| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Convolution
- 코드구현
- Ai
- 논문구현
- optimizer
- Self-supervised
- Computer Vision
- 옵티마이저
- 파이토치
- 프로그래머스
- opencv
- object detection
- pytorch
- 논문
- Python
- Segmentation
- cnn
- 코딩테스트
- 알고리즘
- 머신러닝
- Paper Review
- 논문리뷰
- 파이썬
- programmers
- Semantic Segmentation
- transformer
- 인공지능
- ViT
- 딥러닝
- 논문 리뷰
- Today
- Total
Attention please
[논문 리뷰] PVT v2: Improved Baselines with Pyramid Vision Transformer(2021) 본문
[논문 리뷰] PVT v2: Improved Baselines with Pyramid Vision Transformer(2021)
Seongmin.C 2023. 7. 29. 15:53이번에 리뷰할 논문은 PVT v2: Improved Baselines with Pyramid Vision Transformer 입니다.
https://paperswithcode.com/paper/pvtv2-improved-baselines-with-pyramid-vision
Papers with Code - PVT v2: Improved Baselines with Pyramid Vision Transformer
#24 best model for Object Detection on COCO-O (Average mAP metric)
paperswithcode.com
self-attention을 기반으로 하는 transformer를 computer vision에 적용하려는 연구들이 이어졌으며, 가장 대표적으로 Vision Transformer(ViT) 모델이 있습니다. 하지만 ViT의 경우 각 Transformer block이 생성하는 feature map이 single-scale이라는 특징때문에 dense prediction을 요하는 object detection, segmentation과 같은 vision task에는 적합하지 않다는 문제가 있었죠. 이런 문제를 해결하고자 각 transformer block의 feature map을 multi-scale로 생성되도록 제안된 Pyramid Vision Transformer(PVT)가 제안되었습니다. 모든 layer에 patch embedding을 적용하여 층이 깊어질수록 scale이 감소시켜 수행되었죠. 하지만 이런 PVT에도 다음과 같은 문제가 존재했습니다.
- 고해상도 이미지를 처리할 때 computational complexity가 상대적으로 크다.
- 이미지를 non-overlapping patch로 처리하기 때문에 local continuty가 어느정도 손실된다.
- PVT의 position embedding은 고정 크기이기에 임의 크기의 이미지를 처리하는데 유연하지 않다.
본 논문은 기존 PVT v1의 문제를 해결하고자 여러 해결방안들을 제안합니다.
Linear Spatial Reduction Attention
기존의 PVT는 attention operation에서 발생하는 높은 computational cost를 감소하기 위해 Spatial Reduction을 도입합니다. 이에 대한 자세한 설명은 밑의 링크를 참고해주시기 바랍니다.
기존의 PVT v1은 Spatial Reduction을 하기 위해 Spatial Reduction Attention(SRA) layer를 추가하였습니다. 하지만 본 논문에서는 더 많은 spatial reduction을 수행하기 위해 기존의 SRA를 linear SRA로 대체합니다.
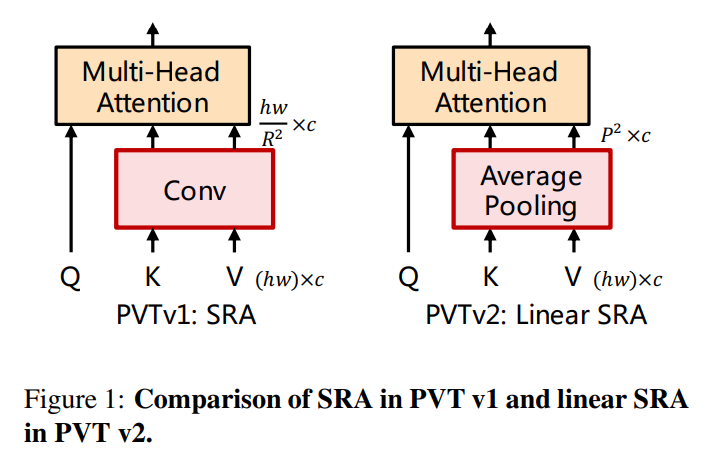
논문을 읽으면서 한가지 헷갈리는 부분이 있었습니다. PVT v1의 SRA를 convolution을 사용하여 수행한다고 언급을 하였는데 사실 정확하게 말하자면 이는 틀린 부분입니다. (물론 제가 잘못 이해한 부분일 수 있는 점 참고해주세요)
기존의 SRA는 convolution을 사용하는 것이 아닌 Reduction ratio 만큼 reshape을 하여 해상도를 감소시킨 후 linear projection을 수행하여 channel 수를 기존의 channel 수로 맞춰주는 것이 맞습니다. 아마 본 논문에서는 제안하는 linear SRA를 직관적으로 비교하기 위해 convolution이라 표현한게 아닌가 싶습니다.
다시 돌아와서 SRA는 위 figure에서 확인할 수 있듯이 Key, Value에 적용하여 감소시킵니다. 기존의 K, V의 shape은 $ (hw) \times c $ 였지만 $ P^{2} \times c $가 되도록 Adaptive Average Pooling을 적용시켜줍니다. 물론 Adaptive Average Pooling을 수행하였기 때문에 따로 channel 수의 변화는 없으므로 따로 linear projection을 수행할 필요도 없습니다. 실제로 기존의 SRA와 Linear SRA의 complexity를 비교하면 다음과 같이 크게 감소한 모습을 확인할 수 있습니다.
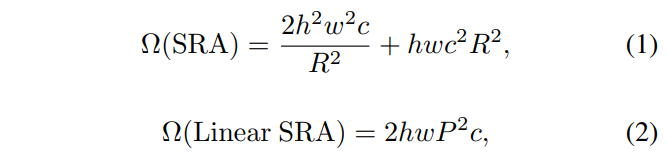
Overlapping Patch Embedding
PVT v1에서 적용된 patch embedding은 기존의 ViT에서 수행되었던 patch embedding과 차이가 없었습니다. 겹치는 부분 없이 patch들을 split하여 embedding을 수행하였죠. 하지만 본 논문은 이 방식이 local continuity information을 학습하는데 한계가 있다고 주장합니다. 좀 더 연속적인 local한 정보를 학습하기 위해 patch를 over-lapping 방식으로 split을 수행합니다.
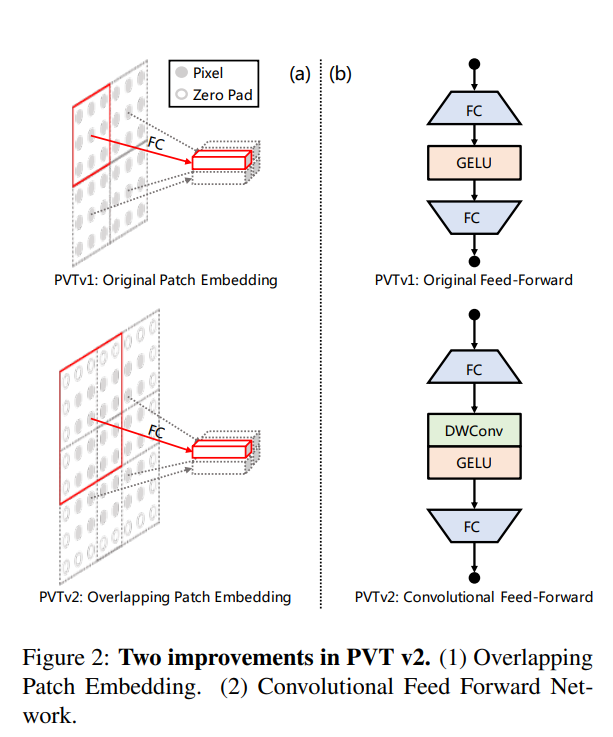
위 figure와 같이 patch들이 서로 겹치도록 convolution을 사용하기 때문에 기존의 patch embedding에 비해 출력되는 feature map의 해상도가 절반만큼 감소합니다. 이런 감소된 해상도를 매꿔주기 위해 padding 처리를 추가로 수행하게 됩니다.
위 Overlapping Patch Embedding을 수행하기 위해 convolution을 사용하여 수행됩니다. 해당 convolution의 설정값은 다음과 같습니다.
- Stride : S
- Kernel size : 2S - 1
- Padding size : S - 1
- Kernel number : C'
하지만 위의 내용만 보고는 어떻게 작동되는지 방식을 이해하기 힘들 수 있어 밑의 그림으로 해당 convolution 연산을 표현해보았으니 참고해보시면 좋을 것 같습니다.

만약 Stride 크기를 3이라고 설정한다면 Kernel size는 5가 됩니다. Stride와 Kernel size 값이 동일하지 않기 때문에 차이 값인 2씩 overlapping 되어 연산이 진행됩니다. 위 그림을 보면 첫 번째 열 부분에 kernel이 가장 밑으로 같을 때 overlap된 2만큼 남는 모습을 보여줍니다. 이런 부분을 매꿔주기 위해 Stride에서 1을 뺀 2 만큼 zero-padding 처리를 해주는 것이죠.
Convolutional Feed-Forward
Transformer는 기본적으로 sequence한 데이터를 처리하는 모델로 vision에 적용할 때 해당 patch들의 공간정보를 추가해주어야 하는 특징이 있습니다. 기존에는 정해진 size의 position encoding을 통해 단순히 position embedding을 더해주어 모델이 위치정보를 학습할 수 있도록 수행되었습니다.
하지만 본 논문에서는 위와 같은 position embedding을 더해주는 것을 제거한 후 이 위치정보를 학습하기 위해 feed-forward networks에 Depth-wise convolution을 추가합니다.
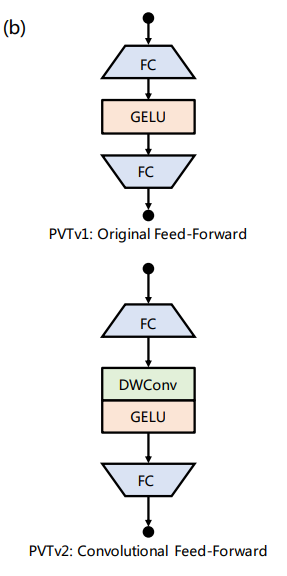
위와 같이 2개의 FC-layer 사이에 activation function인 GELU가 수행되기 전 DWConv를 수행하여 position encoding을 대체한다고 합니다. 참고로 DWConv는 3x3의 kernel로 수행되며 1의 padding을 적용하여 수행됩니다. 이렇게 단순히 position embedding을 더해주는 것 보다 DWConv를 사용하여 위치 정보를 직접 학습하는 것이 더 효과적이라고 합니다.
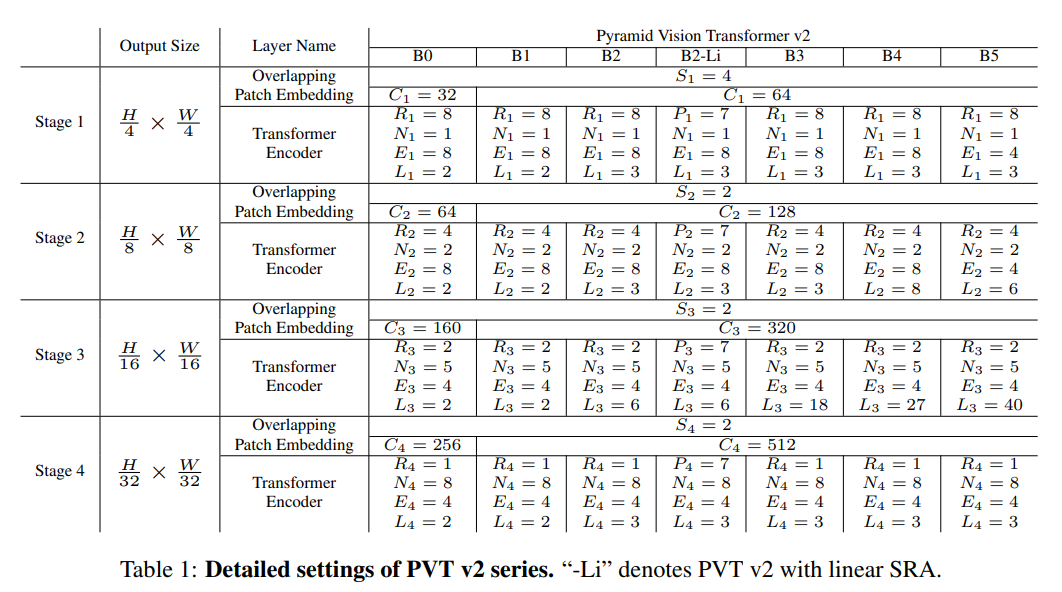
PVT v2 Series
PVT v2는 다음과 같은 hyper parameter를 가집니다.

위 hyper parameter를 조절하여 총 6개(B0 ~ B5) 의 PVT v2 series를 구성했습니다.