 때문에 첫 번째 계층의 feature map의 shape 역시 $ \frac{H} {4} \times \frac{W} {4} \times C $ 크기를 가지게 되겠죠.
다음으로는 Patch Merging을 수행합니다. 이 역시 swin transformer에서 제안된 기법이며, 서로 이웃하는 2x2 patch를 merge하여 해상도를 2배 만큼 감소시킵니다. 이는 마치 처음에는 local한 feature에 대해 추출하다 층이 깊어질수록 global한 feature를 추출하는 CNN의 Pooling layer의 역할과 아주 흡사합니다. 2배만큼 merging하였기 때문에 feature map의 shape은 $ \frac{H} {8} \times \frac{W} {8} \times C $ 크기를 가지게 됩니다.
또한 CNN과 유사하게 해상도를 축소시킴과 동시에 channel을 증가시키기 위해 1x1 convolution을 사용하여 C차원에서 2C차원으로 2배만큼 channel수를 증가시킵니다. 다음 단계인 3, 4 stage 역시 2 stage에서 했던 수행방식을 그대로 반복합니다.
여기까지가 SSFormer의 encoder 부분이었던 swin-transformer의 수행 방식이었습니다. 다음으로는 이 swin transformer에서 추출한 각 계층을 융합하여 output을 예측하는 all-MLP decoder 부분을 살펴보도록 하죠.
이름에서 알 수 있듯이 decoder의 모든 계층은 MLP 계층으로 이루어져 있습니다. 각 계층의 feature map을 받아 MLP layer을 거쳐 모두 channel수가 C차원이 되도록 변환해줍니다. 그다음으로 shape이 $ \frac{H} {4} \times \frac{W} {4} \times C $ 크기를 가지도록 up-sampling 시켜줍니다. 이렇게 각 4개의 계층에서 추출한 feature map을 모두 concate를 한 후 class의 수만큼 channel 수를 조절하기 위해 한번더 MLP layer를 거쳐 최종 output을 출력하게 됩니다.



